![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)































































































































![Ditching a Microsoft Job to Enter Startup Purgatory with Lonewolf Engineer Sam Crombie [Podcast #171]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746753508177/0cd57f66-fdb0-4972-b285-1443a7db39fc.png?#)










































































































































































































































![[Fixed] Gemini 2.5 Flash missing file upload for free app users](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/03/google-gemini-workspace-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)


![As Galaxy Watch prepares a major change, which smartwatch design to you prefer? [Poll]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/07/Galaxy-Watch-Ultra-and-Apple-Watch-Ultra-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)











![Apple M4 MacBook Air Hits New All-Time Low of $824 [Deal]](https://www.iclarified.com/images/news/97288/97288/97288-640.jpg)
![An Apple Product Renaissance Is on the Way [Gurman]](https://www.iclarified.com/images/news/97286/97286/97286-640.jpg)
![Apple to Sync Captive Wi-Fi Logins Across iPhone, iPad, and Mac [Report]](https://www.iclarified.com/images/news/97284/97284/97284-640.jpg)
![Apple M4 iMac Drops to New All-Time Low Price of $1059 [Deal]](https://www.iclarified.com/images/news/97281/97281/97281-640.jpg)








































![Apple's 11th Gen iPad Drops to New Low Price of $277.78 on Amazon [Updated]](https://images.macrumors.com/t/yQCVe42SNCzUyF04yj1XYLHG5FM=/2500x/article-new/2025/03/11th-gen-ipad-orange.jpeg)



















































