













































































































































































![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)
















































































































![✨ [24] -](https://media2.dev.to/dynamic/image/width%3D1000,height%3D500,fit%3Dcover,gravity%3Dauto,format%3Dauto/https:%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2Fv4oak8f7012ul5b36wiz.png)















![Ditching a Microsoft Job to Enter Startup Purgatory with Lonewolf Engineer Sam Crombie [Podcast #171]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746753508177/0cd57f66-fdb0-4972-b285-1443a7db39fc.png?#)











































































































































































































































![[Fixed] Gemini 2.5 Flash missing file upload for free app users](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/03/google-gemini-workspace-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)


![As Galaxy Watch prepares a major change, which smartwatch design to you prefer? [Poll]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/07/Galaxy-Watch-Ultra-and-Apple-Watch-Ultra-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)












![Apple Shares 'Last Scene' Short Film Shot on iPhone 16 Pro [Video]](https://www.iclarified.com/images/news/97289/97289/97289-640.jpg)
![Apple M4 MacBook Air Hits New All-Time Low of $824 [Deal]](https://www.iclarified.com/images/news/97288/97288/97288-640.jpg)
![An Apple Product Renaissance Is on the Way [Gurman]](https://www.iclarified.com/images/news/97286/97286/97286-640.jpg)
![Apple to Sync Captive Wi-Fi Logins Across iPhone, iPad, and Mac [Report]](https://www.iclarified.com/images/news/97284/97284/97284-640.jpg)







































![Apple's 11th Gen iPad Drops to New Low Price of $277.78 on Amazon [Updated]](https://images.macrumors.com/t/yQCVe42SNCzUyF04yj1XYLHG5FM=/2500x/article-new/2025/03/11th-gen-ipad-orange.jpeg)
















































Connecting RDBs and Search Engines — Chapter 2
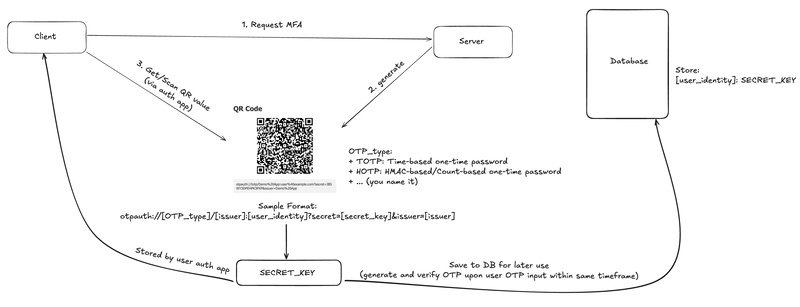
Chapter 2: Understanding the Architecture and Component Relationships Below is a diagram representing the architecture discussed in this chapter: graph TD subgraph Source PG[PostgreSQL] end subgraph Change Data Capture Connect[Debezium Connect] end subgraph Stream Platform ZK[ZooKeeper] --> K[Kafka] end subgraph Stream Processing subgraph Flink JM[JobManager] --> TM[TaskManager] end end subgraph Sink OS[OpenSearch] end PG --> Connect --> K --> TM --> OS This chapter explains how each component interacts to enable real-time data flow into the search engine. PostgreSQL PostgreSQL serves as the relational database and source of change data. Initial data is inserted via 00-init.sql, and subsequent changes (INSERT, UPDATE, DELETE) are detected by Debezium. Debezium leverages PostgreSQL's WAL (Write-Ahead Log) to capture changes. WAL is a transaction log that records all data modifications before they're applied to the actual tables. By reading the WAL, changes can be captured without impacting application logic. Debezium Connect Debezium operates as a connector on top of the Kafka Connect framework. Kafka Connect simplifies data integration with Kafka through reusable connectors. These connectors can be registered and managed via Kafka Connect's REST API (covered in the next chapter). In this setup, the Debezium PostgreSQL connector reads from WAL and emits change events to Kafka. Kafka + ZooKeeper Kafka is a high-throughput messaging system used for processing and relaying real-time data. Debezium publishes change events to Kafka topics, which are then consumed by Flink or other downstream systems. Kafka manages data by topics. Each consumer subscribes to one or more topics to receive data streams. In this case, Flink uses the topic as a streaming source. Topic design is a crucial part of data modeling in streaming systems. ZooKeeper assists Kafka by managing configuration and cluster state. In this setup, we use a single-node ZooKeeper for simplicity. Flink JobManager / TaskManager Flink is a distributed stream processing engine developed under the Apache project. It supports both real-time and batch processing with low latency and high throughput. Flink jobs consume data from Kafka, perform transformations, and output it to OpenSearch. JobManager handles job orchestration, while TaskManager executes tasks in parallel. OpenSearch OpenSearch is an open-source search and analytics engine based on Elasticsearch. It can store structured and semi-structured data, and provides fast full-text search and aggregation capabilities. Data is stored in indexes, similar to tables in relational databases. Each index holds multiple documents, which represent individual records. Stored data can be queried and visualized using tools like OpenSearch Dashboards. Explanation There are two main reasons behind this architecture. Let’s examine them: Normalized Data vs. Search Performance Some may wonder: “Why not query PostgreSQL directly? Isn’t OpenSearch redundant?” This architecture deliberately separates the source and the search engine because of differing performance and design goals. Relational databases like PostgreSQL often use normalized data models to ensure consistency and avoid redundancy. While beneficial for updates, these models require joins across multiple tables, which can slow down search queries. In contrast, OpenSearch allows data to be denormalized and restructured for optimal search performance. This avoids costly joins and improves response times. Thus, by separating the update-optimized PostgreSQL from the search-optimized OpenSearch, and managing the transformation in between, the overall system becomes more efficient. The Value of Real-Time Stream Processing In this architecture, PostgreSQL ensures consistency, while OpenSearch provides high-performance search over transformed data. The pipeline—Debezium detecting changes, Kafka transporting them, Flink transforming them, and OpenSearch indexing them—enables real-time propagation of updates. The benefits of this streaming approach include: Real-time responsiveness: Unlike batch jobs, changes propagate immediately, allowing up-to-date search results. Asynchronous replication: Changes can be replicated without impacting application/database performance. Flexible transformation: Flink enables complex filtering, joins, and aggregations tailored to search use cases. Change Data Capture (CDC) with stream processing is a key design pattern in modern data infrastructure. In the next chapter, we'll create tables in PostgreSQL, generate changes, and observe how events are streamed to Kafka topics. (Coming soon: Chapter 3 — Verifying the Flow from PostgreSQL to Debezium to Kafka)

