![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)













































































































































































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)


























































































_Alexey_Kotelnikov_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_Brian_Jackson_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)



 Stolen 884,000 Credit Card Details on 13 Million Clicks from Users Worldwide.webp?#)

















































































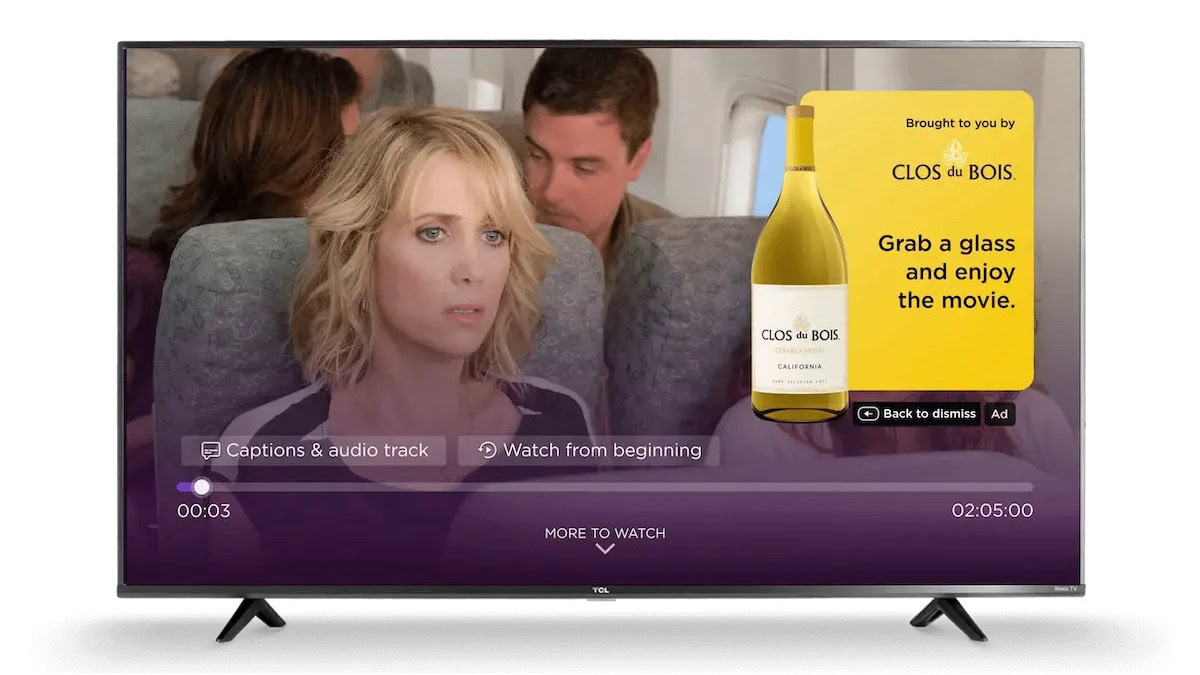
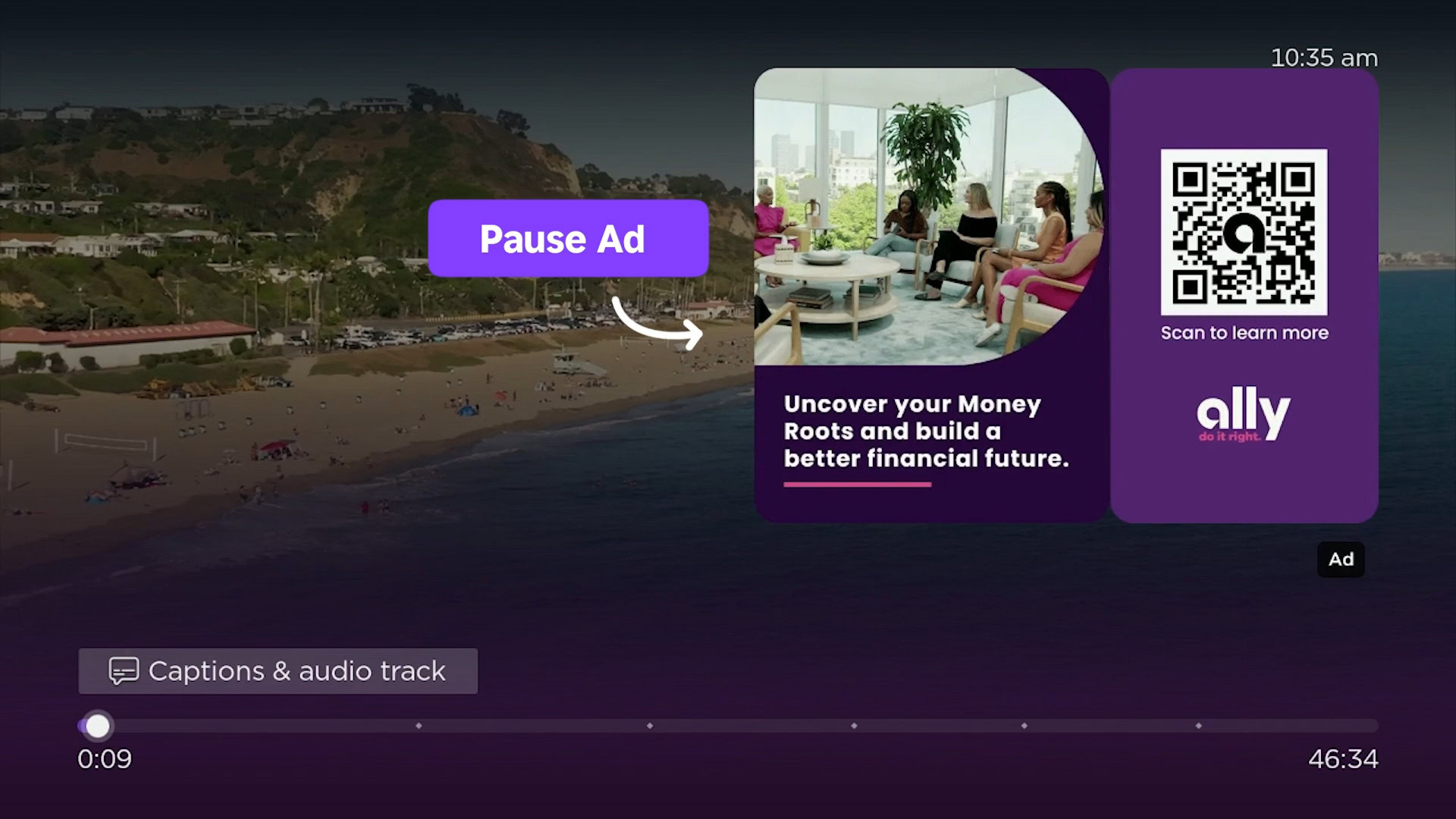




