










































































































































































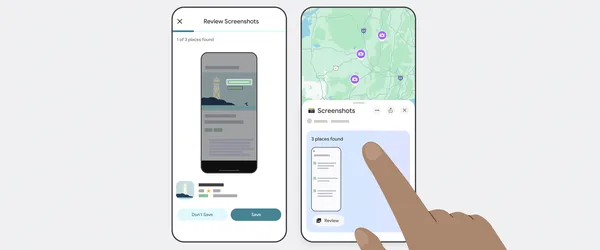
![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)




















































































































































































































































































































































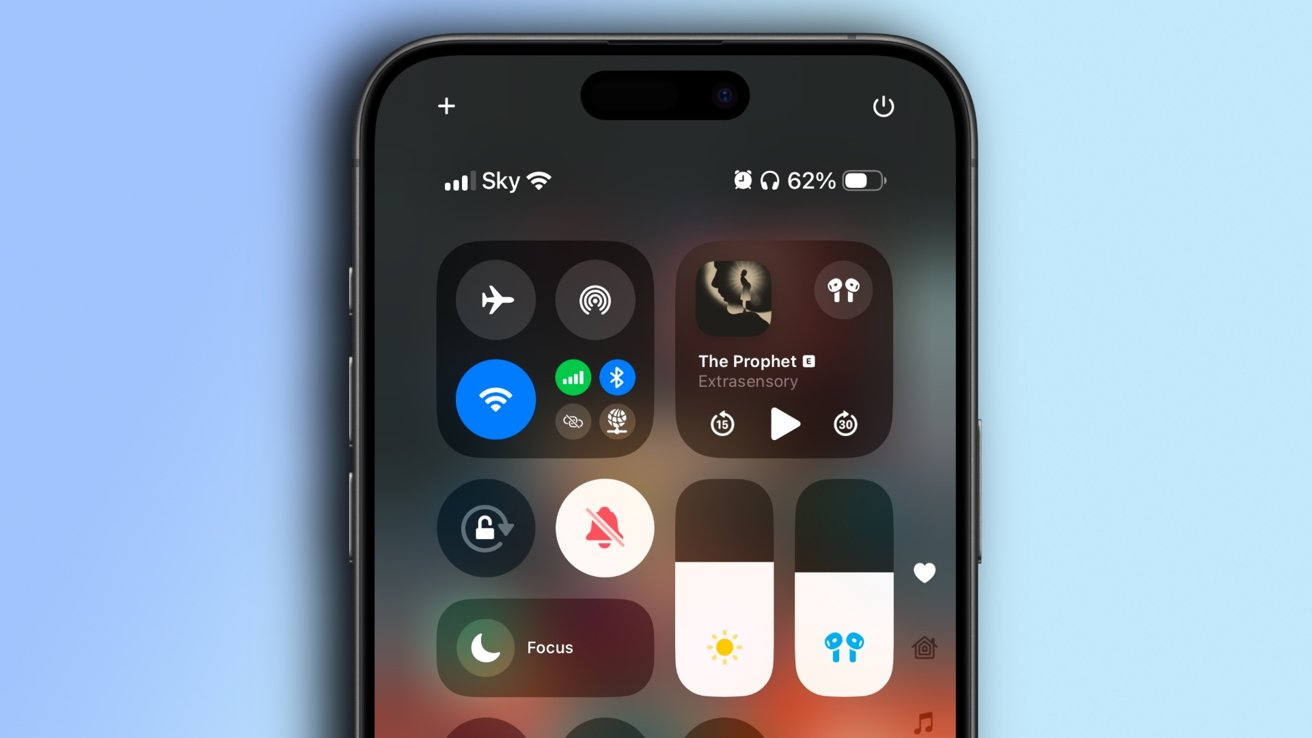



























![Beats Studio Pro Wireless Headphones Now Just $169.95 - Save 51%! [Deal]](https://www.iclarified.com/images/news/97258/97258/97258-640.jpg)






























































































Diving into Tree-Sitter: Parsing Code with Python Like a Pro
Hi there! I'm Shrijith Venkatrama, founder of Hexmos. Right now, I’m building LiveAPI, a first of its kind tool for helping you automatically index API endpoints across all your repositories. LiveAPI helps you discover, understand and use APIs in large tech infrastructures with ease. Tree-Sitter is a powerful parsing library that lets you analyze and manipulate code like a seasoned compiler engineer. Its Python bindings, available via the tree-sitter package, make it accessible for developers to experiment with syntax trees, traverse code structures, and even build tools like linters or formatters. This post dives deep into using Tree-Sitter’s Python APIs, with practical examples to get you started. We’ll cover everything from setup to advanced features like pattern matching, with complete code snippets you can run. Let’s explore how to harness Tree-Sitter to parse Python code (or any language) effectively. Why Tree-Sitter? A Quick Intro Tree-Sitter generates syntax trees that represent code structure in a detailed, language-agnostic way. Unlike traditional regex-based parsing, it understands the grammar of languages like Python, JavaScript, or C, making it ideal for tools needing precise code analysis. The Python bindings let you tap into this power with minimal setup. Key benefits: Fast, incremental parsing for real-time applications. Robust syntax trees that handle complex code. Support for many languages via precompiled bindings. Ready to dive in? Let’s set it up. Setting Up Tree-Sitter in Python To start, you need the tree-sitter package and a language-specific grammar. We’ll use Python as our example. Install the core package and the Python language grammar: pip install tree-sitter tree-sitter-python Now, load the Python language into your script: import tree_sitter_python as tspython from tree_sitter import Language, Parser # Initialize the Python language PY_LANGUAGE = Language(tspython.language()) # Create a parser parser = Parser(PY_LANGUAGE) This code sets up a parser for Python code. The tree-sitter-python package provides a precompiled