




























































_.png)














































































































![[The AI Show Episode 151]: Anthropic CEO: AI Will Destroy 50% of Entry-Level Jobs, Veo 3’s Scary Lifelike Videos, Meta Aims to Fully Automate Ads & Perplexity’s Burning Cash](https://www.marketingaiinstitute.com/hubfs/ep%20151%20cover.png)






























































































































![From electrical engineering student to CTO with Hitesh Choudhary [Podcast #175]](https://cdn.hashnode.com/res/hashnode/image/upload/v1749158756824/3996a2ad-53e5-4a8f-ab97-2c77a6f66ba3.png?#)








































































































































_sleepyfellow_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)






















































































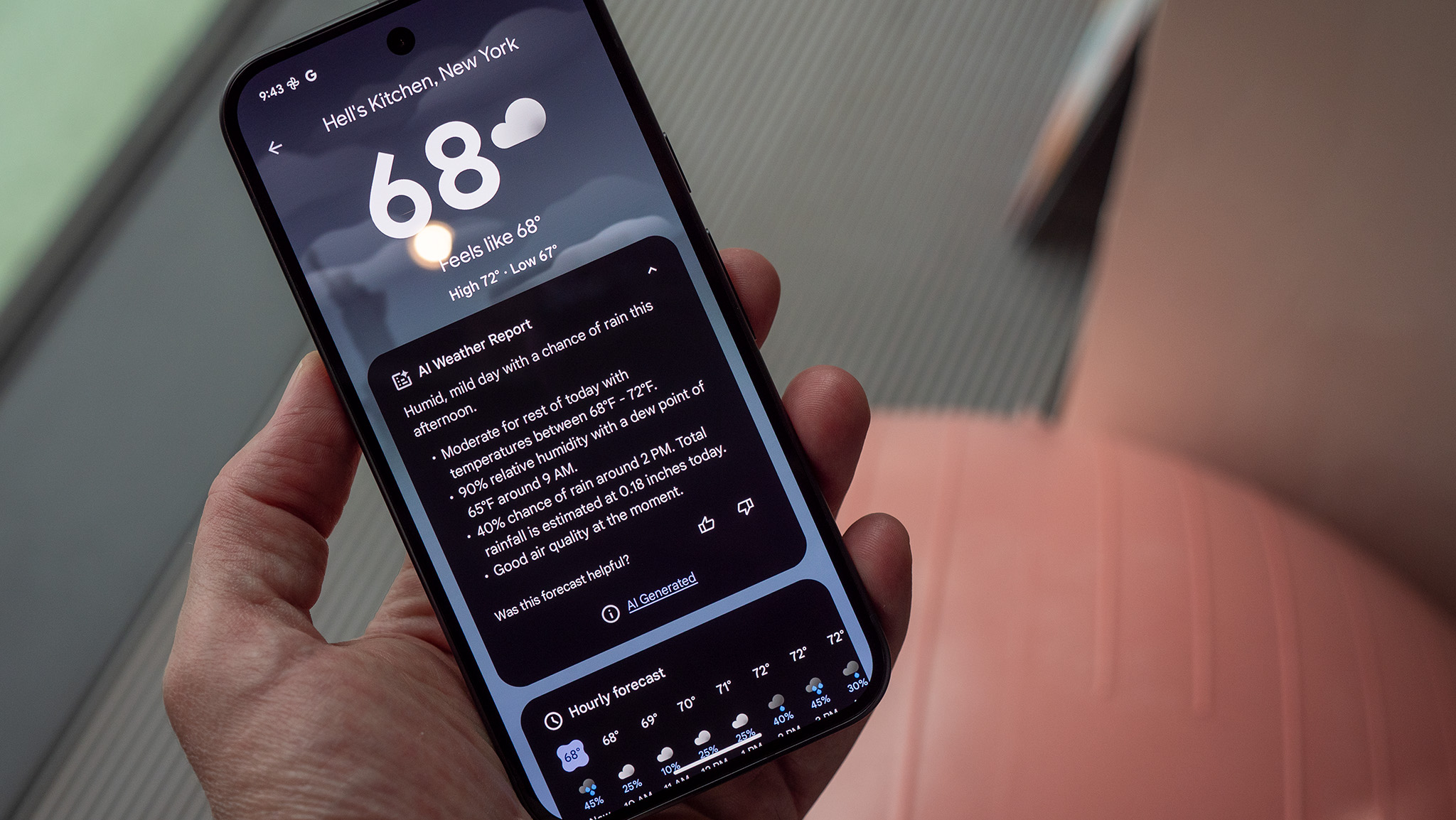

























![watchOS 26 May Bring Third-Party Widgets to Control Center [Report]](https://www.iclarified.com/images/news/97520/97520/97520-640.jpg)

