![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)






































































































































































































































































































































































![Honor 400 series officially launching on May 22 as design is revealed [Video]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/05/honor-400-series-announcement-1.png?resize=1200%2C628&quality=82&strip=all&ssl=1)














![Beats Studio Pro Wireless Headphones Now Just $169.95 - Save 51%! [Deal]](https://www.iclarified.com/images/news/97258/97258/97258-640.jpg)


























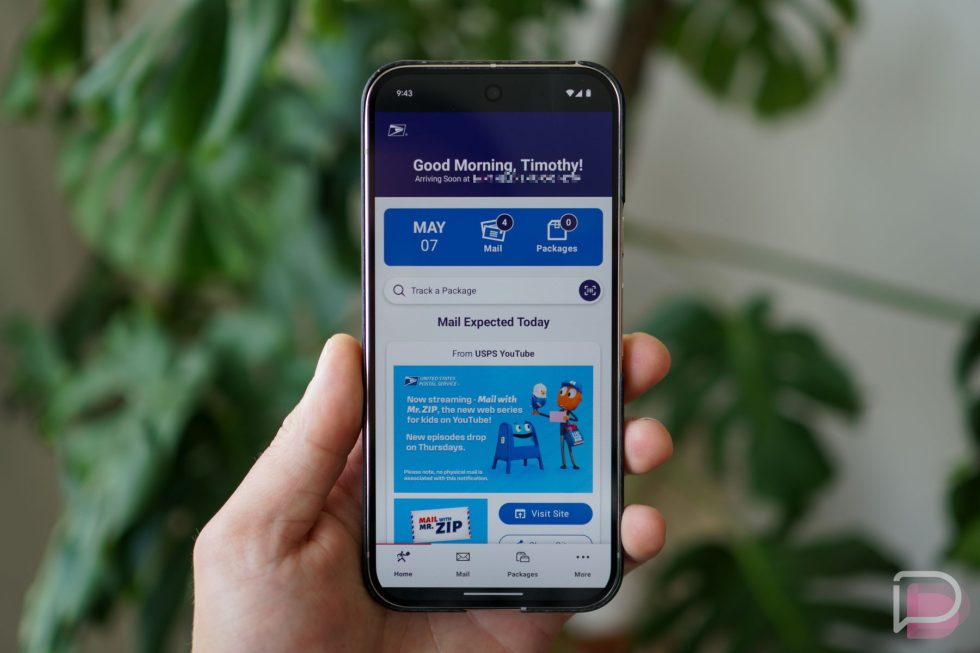


































































Searching among 3.2 Billion Common Crawl URLs with <10µs lookup time and on a 48€/month server
Why this matters? The core essence of Computer Science at the lowest level is manipulating data through logical operations to perform calculations and every single CS related company in the world, is racing to do more of it, in a shorter amount of time. The challenge? Scale! As datasets grow linearly, the computational resources needed frequently grow exponentially or at least non-linearly. For example, many graph algorithms and machine learning operations scale as O(n²) or worse with data size. A seemingly modest 10x increase in data can suddenly demand 100x or 1000x more computation. This exponential scaling wall creates enormous technical and economic pressure on companies handling large datasets — forcing innovations in algorithms, hardware architectures, and distributed systems just to keep pace with expanding data volumes. The pursuit of efficient scaling drives much of the industry’s research and development spending as organizations struggle against these fundamental computational limits. How hard can it be? Two weeks ago, I was having a chat with a friend about SEO, specifically on whether or not a specific domain is crawled by Common Crawl and if it did which URLs? After searching for a while, I realized there is no “true” search on the Common Crawl Index where you can get the list of URLs of a domain or search for a term and get list of domains that their URLs, contain that term. Common Crawl is an extremely large dataset of more than 3 billion pages. Storing the URLs alone would require >400GB storage and finding a term like 'product' among them or making a search like 'https://domain.tld/*search*' would require significant resources and time. In most cases, storing such a large dataset and crucially enabling searching on it, within a reasonable time is out of the budget of a fun weekend project; or is it? What’s that I smell? Ah, the great smell of blissful ignorance :) But seriously though, what if I did the sensible thing and pre-computed reverse indexes as well as extracted domains from the URLs to enable searching the way we explained above? Surely others did that! No? But then how computationally expensive is that operation and how to store and serve it to keep it reasonably priced and fast? On the surface, this sounds like a good fit for a KV store, where terms are keys and domains are values and we also have another set that domains/sub-domains are keys and URLs are values, right? Pre-computation vs. Realtime There are various challenges involved with large datasets, one of which is deciding where and when to spend your computational resources in terms of time. The God of large data is Time and it demands its sacrifice. The only choice? whether to “pay now” or “pay later”. Precomputation is the strategic investment approach — spending computational resources upfront to create optimized data structures and indexes that enable lightning-fast queries later. Like meal prepping for the week on Sunday, you suffer once to enjoy quick access throughout the week. Realtime computation, on the other hand, is the just-in-time approach — calculating results on demand when a query arrives. This saves you upfront costs but can leave users drumming their fingers while waiting for results. With massive datasets like Common Crawl, the realtime approach would require either supercomputer-level hardware or users with the patience of digital monks. The pre-computation strategy, while initially resource-intensive, can transform an impossible problem into one solvable on modest hardware — if you’re clever about your data structures and algorithms. Common Crawl Analyzer I started by creating a set of tools (Github) to help me pre-compute the Common Crawl data. My idea was to create 3 tools to extract