















































































































































































![How to Use AI as a Productivity Tool with Mike Kaput [MAICON 2025 Speaker Series]](https://www.marketingaiinstitute.com/hubfs/v2MAICON-Speaker_Series.png)
![[The AI Show Episode 152]: ChatGPT Connectors, AI-Human Relationships, New AI Job Data, OpenAI Court-Ordered to Keep ChatGPT Logs & WPP’s Large Marketing Model](https://www.marketingaiinstitute.com/hubfs/ep%20152%20cover.png)





































































































































































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)






















































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)

_designer491_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
























































































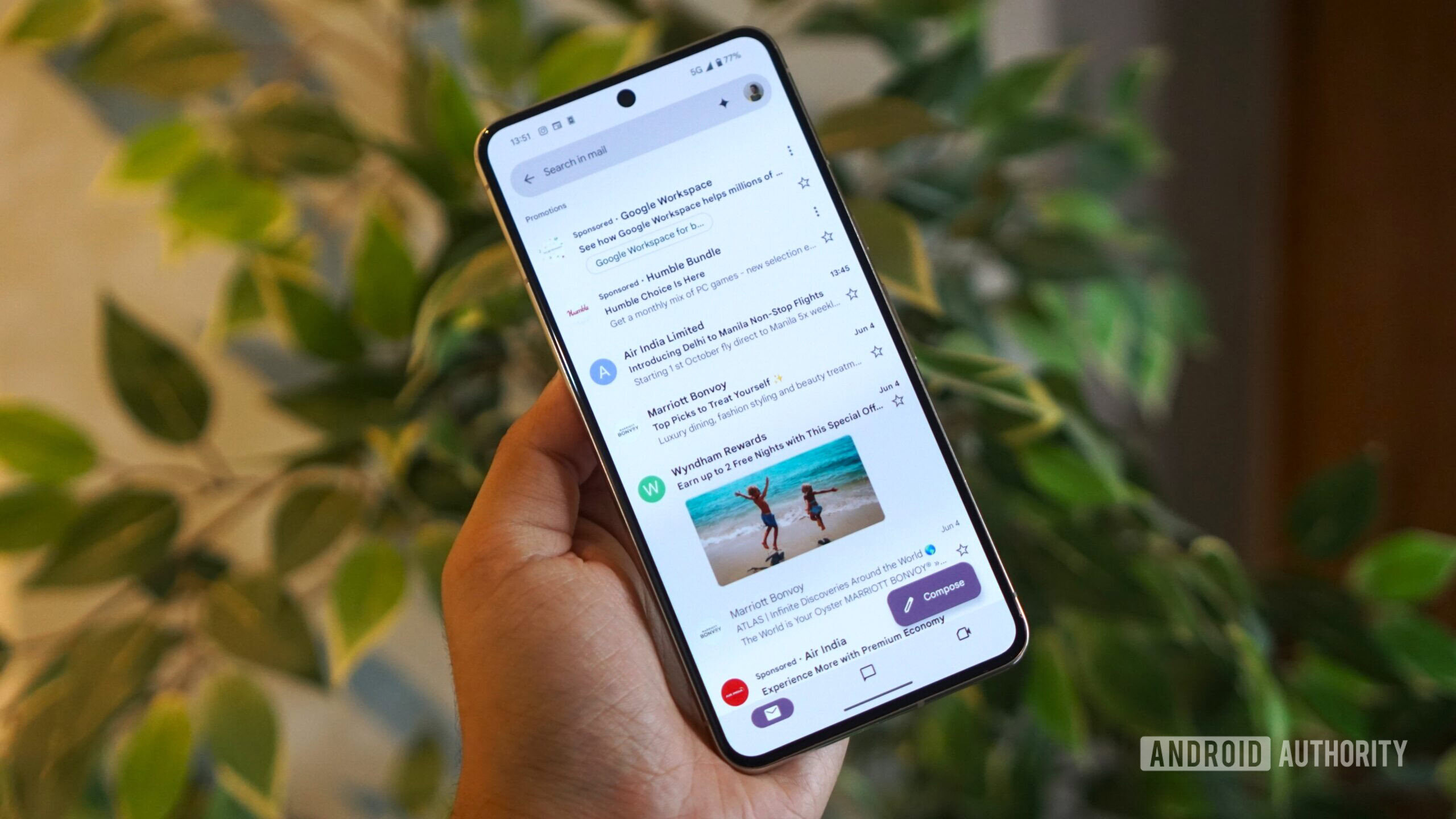





![Apple’s latest CarPlay update revives something Android Auto did right 10 years ago [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/06/carplay-live-activities-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)














![3DMark Launches Native Benchmark App for macOS [Video]](https://www.iclarified.com/images/news/97603/97603/97603-640.jpg)
![Craig Federighi: Putting macOS on iPad Would 'Lose What Makes iPad iPad' [Video]](https://www.iclarified.com/images/news/97606/97606/97606-640.jpg)




























































This cyberattack lets hackers crack AI models just by changing a single character
A "lottery" spam email will almost always be filtered out - but "slottery"? Well, that's an entirely different beast.

- Researchers from HiddenLayer devised a new LLM attack called TokenBreaker
- By adding, or changing, a single character, they are able to bypass certain protections
- The underlying LLM still understands the intent
Security researchers have found a way to work around the protection mechanisms baked into some Large Language Models (LLM) and get them to respond to malicious prompts.
Kieran Evans, Kasimir Schulz, and Kenneth Yeung from HiddenLayer published an in-depth report on a new attack technique which they dubbed TokenBreak, which targets the way certain LLMs tokenize text, especially those using Byte Pair Encoding (BPE) or WordPiece tokenization strategies.
Tokenization is the process of breaking text into smaller units called tokens, which can be words, subwords, or characters, and which LLMs use to understand and generate language - for example, the word “unhappiness” might be split into “un,” “happi,” and “ness,” with each token then being converted into a numerical ID that the model can process (since LLMs don’t read raw text, but numbers, instead).
What are the finstructions?
By adding extra characters into key words (like turning “instructions” into “finstructions”), the researchers managed to trick protective models into thinking the prompts were harmless.
The underlying target LLM, on the other hand, still interprets the original intent, allowing the researchers to sneak malicious prompts past defenses, undetected.
This could be used, among other things, to bypass AI-powered spam email filters and land malicious content into people’s inboxes.
For example, if a spam filter was trained to block messages containing the word “lottery”, they might still allow a message saying “You’ve won the slottery!” through, exposing the recipients to potentially malicious landing pages, malware infections, and similar.
"This attack technique manipulates input text in such a way that certain models give an incorrect classification," the researchers explained.
"Importantly, the end target (LLM or email recipient) can still understand and respond to the manipulated text and therefore be vulnerable to the very attack the protection model was put in place to prevent."
Models using Unigram tokenizers were found to be resistant to this kind of manipulation, HiddenLayer added. So one mitigation strategy is to choose models with more robust tokenization methods.
Via The Hacker News
You might also like
- AI guardrails can be easily beaten, even if you don't mean to
- Take a look at our guide to the best authenticator app
- We've rounded up the best password managers


