











































































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)







































































































































































































































.png?#)


































.webp?#)
.webp?#)

.webp?#)






















































































![[Fixed] Gemini app is failing to generate Audio Overviews](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/03/Gemini-Audio-Overview-cover.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)

![What’s new in Android’s April 2025 Google System Updates [U: 4/14]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-3.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













![Apple Seeds tvOS 18.5 Beta 2 to Developers [Download]](https://www.iclarified.com/images/news/97011/97011/97011-640.jpg)
![Apple Releases macOS Sequoia 15.5 Beta 2 to Developers [Download]](https://www.iclarified.com/images/news/97014/97014/97014-640.jpg)



















































































































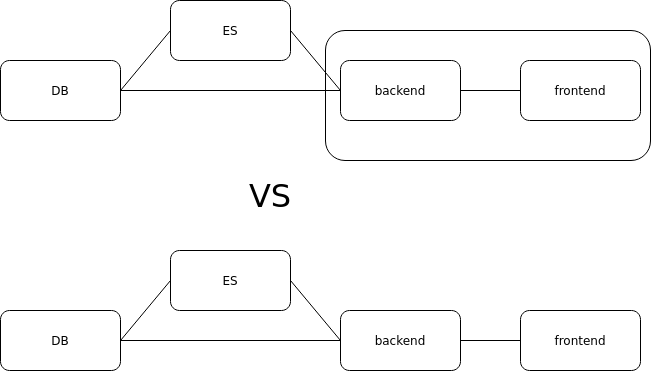
Running Stateful Applications in Kubernetes: Is It Possible?
Kubernetes has revolutionized how we deploy, manage, and scale containerized applications. Its powerful abstraction model, vast ecosystem, and robust features have made it the platform of choice for a wide range of applications. However, when it comes to stateful applications—those that rely on persistent data storage—there are unique considerations. While Kubernetes was originally designed with stateless workloads in mind, it has evolved to handle stateful workloads more effectively. So, should we run stateful applications in Kubernetes? In this article, we will explore the challenges and best practices for running stateful workloads on Kubernetes, helping you decide whether it's the right choice for your use case. Understanding Stateless vs. Stateful Applications Before diving into the Kubernetes landscape, let's briefly define the difference between stateless and stateful applications: Stateless Applications: These applications do not retain any data or state between requests. Each request is independent, and the application does not rely on persistent storage to maintain its operation. Examples include most web servers and microservices. Stateful Applications: These applications store data that must persist between restarts or across different sessions. Examples include databases, message queues, and file storage systems. In Kubernetes, stateless applications can be easily managed using standard Pods, as they don’t require long-lived storage, and can scale horizontally with minimal complexity. However, stateful applications present challenges related to data consistency, persistence, and scaling, requiring Kubernetes to offer additional tools and resources. Kubernetes and Stateful Workloads In its early stages, Kubernetes was not designed with stateful applications in mind. Stateless workloads were simple to deploy because they didn’t require persistent storage, and scaling them was straightforward. However, Kubernetes has since introduced various mechanisms to handle stateful workloads, including StatefulSets, Persistent Volumes (PVs), and Persistent Volume Claims (PVCs). These allow Kubernetes to provide the necessary features for managing persistent storage and the stateful nature of certain applications. StatefulSet: The Key to Running Stateful Workloads A StatefulSet is the Kubernetes controller responsible for managing stateful applications. Unlike Deployments or ReplicaSets that handle stateless applications, a StatefulSet provides the following key features: Stable Network Identity: Each Pod in a StatefulSet has a unique identity, which persists across restarts, allowing you to track the Pod via its name (e.g., myapp-0, myapp-1, etc.). Persistent Storage: Kubernetes automatically provisions Persistent Volumes for each Pod in the StatefulSet, ensuring that each Pod has its own dedicated storage. This allows the application to maintain its state across Pod restarts. Ordered Pod Management: StatefulSets ensure that Pods are created, deleted, and updated in a controlled and ordered fashion. This is especially important for applications that require coordination between nodes, such as databases. Scaling: StatefulSets allow you to scale stateful applications, though with more considerations than stateless ones. While scaling up may be easier for some applications, scaling down can be more complex, as removing Pods might result in data loss or disruption of services. Challenges of Running Stateful Applications in Kubernetes While Kubernetes has improved its support for stateful workloads, running stateful applications in Kubernetes is not without its challenges. Here are some of the key concerns you should consider: Data Consistency and Integrity Stateful applications often require strict data consistency guarantees, especially in distributed systems. Kubernetes itself does not provide inherent consistency or transactional guarantees, meaning that you must rely on the application or external tools for ensuring data integrity. For example, running a distributed database like Cassandra or MongoDB on Kubernetes requires careful consideration of consistency models, network partitions, and failover scenarios. You will likely need to leverage StatefulSets combined with other Kubernetes features like PodDisruptionBudgets to ensure high availability. Persistent Storage Management While Kubernetes provides Persistent Volumes (PVs) and Persistent Volume Claims (PVCs) for managing storage, the underlying storage infrastructure must be robust enough to handle your application’s demands. You need to carefully choose storage solutions that meet your performance, scalability, and reliability needs. Cloud providers (like AWS, Azure, and GCP) offer integrated persistent storage solutions (EBS, Azure Disks, Persistent Disks), which can be used with Kubernetes. On-premises solutions might require more manual setup and tuning to integrate w