![AirPods Pro 2 On Sale for $169 — Save $80! [Deal]](https://www.iclarified.com/images/news/97526/97526/97526-640.jpg)
![Apple Shares Official Trailer for 'The Wild Ones' [Video]](https://www.iclarified.com/images/news/97515/97515/97515-640.jpg)



























































Building a Multi-Agent RAG System with Couchbase, CrewAI, and Nebius AI Studio
Traditional RAG systems typically follow a linear approach: retrieve documents, generate a response, and present it to the user. While effective, this approach can lack the nuanced understanding and specialized processing that complex queries often require. In contrast, AI agents introduce a more dynamic and intelligent workflow to RAG-based operations. They can collaborate, iterate, and critique each other’s outputs, enabling deeper understanding and more coherent responses. This agent-driven approach transforms RAG from a static process into an adaptive system capable of producing higher-quality, context-aware content. In this blog post, we’ll guide you through building a powerful semantic search engine using Couchbase as the database, CrewAI for agent-based Retrieval-Augmented Generation (RAG) operations, and Nebius AI Studio for the LLM and embedding model. What is CrewAI? CrewAI is an open-source Python framework that supports developing and managing multi-agent AI systems. What sets CrewAI apart is its ability to facilitate collaborative task handling and goal-driven execution, enabling agents to work together efficiently toward shared outcomes. It incorporates iterative thinking and feedback loops, allowing agents to refine their decisions and outputs continuously. It also offers seamless communication between the agents. Building a Multi-Agent RAG System with Couchbase and CrewAI The foundation of this example is a powerful semantic search engine using Couchbase as the vector database and CrewAI for agent-based RAG operations. CrewAI allows us to create specialized agents that can work together to handle different aspects of the RAG workflow, from document retrieval to response generation. Setting Up LLM Components For this project, we chose Nebius AI Studio as our LLM and embedding provider. Nebius AI Studio is a platform that simplifies the process of building applications using AI models. It provides a suite of open-source LLM and embedding models. Extending the base OpenAI LLM For the CrewAI LLM, we replace the base_url with the Nebius AI Studio endpoint: https://api.studio.nebius.com/v1/, define the model we wish to use, and add the NEBIUS_AI_KEY API key # Define the LLM with Nebius AI Studio llm = LLM( model="openai/meta-llama/Meta-Llama-3.1-70B-Instruct", base_url="https://api.studio.nebius.com/v1/", api_key=os.getenv('NEBIUS_AI_KEY') ) Creating the NebiusEmbeddings Class LangChain doesn’t natively support Nebius’s API. To bridge this gap, we created a custom NebiusE5MistralEmbeddings class that extends LangChain’s Embeddings interface, allowing seamless integration with Nebius’s embedding model: from langchain_core.embeddings import Embeddings from typing import List import requests class NebiusEmbeddings(Embeddings): def __init__(self, api_key: str, model: str = "BAAI/bge-en-icl"): self.api_key = api_key self.model = model self.base_url = "https://api.studio.nebius.ai/v1/embeddings" def embed_documents(self, texts: List[str]) -> List[List[float]]: """Embed a list of documents using Nebius AI Studio.""" headers = { "Authorization": f"Bearer {self.api_key}", "Content-Type": "application/json" } payload = { "model": self.model, "input": texts } response = requests.post(self.base_url, json=payload, headers=headers) response.raise_for_status() data = response.json() return [item["embedding"] for item in data["data"]] def embed_query(self, text: str) -> List[float]: """Embed a single query using Nebius AI Studio.""" return self.embed_documents([text])[0] This class implements embed_documents for processing batches of text and embed_query for individual search queries, interacting directly with the Nebius API endpoint. Nebius AI Studio supports various embedding models, including BGE and E5-mistral. Setting Up the Couchbase Vector Store We initialize the Couchbase vector store and ingest the articles in batches: from langchain_couchbase.vectorstores import CouchbaseVectorStore vector_store = CouchbaseVectorStore( cluster=cluster, bucket_name=CB_BUCKET_NAME, scope_name=SCOPE_NAME, collection_name=COLLECTION_NAME, embedding=embeddings, index_name=INDEX_NAME ) batch_size = 100 articles = [article for article in unique_articles if len(article) str: """Search for relevant documents using vector similarity.""" docs = retriever.invoke(query) return "\n\n".join([f"Document {i+1}:\n{doc.page_content}" for i, doc in enumerate(docs)]) This tool: Uses the vector store’s retriever to perform similarity searches. Formats results for easy consumption by AI agents. Defining the Agents The Research Expert uses the vector store to retrieve relevant documents using the ve