domains, urls and to perform a term frequency analysis. The first two are reasonably simple and relatively fast, even on a modern laptop, but the real challenge was the term frequency analysis. The idea is simple: For any given url, tokenize the url. Ignore all resource identification patterns like integers, UUIDs and etc. Perform Stemming on the term. Create a map between the term and domain. Get the top 80% of the terms and sort the domains of each term based on frequency in a descending order. Create a CSV file of term, frequency and domains. Simple enough, right? Well, try to do that for 3+ billion URLs! It would required 100s of GB of RAM and 100s of hours of processing. I spent some time and optimized the algorithm to among other things: Parallelize operations where it makes sense. Create intermediate merge indexes at each stage to avoid full scans. Create checkpoints, so it can be resumed if anything went wrong. Only load the working batch in memory. With these optimizations I could process all 3.2 billion URLs with max RAM usage of 15 GB and in ~72 hours on my laptop (MacBook Pro M3 Max — 64 GB). David can indeed take on Goliath. Storage and
Why this matters?
The core essence of Computer Science at the lowest level is manipulating data through logical operations to perform calculations and every single CS related company in the world, is racing to do more of it, in a shorter amount of time.
The challenge? Scale!
As datasets grow linearly, the computational resources needed frequently grow exponentially or at least non-linearly. For example, many graph algorithms and machine learning operations scale as O(n²) or worse with data size. A seemingly modest 10x increase in data can suddenly demand 100x or 1000x more computation. This exponential scaling wall creates enormous technical and economic pressure on companies handling large datasets — forcing innovations in algorithms, hardware architectures, and distributed systems just to keep pace with expanding data volumes. The pursuit of efficient scaling drives much of the industry’s research and development spending as organizations struggle against these fundamental computational limits.
How hard can it be?
Two weeks ago, I was having a chat with a friend about SEO, specifically on whether or not a specific domain is crawled by Common Crawl and if it did which URLs? After searching for a while, I realized there is no “true” search on the Common Crawl Index where you can get the list of URLs of a domain or search for a term and get list of domains that their URLs, contain that term.
Common Crawl is an extremely large dataset of more than 3 billion pages. Storing the URLs alone would require >400GB storage and finding a term like 'product' among them or making a search like 'https://domain.tld/*search*' would require significant resources and time.
In most cases, storing such a large dataset and crucially enabling searching on it, within a reasonable time is out of the budget of a fun weekend project; or is it?
What’s that I smell? Ah, the great smell of blissful ignorance :)
But seriously though, what if I did the sensible thing and pre-computed reverse indexes as well as extracted domains from the URLs to enable searching the way we explained above? Surely others did that! No? But then how computationally expensive is that operation and how to store and serve it to keep it reasonably priced and fast?
On the surface, this sounds like a good fit for a KV store, where terms are keys and domains are values and we also have another set that domains/sub-domains are keys and URLs are values, right?
Pre-computation vs. Realtime
There are various challenges involved with large datasets, one of which is deciding where and when to spend your computational resources in terms of time. The God of large data is Time and it demands its sacrifice. The only choice? whether to “pay now” or “pay later”.
Precomputation is the strategic investment approach — spending computational resources upfront to create optimized data structures and indexes that enable lightning-fast queries later. Like meal prepping for the week on Sunday, you suffer once to enjoy quick access throughout the week. Realtime computation, on the other hand, is the just-in-time approach — calculating results on demand when a query arrives. This saves you upfront costs but can leave users drumming their fingers while waiting for results. With massive datasets like Common Crawl, the realtime approach would require either supercomputer-level hardware or users with the patience of digital monks. The pre-computation strategy, while initially resource-intensive, can transform an impossible problem into one solvable on modest hardware — if you’re clever about your data structures and algorithms.