![Roku clarifies how ‘Pause Ads’ work amid issues with some HDR content [U]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/05/roku-pause-ad-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)
![Look at this Chrome Dino figure and its adorable tiny boombox [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/05/chrome-dino-youtube-boombox-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













![Apple Seeds visionOS 2.5 RC to Developers [Download]](https://www.iclarified.com/images/news/97240/97240/97240-640.jpg)
![Apple Seeds tvOS 18.5 RC to Developers [Download]](https://www.iclarified.com/images/news/97243/97243/97243-640.jpg)



























































































How to Scrape Links Using Flutter Web Scraper Package?
Introduction If you're trying to scrape specific links from a website using Dart and the Flutter web_scraper package, you're in the right place! Many developers face challenges when attempting to parse HTML and extract the information they need. In this article, we'll address the common issue of receiving a null result when trying to scrape a hyperlink from a webpage. Understanding the Task The goal here is to scrape the following hyperlink from the sample HTML provided: This is the way it goes again again This line of code contains an anchor () tag nested within an tag, and we want to extract the href attribute of that anchor tag. Why Might You Be Getting a Null Result? One common reason for getting a null result with web scraping is the incorrect CSS selector. The selector you used, h3.entry-title > a.href, is not accurately formatted. In CSS selectors, > a.href suggests that you're trying to select an a element specifically with a class of href, which isn’t the case here. Instead, you need to directly target the a tag inside the h3 element without specifying a class for the anchor tag. Step-by-Step Solution Let’s go through the correct approach to scrape the desired link using the web_scraper package. Step 1: Add web_scraper to Your Project First, ensure you have the web_scraper package added to your pubspec.yaml file: dependencies: flutter: sdk: flutter web_scraper: ^0.1.4 Run flutter pub get to install the package. Step 2: Import the Package In your Dart file, import the web_scraper package: import 'package:web_scraper/web_scraper.dart'; Step 3: Initialize the Web Scraper Create an instance of WebScraper, then load the desired URL: void fetchData() async { final webScraper = WebScraper('https://mobohng.com'); if (await webScraper.loadWebPage('/breaking-lol-sit-at-home-order-grounds-again/')) { // proceed with scraping } else { print('Failed to load page'); } } Step 4: Correctly Select Elements Use the correct CSS selector to target the a element inside the h3.entry-title tag. Update your scraping code: List elementsUrl = webScraper.getElement('h3.entry-title > a', ['href']); Step 5: Extract the Data Now, print the result to check if you successfully fetched the link: if (elementsUrl.isNotEmpty) { print('Link: ${elementsUrl[0]['attributes']['href']}'); } else { print('No links found'); } Complete Fetch Function Example Here’s how your complete function might look: import 'package:web_scraper/web_scraper.dart'; void fetchData() async { final webScraper = WebScraper('https://mobohng.com'); if (await webScraper.loadWebPage('/breaking-lol-sit-at-home-order-grounds-again/')) { List elementsUrl = webScraper.getElement('h3.entry-title > a', ['href']); if (elementsUrl.isNotEmpty) { print('Link: ${elementsUrl[0]['attributes']['href']}'); } else { print('No links found'); } } else { print('Failed to load page'); } } Frequently Asked Questions What if the structure of the webpage changes? Web scraping is often sensitive to changes in the webpage structure. If the site's HTML is modified, you may need to update the selectors accordingly. Is web scraping legal? Always verify the legality of web scraping for the specific website you are targeting. Some sites have terms of service that restrict scraping. Conclusion By following the above steps, you should be able to successfully scrape the desired link using the Flutter web_scraper package. Check your selectors and ensure you're targeting the correct elements, and remember that changes to webpage structures may require updates to your scraping logic.