Traditional RAG systems typically follow a linear approach: retrieve documents, generate a response, and present it to the user. While effective, this approach can lack the nuanced understanding and specialized processing that complex queries often require. In contrast, AI agents introduce a more dynamic and intelligent workflow to RAG-based operations. They can collaborate, iterate, and critique each other’s outputs, enabling deeper understanding and more coherent responses. This agent-driven approach transforms RAG from a static process into an adaptive system capable of producing higher-quality, context-aware content.
In this blog post, we’ll guide you through building a powerful semantic search engine using Couchbase as the database, CrewAI for agent-based Retrieval-Augmented Generation (RAG) operations, and Nebius AI Studio for the LLM and embedding model.
What is CrewAI?
CrewAI is an open-source Python framework that supports developing and managing multi-agent AI systems.
What sets CrewAI apart is its ability to facilitate collaborative task handling and goal-driven execution, enabling agents to work together efficiently toward shared outcomes. It incorporates iterative thinking and feedback loops, allowing agents to refine their decisions and outputs continuously. It also offers seamless communication between the agents.
Building a Multi-Agent RAG System with Couchbase and CrewAI
The foundation of this example is a powerful semantic search engine using Couchbase as the vector database and CrewAI for agent-based RAG operations. CrewAI allows us to create specialized agents that can work together to handle different aspects of the RAG workflow, from document retrieval to response generation.
Setting Up LLM Components
For this project, we chose Nebius AI Studio as our LLM and embedding provider. Nebius AI Studio is a platform that simplifies the process of building applications using AI models. It provides a suite of open-source LLM and embedding models.
Extending the base OpenAI LLM
For the CrewAI LLM, we replace the base_url with the Nebius AI Studio endpoint: https://api.studio.nebius.com/v1/, define the model we wish to use, and add the NEBIUS_AI_KEY API key
# Define the LLM with Nebius AI Studio
llm = LLM(
model="openai/meta-llama/Meta-Llama-3.1-70B-Instruct",
base_url="https://api.studio.nebius.com/v1/",
api_key=os.getenv('NEBIUS_AI_KEY')
)
Creating the NebiusEmbeddings Class
LangChain doesn’t natively support Nebius’s API. To bridge this gap, we created a custom NebiusE5MistralEmbeddings class that extends LangChain’s Embeddings interface, allowing seamless integration with Nebius’s embedding model:
from langchain_core.embeddings import Embeddings
from typing import List
import requests
class NebiusEmbeddings(Embeddings):
def __init__(self, api_key: str, model: str = "BAAI/bge-en-icl"):
self.api_key = api_key
self.model = model
self.base_url = "https://api.studio.nebius.ai/v1/embeddings"
def embed_documents(self, texts: List[str]) -> List[List[float]]:
"""Embed a list of documents using Nebius AI Studio."""
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
payload = {
"model": self.model,
"input": texts
}
response = requests.post(self.base_url, json=payload, headers=headers)
response.raise_for_status()
data = response.json()
return [item["embedding"] for item in data["data"]]
def embed_query(self, text: str) -> List[float]:
"""Embed a single query using Nebius AI Studio."""
return self.embed_documents([text])[0]
This class implements embed_documents for processing batches of text and embed_query for individual search queries, interacting directly with the Nebius API endpoint. Nebius AI Studio supports various embedding models, including BGE and E5-mistral.
Setting Up the Couchbase Vector Store
We initialize the Couchbase vector store and ingest the articles in batches:
from langchain_couchbase.vectorstores import CouchbaseVectorStore
vector_store = CouchbaseVectorStore(
cluster=cluster,
bucket_name=CB_BUCKET_NAME,
scope_name=SCOPE_NAME,
collection_name=COLLECTION_NAME,
embedding=embeddings,
index_name=INDEX_NAME
)
batch_size = 100
articles = [article for article in unique_articles if len(article) <= 50000]