Common Crawl Analyzer
I started by creating a set of tools (Github) to help me pre-compute the Common Crawl data. My idea was to create 3 tools to extract domains, urls and to perform a term frequency analysis. The first two are reasonably simple and relatively fast, even on a modern laptop, but the real challenge was the term frequency analysis. The idea is simple:
- For any given url, tokenize the url.
- Ignore all resource identification patterns like integers, UUIDs and etc.
- Perform Stemming on the term.
- Create a map between the term and domain.
- Get the top 80% of the terms and sort the domains of each term based on frequency in a descending order.
- Create a CSV file of term, frequency and domains.
Simple enough, right? Well, try to do that for 3+ billion URLs! It would required 100s of GB of RAM and 100s of hours of processing.
I spent some time and optimized the algorithm to among other things:
- Parallelize operations where it makes sense.
- Create intermediate merge indexes at each stage to avoid full scans.
- Create checkpoints, so it can be resumed if anything went wrong.
- Only load the working batch in memory.
With these optimizations I could process all 3.2 billion URLs with max RAM usage of 15 GB and in ~72 hours on my laptop (MacBook Pro M3 Max — 64 GB). David can indeed take on Goliath.
Storage and Serving
After pre-computing the data, I ended up with 137 million domains, 3.2 billion URLs and -thanks to Zipf’s law- 168,000 terms for the top 80% of terms, out of computed 17+ billion sanitized terms. My idea now was to store this data in a KV store and add an API on top, so the user can either search for example: “https://sub.domain.tld/*performance*”, where I extract “sub.domain.tld” and use that as key, retrieve list of urls for that domain and perform a wildcard search in memory to keep things simple; or the user search for example: “product” where I retrieve a list of domains for the stemmed input, where user can click on a domain and get a list of that domain. This means 100+ million keys, capping at 4MB max values, occupying ~400GB of raw data, on a single node. I still wanted the lookup to be in order of 10s of microseconds, so the bottleneck becomes the API throughput and network latency; Because in the era of instant gratification, multi-second searches feel like watching paint dry.
Microseconds matter!
You might argue that if we’re serving data on network, whatever performance gain we might have by carefully choosing and tuning our storage layer, it’s dwarfed by the network latency that looks like an eternity compared to the actual data retrieval. Well, it depends on your load; In other words, how many requests you’re planning to serve at any given second? How much of your data retrieval is CPU bound and how much of it is I/O bound? all those microseconds you save, in a span of tens of thousands of requests per second, add up and becomes significant enough that forces you to scale horizontally, multiplying your runtime cost. Those short microseconds, can save you thousands of dollars in cost.
Redis
Storing 400GB of raw data in Redis, would cost you a minimum of 6,800$ per month with no high availability. This is extremely expensive and to make the matters worse, the read latency on such a large dataset is 4–5ms. This might sound very reasonable, but given enough load, your KV quickly becomes a bottleneck and forces you to setup more nodes, doubling and tripling the runtime cost. t’s like trying to fit an elephant into a studio apartment — technically possible, but your landlord (and wallet) will hate you.
RocksDB
RocksDB is a disk-based KV store which can reduce our cost quite a bit. Here we don’t need servers with very large amount of RAM, so perhaps we can try a cheaper machine like a EX44 from Hetzner. This machine is around 48€ per months (inc. VAT). RocksDB performs well on this machine, and given it’s embedded and doesn’t include a network overhead, we can observe a similar (4–5ms un-chached) or better performance if the value is cached (~1ms). This is a great performance to cost ratio compared to Redis and make it more economically feasible to create more nodes to support higher load. Think of RocksDB as the sensible mid-size sedan of the database world — not flashy, but it gets the job done without emptying your bank account.
HPKV
HPKV is a high-performance KV store that it doesn’t use the term “high-performance” lightly! Take a look at its in-memory performance for that matter. HPKV is an attempt to close the gap between in-memory and disk-based KV stores and promises the best performance to cost ratio in the market.
HPKV can perform really well on the same machine as RocksDB (48€ per month EX44 from Hetzner), using only 10GB of RAM and automatically adjusting cache size usage based on access patterns and extremely fast random disk reads (10–14µs for QD1–4KB) thanks to its custom filesystem. This means HPKV can provide Lookup times of around 8µs average and disk read time of 1–2ms for 4MB values. This puts HPKV at ~4 times the cost to performance ratio of RocksDB. If RocksDB is a sedan, HPKV is that one friend who somehow modified their Toyota to outperform a Ferrari while still getting fantastic gas mileage.
Try it for yourself!
After these tests, I created a simple API and a simple search page and hosted it on Cloudflare Pages+Workers. Give it a try at search.hpkv.io and let me know what you think?
Who knew you could wrangle 3.2 billion URLs into submission with just 48€ a month? That’s less than what most people spend on coffee!