grammar, so no manual compilation is needed. If you’re targeting another language, check for its grammar package on Tree-Sitter Wiki. Parsing Your First Code Snippet Let’s parse a simple Python function to see Tree-Sitter in action. The parser takes a bytes object (UTF-8 encoded) and returns a syntax tree. from tree_sitter import Parser import tree_sitter_python as tspython # Setup PY_LANGUAGE = Language(tspython.language()) parser = Parser(PY_LANGUAGE) # Code to parse code = """ def greet(): print("Hello, Tree-Sitter!") """ # Parse the code tree = parser.parse(bytes(code, "utf8")) # Inspect the root node root_node = tree.root_node print(f"Root node type: {root_node.type}") # Output: module print(f"Root node text: {root_node.text.decode('utf8')}") # Output: entire code What’s happening: The parser.parse method converts the code into a Tree object. The root_node is the top-level node (type module for Python files). You can access node properties like type, text, start_point, and end_point. This creates a syntax tree you can inspect or manipulate. Let’s explore the tree’s structure next. Navigating the Syntax Tree A syntax tree is a hierarchy of nodes, each representing a code construct (e.g., function, if statement). You can inspect nodes to understand their types and relationships. Here’s how to explore the tree from the previous example: from tree_sitter import Parser import tree_sitter_python as tspython # Setup PY_LANGUAGE = Language(tspython.language()) parser = Parser(PY_LANGUAGE) # Code to parse code = """ def greet(): print("Hello, Tree-Sitter!") """ # Parse tree = parser.parse(bytes(code, "utf8")) root_node = tree.root_node # Inspect nodes function_node = root_node.children[0] print(f"First child type: {function_node.type}") # Output: function_definition name_node = function_node.child_by_field_name("name") print(f"Function name: {name_node.text.decode('utf8')}") # Output: greet body_node = function_node.child_by_field_name("body") print(f"Body type: {body_node.type}") # Output: block call_node = body_node.children[0].children[0] print(f"Call function: {call_node.child_by_field_name('function').text.decode('utf8')}") # Output: print Key points: Use children to access child nodes or child_by_field_name for named fields like name or body. Nodes have properties like text (source code snippet), type, and position (start_point, end_point). This approach is great for small trees but can be tedious for large ones. Let’s try a more efficient method next. Walking Trees Efficiently with TreeCursor For large trees, use a TreeCursor to traverse nodes systematically. It’s like a pointer that moves through the tree, accessing children, siblings, or parents. Here’s an example that walks the tree and prints node types: from tree_

Hi there! I'm Shrijith Venkatrama, founder of Hexmos. Right now, I’m building LiveAPI, a first of its kind tool for helping you automatically index API endpoints across all your repositories. LiveAPI helps you discover, understand and use APIs in large tech infrastructures with ease.