vector_store.add_texts(texts=articles, batch_size=batch_size)
logging.info("Document ingestion completed successfully.")
Creating a Vector Search Tool with CrewAI
We create a vector search tool to allow CrewAI agents to retrieve relevant documents:
from crewai.tools import tool
retriever = vector_store.as_retriever(search_type="similarity")
@tool("vector_search")
def search_tool(query: str) -> str:
"""Search for relevant documents using vector similarity."""
docs = retriever.invoke(query)
return "\n\n".join([f"Document {i+1}:\n{doc.page_content}" for i, doc in enumerate(docs)])
This tool:
- Uses the vector store’s retriever to perform similarity searches.
- Formats results for easy consumption by AI agents.
Defining the Agents
The Research Expert uses the vector store to retrieve relevant documents using the vector_search tool. The Technical Writer agent, also powered by the same model, takes the research output and generates a well-structured, reader-friendly response.
Here’s how we set up the agents
from crewai import Agent, Task, Crew, Process
# Research Expert Agent
researcher = Agent(
role="Research Expert",
goal="Retrieve and analyze relevant information from the vector store to answer user queries accurately.",
backstory="A skilled data analyst with expertise in semantic search and information retrieval.",
tools=[search_tool],
llm=llm,
verbose=True
)
# Technical Writer Agent
writer = Agent(
role="Technical Writer",
goal="Craft clear, concise, and well-structured responses based on research findings.",
backstory="An experienced writer specializing in turning complex data into engaging narratives.",
llm=llm,
verbose=True
)
Defining Tasks
We define tasks for each agent to ensure a clear division of work:
# Research Task
research_task = Task(
description=f"Research and analyze information relevant to: {query}",
agent=researcher,
expected_output="A detailed analysis with key findings and supporting evidence"
)
# Writing Task
writing_task = Task(
description="Create a comprehensive and well-structured response",
agent=writer,
expected_output="A clear, comprehensive response that answers the query",
context=[research_task]
)
The Crew object orchestrates the agents in a sequential process, where the Research Expert completes its task before passing the output to the Technical Writer.
Running the Crew!
With agents and tasks defined, it's time to kick off the crew. To demonstrate the agent workflow, we process a sample query about the FA Cup third round draw:
def process_query(query, researcher, writer):
crew = Crew(
agents=[researcher, writer],
tasks=[research_task, writing_task],
process=Process.sequential,
verbose=True,
cache=True,
planning=True
)
return crew.kickoff(inputs={"query": query})
query = "What are the key details about the FA Cup third round draw? Include information about Manchester United vs Arsenal, Tamworth vs Tottenham, and other notable fixtures."
result = process_query(query, researcher, writer)
print(result)
This query triggers the following workflow:
- The Research Expert uses the vector_search tool to retrieve relevant BBC News articles from the Couchbase vector store, leveraging Nebius’s embeddings for semantic similarity.
- The agent analyzes the retrieved documents and generates a summary of key details, such as the historical context of Manchester United vs Arsenal and the potential for an upset in Tamworth vs Tottenham.
- The Technical Writer takes this summary and crafts a polished article.
The console output during crew.kickoff() shows each agent thinking, using tools, and passing information to the next agent,


Final Thoughts
Building a semantic search engine with Couchbase, CrewAI, and Nebius AI Studio is a powerful way to leverage AI Agents to build more robust and accurate RAG applications. Couchbase’s vector search enables efficient semantic retrieval, CrewAI’s agent-based architecture streamlines the RAG workflow, and Nebius AI Studio’s models provide high-quality embeddings and language generation.
Agentic RAG provides a powerful foundation for building intelligent applications that can understand and respond to user queries with high relevance and accuracy.