Chapter 2: Understanding the Architecture and Component Relationships
Below is a diagram representing the architecture discussed in this chapter:
graph TD
subgraph Source
PG[PostgreSQL]
end
subgraph Change Data Capture
Connect[Debezium Connect]
end
subgraph Stream Platform
ZK[ZooKeeper] --> K[Kafka]
end
subgraph Stream Processing
subgraph Flink
JM[JobManager] --> TM[TaskManager]
end
end
subgraph Sink
OS[OpenSearch]
end
PG --> Connect --> K --> TM --> OS
This chapter explains how each component interacts to enable real-time data flow into the search engine.
PostgreSQL
PostgreSQL serves as the relational database and source of change data. Initial data is inserted via 00-init.sql, and subsequent changes (INSERT, UPDATE, DELETE) are detected by Debezium.
Debezium leverages PostgreSQL's WAL (Write-Ahead Log) to capture changes. WAL is a transaction log that records all data modifications before they're applied to the actual tables. By reading the WAL, changes can be captured without impacting application logic.
Debezium Connect
Debezium operates as a connector on top of the Kafka Connect framework. Kafka Connect simplifies data integration with Kafka through reusable connectors. These connectors can be registered and managed via Kafka Connect's REST API (covered in the next chapter).
In this setup, the Debezium PostgreSQL connector reads from WAL and emits change events to Kafka.
Kafka + ZooKeeper
Kafka is a high-throughput messaging system used for processing and relaying real-time data. Debezium publishes change events to Kafka topics, which are then consumed by Flink or other downstream systems.
Kafka manages data by topics. Each consumer subscribes to one or more topics to receive data streams. In this case, Flink uses the topic as a streaming source. Topic design is a crucial part of data modeling in streaming systems.
ZooKeeper assists Kafka by managing configuration and cluster state. In this setup, we use a single-node ZooKeeper for simplicity.
Flink JobManager / TaskManager
Flink is a distributed stream processing engine developed under the Apache project. It supports both real-time and batch processing with low latency and high throughput.
Flink jobs consume data from Kafka, perform transformations, and output it to OpenSearch.
JobManager handles job orchestration, while TaskManager executes tasks in parallel.
OpenSearch
OpenSearch is an open-source search and analytics engine based on Elasticsearch. It can store structured and semi-structured data, and provides fast full-text search and aggregation capabilities.
Data is stored in indexes, similar to tables in relational databases. Each index holds multiple documents, which represent individual records.
Stored data can be queried and visualized using tools like OpenSearch Dashboards.
Explanation
There are two main reasons behind this architecture. Let’s examine them:
Normalized Data vs. Search Performance
Some may wonder: “Why not query PostgreSQL directly? Isn’t OpenSearch redundant?”
This architecture deliberately separates the source and the search engine because of differing performance and design goals.
Relational databases like PostgreSQL often use normalized data models to ensure consistency and avoid redundancy. While beneficial for updates, these models require joins across multiple tables, which can slow down search queries.
In contrast, OpenSearch allows data to be denormalized and restructured for optimal search performance. This avoids costly joins and improves response times.
Thus, by separating the update-optimized PostgreSQL from the search-optimized OpenSearch, and managing the transformation in between, the overall system becomes more efficient.
The Value of Real-Time Stream Processing
In this architecture, PostgreSQL ensures consistency, while OpenSearch provides high-performance search over transformed data.
The pipeline—Debezium detecting changes, Kafka transporting them, Flink transforming them, and OpenSearch indexing them—enables real-time propagation of updates.
The benefits of this streaming approach include:
- Real-time responsiveness: Unlike batch jobs, changes propagate immediately, allowing up-to-date search results.
- Asynchronous replication: Changes can be replicated without impacting application/database performance.
- Flexible transformation: Flink enables complex filtering, joins, and aggregations tailored to search use cases.
Change Data Capture (CDC) with stream processing is a key design pattern in modern data infrastructure.
In the next chapter, we'll create tables in PostgreSQL, generate changes, and observe how events are streamed to Kafka topics.
(Coming soon: Chapter 3 — Verifying the Flow from PostgreSQL to Debezium to Kafka)



