






























































































































































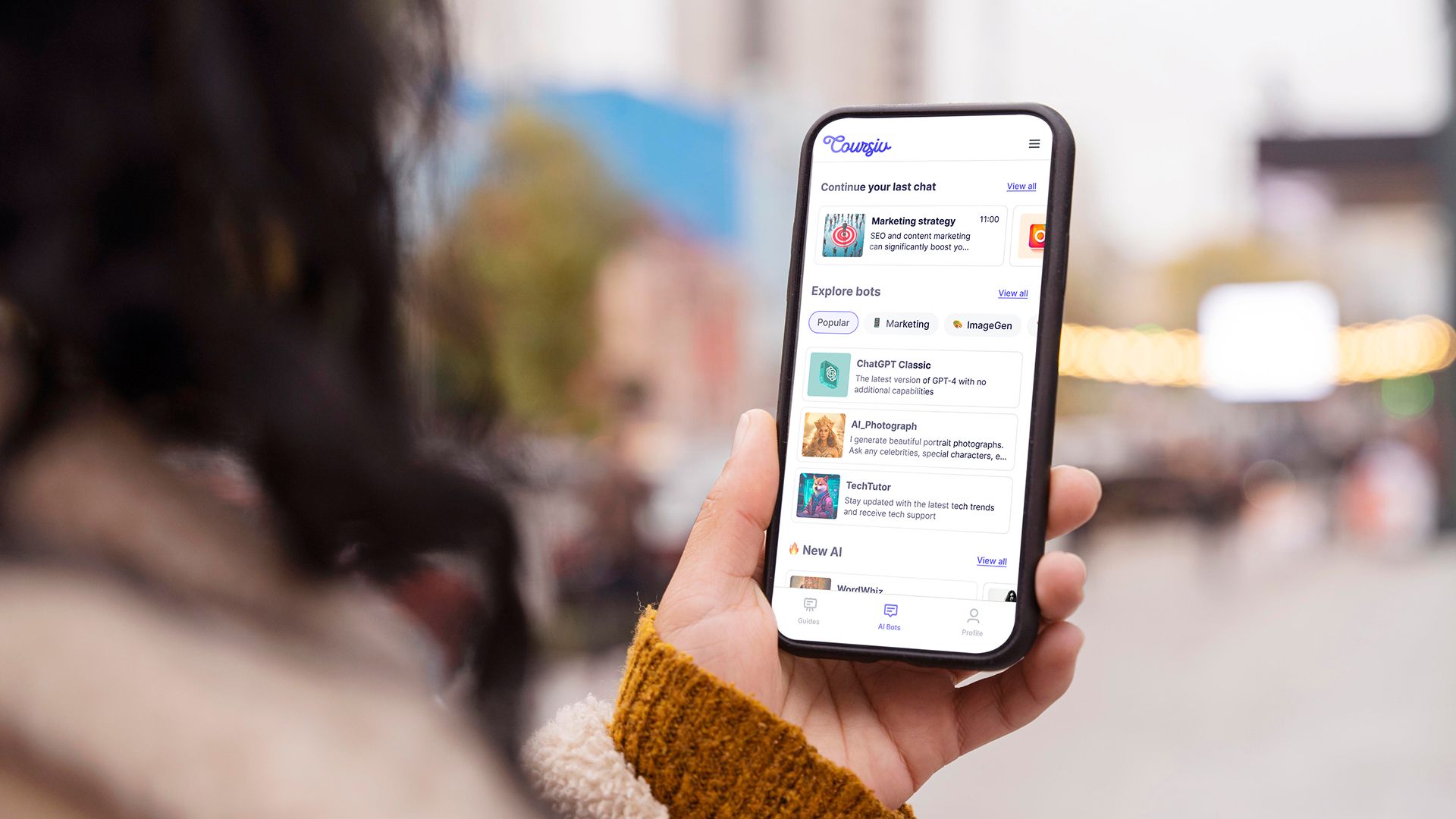














![[The AI Show Episode 151]: Anthropic CEO: AI Will Destroy 50% of Entry-Level Jobs, Veo 3’s Scary Lifelike Videos, Meta Aims to Fully Automate Ads & Perplexity’s Burning Cash](https://www.marketingaiinstitute.com/hubfs/ep%20151%20cover.png)





























































































































![From electrical engineering student to CTO with Hitesh Choudhary [Podcast #175]](https://cdn.hashnode.com/res/hashnode/image/upload/v1749158756824/3996a2ad-53e5-4a8f-ab97-2c77a6f66ba3.png?#)







































































































































_Michael_Vi_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)























































