Tree-Sitter is a powerful parsing library that lets you analyze and manipulate code like a seasoned compiler engineer. Its Python bindings, available via the tree-sitter package, make it accessible for developers to experiment with syntax trees, traverse code structures, and even build tools like linters or formatters. This post dives deep into using Tree-Sitter’s Python APIs, with practical examples to get you started.
We’ll cover everything from setup to advanced features like pattern matching, with complete code snippets you can run. Let’s explore how to harness Tree-Sitter to parse Python code (or any language) effectively.
Why Tree-Sitter? A Quick Intro
Tree-Sitter generates syntax trees that represent code structure in a detailed, language-agnostic way. Unlike traditional regex-based parsing, it understands the grammar of languages like Python, JavaScript, or C, making it ideal for tools needing precise code analysis. The Python bindings let you tap into this power with minimal setup.
Key benefits:
- Fast, incremental parsing for real-time applications.
- Robust syntax trees that handle complex code.
- Support for many languages via precompiled bindings.
Ready to dive in? Let’s set it up.
Setting Up Tree-Sitter in Python
To start, you need the tree-sitter package and a language-specific grammar. We’ll use Python as our example.
Install the core package and the Python language grammar:
pip install tree-sitter tree-sitter-python
Now, load the Python language into your script:
import tree_sitter_python as tspython
from tree_sitter import Language, Parser
# Initialize the Python language
PY_LANGUAGE = Language(tspython.language())
# Create a parser
parser = Parser(PY_LANGUAGE)
This code sets up a parser for Python code. The tree-sitter-python package provides a precompiled grammar, so no manual compilation is needed. If you’re targeting another language, check for its grammar package on Tree-Sitter Wiki.
Parsing Your First Code Snippet
Let’s parse a simple Python function to see Tree-Sitter in action. The parser takes a bytes object (UTF-8 encoded) and returns a syntax tree.
from tree_sitter import Parser
import tree_sitter_python as tspython
# Setup
PY_LANGUAGE = Language(tspython.language())
parser = Parser(PY_LANGUAGE)
# Code to parse
code = """
def greet():
print("Hello, Tree-Sitter!")
"""
# Parse the code
tree = parser.parse(bytes(code, "utf8"))
# Inspect the root node
root_node = tree.root_node
print(f"Root node type: {root_node.type}") # Output: module
print(f"Root node text: {root_node.text.decode('utf8')}") # Output: entire code
What’s happening:
- The
parser.parsemethod converts the code into aTreeobject. - The
root_nodeis the top-level node (typemodulefor Python files). - You can access node properties like
type,text,start_point, andend_point.
This creates a syntax tree you can inspect or manipulate. Let’s explore the tree’s structure next.
Navigating the Syntax Tree
A syntax tree is a hierarchy of nodes, each representing a code construct (e.g., function, if statement). You can inspect nodes to understand their types and relationships.
Here’s how to explore the tree from the previous example:
from tree_sitter import Parser
import tree_sitter_python as tspython
# Setup
PY_LANGUAGE = Language(tspython.language())
parser = Parser(PY_LANGUAGE)
# Code to parse
code = """
def greet():
print("Hello, Tree-Sitter!")
"""
# Parse
tree = parser.parse(bytes(code, "utf8"))
root_node = tree.root_node
# Inspect nodes
function_node = root_node.children[0]
print(f"First child type: {function_node.type}") # Output: function_definition
name_node = function_node.child_by_field_name("name")
print(f"Function name: {name_node.text.decode('utf8')}") # Output: greet
body_node = function_node.child_by_field_name("body")
print(f"Body type: {body_node.type}") # Output: block
call_node = body_node.children[0].children[0]
print(f"Call function: {call_node.child_by_field_name('function').text.decode('utf8')}") # Output: print
Key points:
- Use
childrento access child nodes orchild_by_field_namefor named fields likenameorbody. - Nodes have properties like
text(source code snippet),type, and position (start_point,end_point). - This approach is great for small trees but can be tedious for large ones. Let’s try a more efficient method next.
Walking Trees Efficiently with TreeCursor
For large trees, use a TreeCursor to traverse nodes systematically. It’s like a pointer that moves through the tree, accessing children, siblings, or parents.
Here’s an example that walks the tree and prints node types:
from tree_sitter import Parser
import tree_sitter_python as tspython
# Setup
PY_LANGUAGE = Language(tspython.language())
parser = Parser(PY_LANGUAGE)
# Code to parse
code = """
def greet():
print("Hello, Tree-Sitter!")