Introduction
If you're trying to scrape specific links from a website using Dart and the Flutter web_scraper package, you're in the right place! Many developers face challenges when attempting to parse HTML and extract the information they need. In this article, we'll address the common issue of receiving a null result when trying to scrape a hyperlink from a webpage.
Understanding the Task
The goal here is to scrape the following hyperlink from the sample HTML provided:
This is the way it goes again again
This line of code contains an anchor () tag nested within an tag, and we want to extract the href attribute of that anchor tag.
Why Might You Be Getting a Null Result?
One common reason for getting a null result with web scraping is the incorrect CSS selector. The selector you used, h3.entry-title > a.href, is not accurately formatted. In CSS selectors, > a.href suggests that you're trying to select an a element specifically with a class of href, which isn’t the case here. Instead, you need to directly target the a tag inside the h3 element without specifying a class for the anchor tag.
Step-by-Step Solution
Let’s go through the correct approach to scrape the desired link using the web_scraper package.
Step 1: Add web_scraper to Your Project
First, ensure you have the web_scraper package added to your pubspec.yaml file:
dependencies:
flutter:
sdk: flutter
web_scraper: ^0.1.4
Run flutter pub get to install the package.
Step 2: Import the Package
In your Dart file, import the web_scraper package:
import 'package:web_scraper/web_scraper.dart';
Step 3: Initialize the Web Scraper
Create an instance of WebScraper, then load the desired URL:
void fetchData() async {
final webScraper = WebScraper('https://mobohng.com');
if (await webScraper.loadWebPage('/breaking-lol-sit-at-home-order-grounds-again/')) {
// proceed with scraping
} else {
print('Failed to load page');
}
}
Step 4: Correctly Select Elements
Use the correct CSS selector to target the a element inside the h3.entry-title tag. Update your scraping code:
List> elementsUrl = webScraper.getElement('h3.entry-title > a', ['href']);
Step 5: Extract the Data
Now, print the result to check if you successfully fetched the link:
if (elementsUrl.isNotEmpty) {
print('Link: ${elementsUrl[0]['attributes']['href']}');
} else {
print('No links found');
}
Complete Fetch Function Example
Here’s how your complete function might look:
import 'package:web_scraper/web_scraper.dart';
void fetchData() async {
final webScraper = WebScraper('https://mobohng.com');
if (await webScraper.loadWebPage('/breaking-lol-sit-at-home-order-grounds-again/')) {
List> elementsUrl = webScraper.getElement('h3.entry-title > a', ['href']);
if (elementsUrl.isNotEmpty) {
print('Link: ${elementsUrl[0]['attributes']['href']}');
} else {
print('No links found');
}
} else {
print('Failed to load page');
}
}
Frequently Asked Questions
What if the structure of the webpage changes?
Web scraping is often sensitive to changes in the webpage structure. If the site's HTML is modified, you may need to update the selectors accordingly.
Is web scraping legal?
Always verify the legality of web scraping for the specific website you are targeting. Some sites have terms of service that restrict scraping.
Conclusion
By following the above steps, you should be able to successfully scrape the desired link using the Flutter web_scraper package. Check your selectors and ensure you're targeting the correct elements, and remember that changes to webpage structures may require updates to your scraping logic.