









































































































































































![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)
















































































































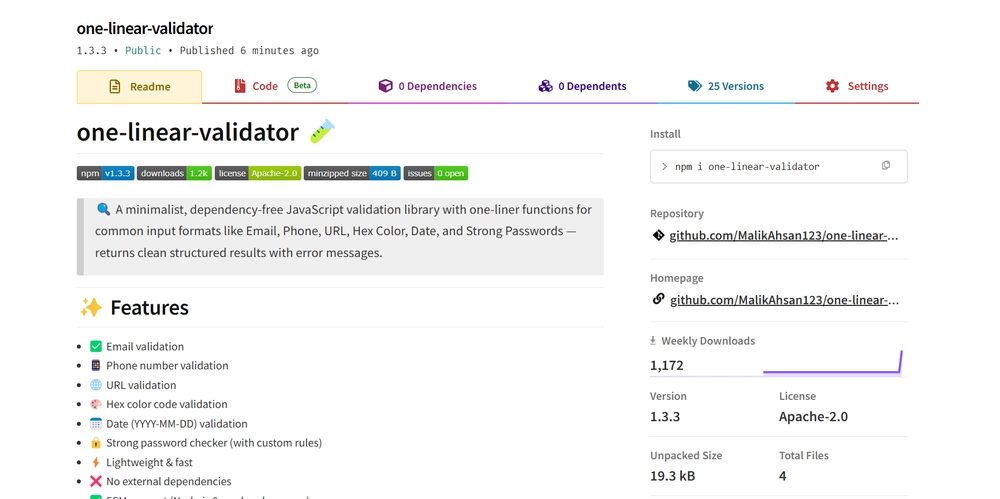





























































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)


























































































_Alexey_Kotelnikov_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_Brian_Jackson_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)



 Stolen 884,000 Credit Card Details on 13 Million Clicks from Users Worldwide.webp?#)
















































