"""
# Parse
tree = parser.parse(bytes(code, "utf8"))
# Walk the tree
cursor = tree.walk()
print(f"Starting node: {cursor.node.type}") # Output: module
# Move to first child
cursor.goto_first_child()
print(f"First child: {cursor.node.type}") # Output: function_definition
# Move to function name
cursor.goto_first_child() # def
cursor.goto_next_sibling() # identifier (greet)
print(f"Function name: {cursor.node.text.decode('utf8')}") # Output: greet
# Back to parent
cursor.goto_parent()
print(f"Back to: {cursor.node.type}") # Output: function_definition
Why use TreeCursor:
- Efficient: Avoids manual child iteration.
- Flexible: Navigate up, down, or sideways in the tree.
- Limited to the subtree of the starting node, so start at
tree.root_nodefor full access.
For a deeper dive, check Tree-Sitter’s walk_tree example.
Editing Code and Updating Trees
Tree-Sitter supports incremental parsing, which is crucial for tools like editors that need to update syntax trees as code changes. You can edit a tree and reparse only the modified parts.
Here’s an example that modifies a function name:
from tree_sitter import Parser
import tree_sitter_python as tspython
# Setup
PY_LANGUAGE = Language(tspython.language())
parser = Parser(PY_LANGUAGE)
# Original code
code = bytes("""
def greet():
print("Hello!")
""", "utf8")
# Parse
tree = parser.parse(code)
# Modify code (change 'greet' to 'WELCOME')
new_code = code[:5] + b"WELCOME" + code[10:]
# Update tree
tree.edit(
start_byte=5,
old_end_byte=10,
new_end_byte=12,
start_point=(1, 4),
old_end_point=(1, 9),
new_end_point=(1, 11),
)
# Reparse with old tree
new_tree = parser.parse(new_code, tree)
# Check changed ranges
for changed_range in tree.changed_ranges(new_tree):
print(f"Changed range: {changed_range.start_point} to {changed_range.end_point}")
# Output: Changed range: (1, 4) to (1, 11)
# Verify new function name
function_name = new_tree.root_node.children[0].child_by_field_name("name")
print(f"New function name: {function_name.text.decode('utf8')}") # Output: WELCOME
How it works:
-
tree.editinforms Tree-Sitter about the change (byte offsets and line/column positions). - Reparsing with the old tree reuses unchanged parts, making it fast.
-
changed_rangesidentifies modified regions, useful for updating UI or analysis.
Pattern Matching with Queries
Tree-Sitter’s query system lets you search syntax trees for specific patterns, like finding all function definitions or function calls. Queries use a Lisp-like syntax to match node types and capture them for processing.
Here’s an example that finds function definitions and calls:
from tree_sitter import Parser, Language
import tree_sitter_python as tspython
# Setup
PY_LANGUAGE = Language(tspython.language())
parser = Parser(PY_LANGUAGE)
# Code to parse
code = """
def greet():
print("Hello!")
"""
# Parse
tree = parser.parse(bytes(code, "utf8"))
# Define query
query = PY_LANGUAGE.query("""
(function_definition
name: (identifier) @function.def
body: (block) @function.block)
(call
function: (identifier) @function.call
arguments: (argument_list) @function.args)
""")
# Get captures
captures = query.captures(tree.root_node)
for name, nodes in captures.items():
for node in nodes:
print(f"Capture {name}: {node.text.decode('utf8')}")
# Output:
# Capture function.def: greet
# Capture function.block: print("Hello!")
# Capture function.call: print
# Capture function.args: ("Hello!")
Query breakdown:
-
(function_definition ...)matches function definitions, capturing the name (@function.def) and body (@function.block). -
(call ...)matches function calls, capturing the function name (@function.call) and arguments (@function.args). -
capturesreturns a dictionary of capture names to nodes.
Queries are powerful for tools like code search or refactoring. Learn more in Tree-Sitter’s query docs.
Practical Tips and Next Steps
Tree-Sitter’s Python APIs open up a world of possibilities for code analysis and tooling. Here are some practical tips to keep going:
| Task | How to Approach | Use Case |
|---|---|---|
| Build a linter | Use queries to find patterns (e.g., unused variables) | Enforce coding standards |
| Create a formatter | Edit trees and regenerate code | Standardize code style |
| Analyze codebases | Walk trees to collect metrics (e.g., function complexity) | Generate reports |
| Support multiple languages | Load different grammars (e.g., tree-sitter-javascript) |
Cross-language tools |
Where to go next:
- Experiment with other languages by installing their grammars (e.g.,
pip install tree-sitter-javascript). - Explore incremental parsing for real-time applications like IDE plugins.
- Check out Tree-Sitter’s GitHub for more examples and issues.
By combining parsing, tree walking, editing, and queries, you can build powerful tools tailored to your needs. Start small with the examples here, and you’ll be parsing code like a pro in no time.