Connecting RDBs and Search Engines — Chapter 5
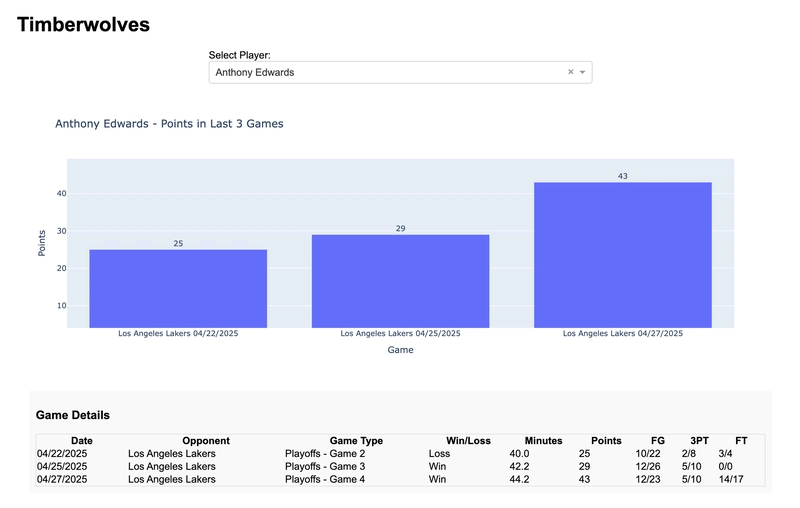
Chapter 5: Implementing a CDC Join Pipeline with Flink SQL In this chapter, we build a full pipeline that captures CDC streams from PostgreSQL via Debezium, joins the data using Flink SQL, and stores the results in OpenSearch. Architecture Overview PostgreSQL ↓ (CDC) Debezium (Kafka Connect) ↓ (debezium-json) Kafka Topic (orders, products) ↓ Flink SQL ↓ OpenSearch (orders_with_products) PostgreSQL Table Setup Add the following to postgres/01-init.sql: -- Products table CREATE TABLE products ( product_id VARCHAR(32) PRIMARY KEY, product_name VARCHAR(255), category_id VARCHAR(32) ); ALTER TABLE products REPLICA IDENTITY FULL; -- Initial product data INSERT INTO products (product_id, product_name, category_id) VALUES ('P001', 'Sneaker X', 'C001'), ('P002', 'Jacket Y', 'C002'); -- Orders table CREATE TABLE orders ( order_id VARCHAR(32) PRIMARY KEY, order_time TIMESTAMP, customer_id VARCHAR(32), product_id VARCHAR(32), quantity INT, price NUMERIC(10,2) ); ALTER TABLE orders REPLICA IDENTITY FULL; -- Initial order data INSERT INTO orders (order_id, order_time, customer_id, product_id, quantity, price) VALUES ('O1001', '2025-04-27 10:00:00', 'CUST01', 'P001', 1, 9800.00), ('O1002', '2025-04-27 10:05:00', 'CUST02', 'P002', 2, 15800.00); -- Grant permissions to Debezium user GRANT SELECT ON products, orders TO debezium; -- Add tables to existing publication ALTER PUBLICATION debezium_pub ADD TABLE products, orders; Register Debezium Connector After Kafka Connect is running, register the connector using a script such as scripts/02-debezium-table-table-join.sh. Ensure the config includes: "table.include.list": "public.testtable,public.products,public.orders" Create OpenSearch Index Prepare opensearch/orders_with_products-mapping.json: { "mappings": { "properties": { "order_id": { "type": "keyword" }, "product_id": { "type": "keyword" }, "product_name": { "type": "text", "fields": { "raw": { "type": "keyword" } } }, "category_id": { "type": "keyword" }, "quantity": { "type": "integer" }, "price": { "type": "double" } } } } Create the index: curl -X PUT "http://localhost:9200/orders_with_products" \ -H "Content-Type: application/json" \ -d @opensearch/orders_with_products-mapping.json ✅ product_name uses a multi-field (text + keyword) for full-text and exact match support. Example Flink SQL Create flink/sql/table-table-join.sql: -- Products table CREATE TABLE products ( product_id STRING, product_name STRING, category_id STRING, PRIMARY KEY (product_id) NOT ENFORCED ) WITH ( 'connector' = 'kafka', 'topic' = 'dbserver1.public.products', 'properties.bootstrap.servers' = 'kafka:9092', 'format' = 'debezium-json', 'scan.startup.mode' = 'earliest-offset' ); -- Orders table CREATE TABLE orders ( order_id STRING, order_time STRING, customer_id STRING, product_id STRING, quantity INT, price DOUBLE ) WITH ( 'connector' = 'kafka', 'topic' = 'dbserver1.public.orders', 'properties.bootstrap.servers' = 'kafka:9092', 'format' = 'debezium-json', 'scan.startup.mode' = 'earliest-offset' ); -- OpenSearch Sink CREATE TABLE orders_with_products ( order_id STRING, product_id STRING, product_name STRING, category_id STRING, quantity INT, price DOUBLE, PRIMARY KEY (order_id, product_id) NOT ENFORCED ) WITH ( 'connector' = 'opensearch-2', 'hosts' = 'http://opensearch:9200', 'allow-insecure' = 'true', 'index' = 'orders_with_products', 'document-id.key-delimiter' = '$', 'sink.bulk-flush.max-size' = '1mb' ); -- Join View CREATE VIEW orders_with_products_view AS SELECT o.order_id, o.product_id, p.product_name, p.category_id, o.quantity, o.price FROM orders o INNER JOIN products p ON o.product_id = p.product_id; -- Insert into OpenSearch INSERT INTO orders_with_products SELECT * FROM orders_with_products_view; Run the Flink Job Execute from inside the Flink container: sql-client.sh -f /opt/flink/sql/table-table-join.sql Or via Docker: docker compose exec flink-jobmanager sql-client.sh -f /opt/flink/sql/table-table-join.sql Validation Steps Verify CDC data in Kafka topics: docker compose exec kafka kafka-console-consumer --bootstrap-server localhost:9092 --topic dbserver1.public.orders --from-beginning docker compose exec kafka kafka-console-consumer --bootstrap-server localhost:9092 --topic dbserver1.public.products --from-beginning Verify data in OpenSearch: curl -X GET "http://localhost:9200/orders_with_products/_search?pretty" With custom query: curl -s -X GET "http://localhost:9200/orders_with_products/_search?pretty" \ -H 'Content-Type: application/json' \ -d '{ "query": { "match_all": {} } }' For convenience, use a script like scripts/opensearch-query.sh: #!