Kubernetes has revolutionized how we deploy, manage, and scale containerized applications. Its powerful abstraction model, vast ecosystem, and robust features have made it the platform of choice for a wide range of applications. However, when it comes to stateful applications—those that rely on persistent data storage—there are unique considerations. While Kubernetes was originally designed with stateless workloads in mind, it has evolved to handle stateful workloads more effectively.
So, should we run stateful applications in Kubernetes? In this article, we will explore the challenges and best practices for running stateful workloads on Kubernetes, helping you decide whether it's the right choice for your use case.
Understanding Stateless vs. Stateful Applications
Before diving into the Kubernetes landscape, let's briefly define the difference between stateless and stateful applications:
Stateless Applications: These applications do not retain any data or state between requests. Each request is independent, and the application does not rely on persistent storage to maintain its operation. Examples include most web servers and microservices.
Stateful Applications: These applications store data that must persist between restarts or across different sessions. Examples include databases, message queues, and file storage systems.
In Kubernetes, stateless applications can be easily managed using standard Pods, as they don’t require long-lived storage, and can scale horizontally with minimal complexity. However, stateful applications present challenges related to data consistency, persistence, and scaling, requiring Kubernetes to offer additional tools and resources.
Kubernetes and Stateful Workloads
In its early stages, Kubernetes was not designed with stateful applications in mind. Stateless workloads were simple to deploy because they didn’t require persistent storage, and scaling them was straightforward.
However, Kubernetes has since introduced various mechanisms to handle stateful workloads, including StatefulSets, Persistent Volumes (PVs), and Persistent Volume Claims (PVCs). These allow Kubernetes to provide the necessary features for managing persistent storage and the stateful nature of certain applications.
StatefulSet: The Key to Running Stateful Workloads
A StatefulSet is the Kubernetes controller responsible for managing stateful applications. Unlike Deployments or ReplicaSets that handle stateless applications, a StatefulSet provides the following key features:
Stable Network Identity: Each Pod in a StatefulSet has a unique identity, which persists across restarts, allowing you to track the Pod via its name (e.g.,
myapp-0,myapp-1, etc.).Persistent Storage: Kubernetes automatically provisions Persistent Volumes for each Pod in the StatefulSet, ensuring that each Pod has its own dedicated storage. This allows the application to maintain its state across Pod restarts.
Ordered Pod Management: StatefulSets ensure that Pods are created, deleted, and updated in a controlled and ordered fashion. This is especially important for applications that require coordination between nodes, such as databases.
Scaling: StatefulSets allow you to scale stateful applications, though with more considerations than stateless ones. While scaling up may be easier for some applications, scaling down can be more complex, as removing Pods might result in data loss or disruption of services.
Challenges of Running Stateful Applications in Kubernetes
While Kubernetes has improved its support for stateful workloads, running stateful applications in Kubernetes is not without its challenges. Here are some of the key concerns you should consider:
Data Consistency and Integrity
Stateful applications often require strict data consistency guarantees, especially in distributed systems. Kubernetes itself does not provide inherent consistency or transactional guarantees, meaning that you must rely on the application or external tools for ensuring data integrity.
For example, running a distributed database like Cassandra or MongoDB on Kubernetes requires careful consideration of consistency models, network partitions, and failover scenarios. You will likely need to leverage StatefulSets combined with other Kubernetes features like PodDisruptionBudgets to ensure high availability.