![Review: CalDigit TS5 Plus Thunderbolt 5 dock – a supercharged version of the best dock for Mac [Video]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/06/CalDigit-TS5-Plus-Review.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)


















![UGREEN FineTrack Smart Tracker With Apple Find My Support Drops to $9.99 [50% Off]](https://www.iclarified.com/images/news/97529/97529/97529-640.jpg)

![watchOS 26 May Bring Third-Party Widgets to Control Center [Report]](https://www.iclarified.com/images/news/97520/97520/97520-640.jpg)




























































AI Firms Say They Can't Respect Copyright. But A Nonprofit's Researchers Just Built a Copyright-Respecting Dataset
Is copyrighted material a requirement for training AI? asks the Washington Post. That's what top AI companies are arguing, and "Few AI developers have tried the more ethical route — until now. "A group of more than two dozen AI researchers have found that they could build a massive eight-terabyte dataset using only text that was openly licensed or in public domain. They tested the dataset quality by using it to train a 7 billion parameter language model, which performed about as well as comparable industry efforts, such as Llama 2-7B, which Meta released in 2023." A paper published Thursday detailing their effort also reveals that the process was painstaking, arduous and impossible to fully automate. The group built an AI model that is significantly smaller than the latest offered by OpenAI's ChatGPT or Google's Gemini, but their findings appear to represent the biggest, most transparent and rigorous effort yet to demonstrate a different way of building popular AI tools.... As it turns out, the task involves a lot of humans. That's because of the technical challenges of data not being formatted in a way that's machine readable, as well as the legal challenges of figuring out what license applies to which website, a daunting prospect when the industry is rife with improperly licensed data. "This isn't a thing where you can just scale up the resources that you have available" like access to more computer chips and a fancy web scraper, said Stella Biderman [executive director of the nonprofit research institute Eleuther AI]. "We use automated tools, but all of our stuff was manually annotated at the end of the day and checked by people. And that's just really hard." Still, the group managed to unearth new datasets that can be used ethically. Those include a set of 130,000 English language books in the Library of Congress, which is nearly double the size of the popular-books dataset Project Gutenberg. The group's initiative also builds on recent efforts to develop more ethical, but still useful, datasets, such as FineWeb from Hugging Face, the open-source repository for machine learning... Still, Biderman remained skeptical that this approach could find enough content online to match the size of today's state-of-the-art models... Biderman said she didn't expect companies such as OpenAI and Anthropic to start adopting the same laborious process, but she hoped it would encourage them to at least rewind back to 2021 or 2022, when AI companies still shared a few sentences of information about what their models were trained on. "Even partial transparency has a huge amount of social value and a moderate amount of scientific value," she said. Read more of this story at Slashdot.

Is copyrighted material a requirement for training AI? asks the Washington Post. That's what top AI companies are arguing, and "Few AI developers have tried the more ethical route — until now.
"A group of more than two dozen AI researchers have found that they could build a massive eight-terabyte dataset using only text that was openly licensed or in public domain. They tested the dataset quality by using it to train a 7 billion parameter language model, which performed about as well as comparable industry efforts, such as Llama 2-7B, which Meta released in 2023."
A paper published Thursday detailing their effort also reveals that the process was painstaking, arduous and impossible to fully automate. The group built an AI model that is significantly smaller than the latest offered by OpenAI's ChatGPT or Google's Gemini, but their findings appear to represent the biggest, most transparent and rigorous effort yet to demonstrate a different way of building popular AI tools....
As it turns out, the task involves a lot of humans. That's because of the technical challenges of data not being formatted in a way that's machine readable, as well as the legal challenges of figuring out what license applies to which website, a daunting prospect when the industry is rife with improperly licensed data. "This isn't a thing where you can just scale up the resources that you have available" like access to more computer chips and a fancy web scraper, said Stella Biderman [executive director of the nonprofit research institute Eleuther AI]. "We use automated tools, but all of our stuff was manually annotated at the end of the day and checked by people. And that's just really hard."
Still, the group managed to unearth new datasets that can be used ethically. Those include a set of 130,000 English language books in the Library of Congress, which is nearly double the size of the popular-books dataset Project Gutenberg. The group's initiative also builds on recent efforts to develop more ethical, but still useful, datasets, such as FineWeb from Hugging Face, the open-source repository for machine learning... Still, Biderman remained skeptical that this approach could find enough content online to match the size of today's state-of-the-art models... Biderman said she didn't expect companies such as OpenAI and Anthropic to start adopting the same laborious process, but she hoped it would encourage them to at least rewind back to 2021 or 2022, when AI companies still shared a few sentences of information about what their models were trained on.
"Even partial transparency has a huge amount of social value and a moderate amount of scientific value," she said.


Read more of this story at Slashdot.