Chapter 5: Implementing a CDC Join Pipeline with Flink SQL
In this chapter, we build a full pipeline that captures CDC streams from PostgreSQL via Debezium, joins the data using Flink SQL, and stores the results in OpenSearch.
Architecture Overview
PostgreSQL
↓ (CDC)
Debezium (Kafka Connect)
↓ (debezium-json)
Kafka Topic (orders, products)
↓
Flink SQL
↓
OpenSearch (orders_with_products)
PostgreSQL Table Setup
Add the following to postgres/01-init.sql:
-- Products table
CREATE TABLE products (
product_id VARCHAR(32) PRIMARY KEY,
product_name VARCHAR(255),
category_id VARCHAR(32)
);
ALTER TABLE products REPLICA IDENTITY FULL;
-- Initial product data
INSERT INTO products (product_id, product_name, category_id) VALUES
('P001', 'Sneaker X', 'C001'),
('P002', 'Jacket Y', 'C002');
-- Orders table
CREATE TABLE orders (
order_id VARCHAR(32) PRIMARY KEY,
order_time TIMESTAMP,
customer_id VARCHAR(32),
product_id VARCHAR(32),
quantity INT,
price NUMERIC(10,2)
);
ALTER TABLE orders REPLICA IDENTITY FULL;
-- Initial order data
INSERT INTO orders (order_id, order_time, customer_id, product_id, quantity, price) VALUES
('O1001', '2025-04-27 10:00:00', 'CUST01', 'P001', 1, 9800.00),
('O1002', '2025-04-27 10:05:00', 'CUST02', 'P002', 2, 15800.00);
-- Grant permissions to Debezium user
GRANT SELECT ON products, orders TO debezium;
-- Add tables to existing publication
ALTER PUBLICATION debezium_pub ADD TABLE products, orders;
Register Debezium Connector
After Kafka Connect is running, register the connector using a script such as scripts/02-debezium-table-table-join.sh. Ensure the config includes:
"table.include.list": "public.testtable,public.products,public.orders"
Create OpenSearch Index
Prepare opensearch/orders_with_products-mapping.json:
{
"mappings": {
"properties": {
"order_id": { "type": "keyword" },
"product_id": { "type": "keyword" },
"product_name": {
"type": "text",
"fields": { "raw": { "type": "keyword" } }
},
"category_id": { "type": "keyword" },
"quantity": { "type": "integer" },
"price": { "type": "double" }
}
}
}
Create the index:
curl -X PUT "http://localhost:9200/orders_with_products" \
-H "Content-Type: application/json" \
-d @opensearch/orders_with_products-mapping.json
✅
product_nameuses a multi-field (text + keyword) for full-text and exact match support.
Example Flink SQL
Create flink/sql/table-table-join.sql:
-- Products table
CREATE TABLE products (
product_id STRING,
product_name STRING,
category_id STRING,
PRIMARY KEY (product_id) NOT ENFORCED
) WITH (
'connector' = 'kafka',
'topic' = 'dbserver1.public.products',
'properties.bootstrap.servers' = 'kafka:9092',
'format' = 'debezium-json',
'scan.startup.mode' = 'earliest-offset'
);
-- Orders table
CREATE TABLE orders (
order_id STRING,
order_time STRING,
customer_id STRING,
product_id STRING,
quantity INT,
price DOUBLE
) WITH (
'connector' = 'kafka',
'topic' = 'dbserver1.public.orders',
'properties.bootstrap.servers' = 'kafka:9092',
'format' = 'debezium-json',
'scan.startup.mode' = 'earliest-offset'
);
-- OpenSearch Sink
CREATE TABLE orders_with_products (
order_id STRING,
product_id STRING,
product_name STRING,
category_id STRING,
quantity INT,
price DOUBLE,
PRIMARY KEY (order_id, product_id) NOT ENFORCED
) WITH (
'connector' = 'opensearch-2',
'hosts' = 'http://opensearch:9200',
'allow-insecure' = 'true',
'index' = 'orders_with_products',
'document-id.key-delimiter' = '$',
'sink.bulk-flush.max-size' = '1mb'
);
-- Join View
CREATE VIEW orders_with_products_view AS
SELECT
o.order_id,
o.product_id,
p.product_name,
p.category_id,
o.quantity,
o.price
FROM orders o
INNER JOIN products p ON o.product_id = p.product_id;
-- Insert into OpenSearch
INSERT INTO orders_with_products
SELECT * FROM orders_with_products_view;
Run the Flink Job
Execute from inside the Flink container:
sql-client.sh -f /opt/flink/sql/table-table-join.sql
Or via Docker:
docker compose exec flink-jobmanager sql-client.sh -f /opt/flink/sql/table-table-join.sql
Validation Steps
- Verify CDC data in Kafka topics:
docker compose exec kafka kafka-console-consumer --bootstrap-server localhost:9092 --topic dbserver1.public.orders --from-beginning
docker compose exec kafka kafka-console-consumer --bootstrap-server localhost:9092 --topic dbserver1.public.products --from-beginning
- Verify data in OpenSearch:
curl -X GET "http://localhost:9200/orders_with_products/_search?pretty"
With custom query:
curl -s -X GET "http://localhost:9200/orders_with_products/_search?pretty" \
-H 'Content-Type: application/json' \
-d '{ "query": { "match_all": {} } }'
For convenience, use a script like scripts/opensearch-query.sh:
#!/bin/bash
osq() {
local index="${1:-_all}"
local size="${2:-10}"
curl -s -X GET "http://localhost:9200/${index}/_search?pretty" \
-H 'Content-Type: application/json' \
-d "{\"query\": { \"match_all\": {} }, \"size\": ${size} }"
}
Example usage:
source scripts/opensearch-query.sh
osq orders_with_products
osq orders_with_products 20
osq orders_with_products 100 | jq '.hits.hits[]._id'
In Chapter 6 and beyond, we will explore topics such as deduplication, batch processing, DLQ (Dead Letter Queue), and OpenSearch index partitioning strategies for production-grade pipelines.