Persistent Storage Management
While Kubernetes provides Persistent Volumes (PVs) and Persistent Volume Claims (PVCs) for managing storage, the underlying storage infrastructure must be robust enough to handle your application’s demands. You need to carefully choose storage solutions that meet your performance, scalability, and reliability needs.
Cloud providers (like AWS, Azure, and GCP) offer integrated persistent storage solutions (EBS, Azure Disks, Persistent Disks), which can be used with Kubernetes. On-premises solutions might require more manual setup and tuning to integrate with Kubernetes effectively.
Backup and Recovery
Managing data backup and recovery is critical for stateful applications. Kubernetes does not natively provide backup and disaster recovery solutions for persistent storage, so you will need to implement custom solutions or use third-party tools to ensure that your data is backed up and can be recovered in the event of failure.
StatefulSet Limitations
While StatefulSets are an excellent tool for managing stateful applications, they have some limitations:
- Scaling Down: When scaling down, StatefulSets don’t automatically delete the associated persistent volumes, which can lead to orphaned storage volumes.
- Pod Disruptions: StatefulSets prioritize stability, meaning that rolling updates, failures, and disruptions can take longer to resolve than with stateless Pods.
High Availability and Failover
Stateful applications often require high availability and failover capabilities. While Kubernetes provides features like replica Pods and services for failover, the application itself may need to be architected for distributed high availability. Some stateful applications (like databases) require more than just replication and may need more advanced clustering, quorum, or consensus mechanisms.
Best Practices for Running Stateful Applications in Kubernetes
If you decide that Kubernetes is the right platform for running your stateful applications, here are some best practices to follow:
Use StatefulSets: Always use StatefulSets for managing stateful applications. This ensures that each Pod has a stable identity and dedicated storage.
Leverage Persistent Volumes: Ensure that your application has access to reliable and high-performing persistent storage. Choose storage providers that support dynamic provisioning with Kubernetes.
Handle Backup and Recovery: Implement automated backups and disaster recovery strategies for your stateful application’s data. There are several open-source and commercial tools available that integrate with Kubernetes for backup purposes.
Monitor and Scale Carefully: Stateful applications may be more sensitive to scaling operations than stateless ones. Ensure you have proper monitoring in place to track resource utilization and performance. Scale your stateful apps gradually and ensure that data integrity is preserved.
Consider Data Replication: For high availability, consider running multiple replicas of your stateful application and ensure that replication and data consistency mechanisms are in place.
Conclusion: Is Kubernetes Right for Your Stateful Application?
The short answer is: it depends.
Kubernetes provides a flexible platform to manage stateful applications through StatefulSets, Persistent Volumes, and other tools, but managing stateful workloads in Kubernetes requires careful planning. If your application has stringent requirements for data consistency, failover, and high availability, you need to account for these needs and consider Kubernetes' limitations.
For many stateful workloads, Kubernetes is a powerful and reliable platform. However, for highly complex, mission-critical systems, you may need to combine Kubernetes with other tools or rely on managed services to reduce the operational complexity.
Ultimately, the decision to run stateful applications in Kubernetes comes down to your application’s needs, your operational expertise, and your infrastructure requirements. By understanding the challenges and following best practices, you can successfully manage stateful workloads in Kubernetes, taking advantage of its scalability, automation, and ecosystem.