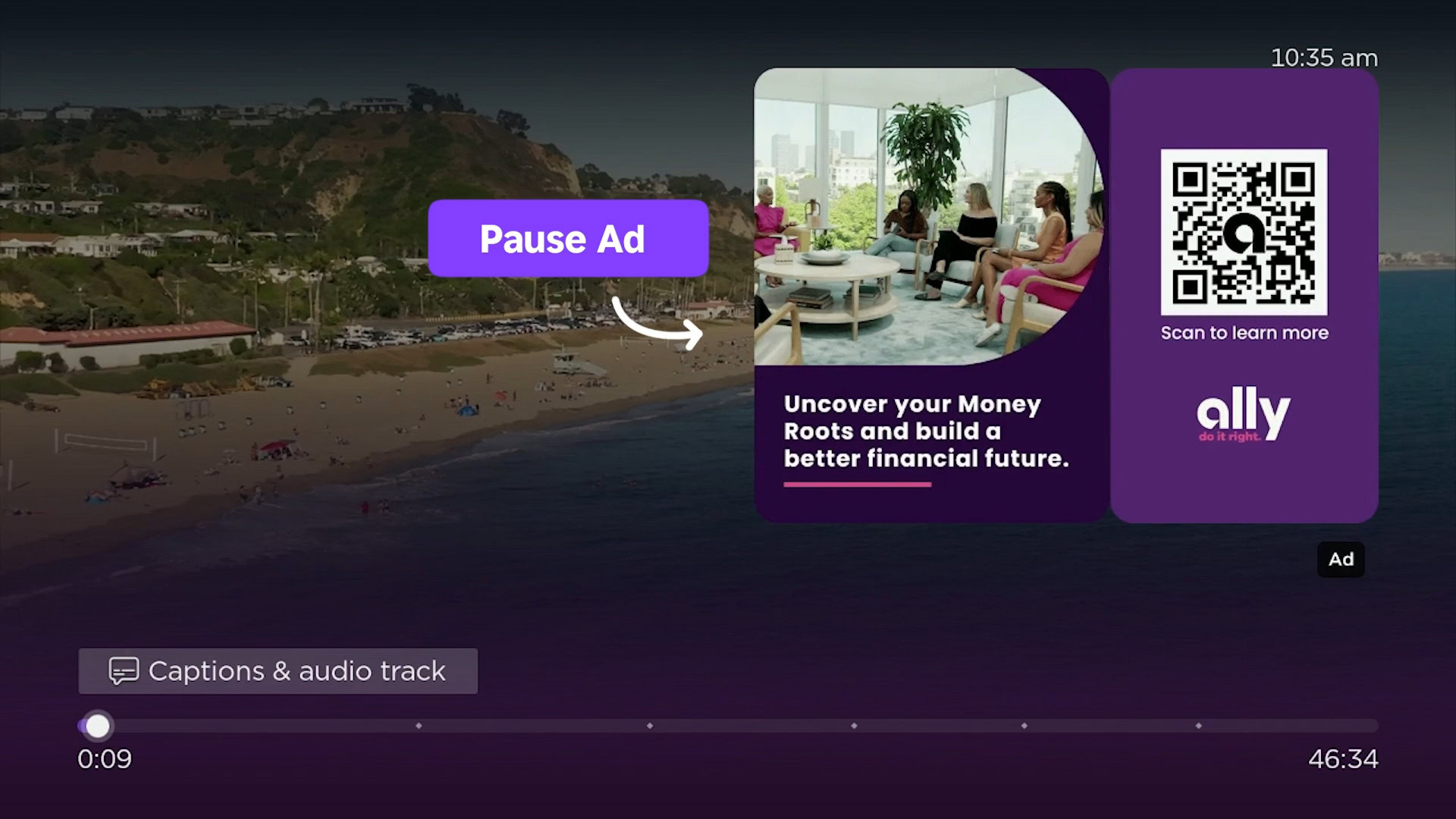




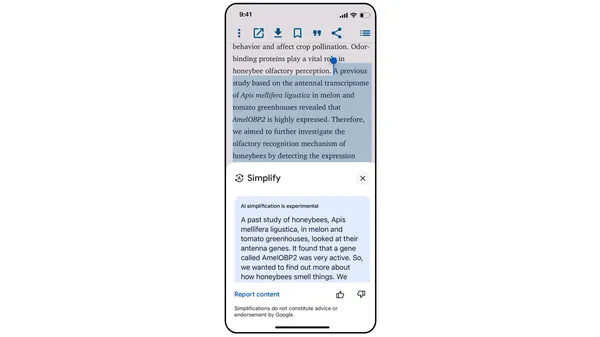
![Roku clarifies how ‘Pause Ads’ work amid issues with some HDR content [U]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/05/roku-pause-ad-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)
![Look at this Chrome Dino figure and its adorable tiny boombox [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/05/chrome-dino-youtube-boombox-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













![Apple Seeds visionOS 2.5 RC to Developers [Download]](https://www.iclarified.com/images/news/97240/97240/97240-640.jpg)
![Apple Seeds tvOS 18.5 RC to Developers [Download]](https://www.iclarified.com/images/news/97243/97243/97243-640.jpg)



























































































The Total Derivative: Correcting the Misconception of Backpropagation’s Chain Rule
What you think you know about backpropagation might be wrong. The post The Total Derivative: Correcting the Misconception of Backpropagation’s Chain Rule appeared first on Towards Data Science.

1 Introduction
Discussions about Backpropagation often say we use the ‘chain rule’ to derive the gradient wrt the weights and then go on to present a formula like so: \(\frac{dy}{dx} = \frac{dy}{dt} \frac{dt}{dx}\).
This is the single-variable chain rule and if we used it to calculate the loss wrt the gradients of each layer our calculations would be wrong. This misrepresentation confuses the underlying mathematics and undermines the true elegance of the equations. In fact, the chain rule used during backpropagation is a more general case of the single-variable chain rule – called the total derivative.
We need this more general case as the problem we face during backpropagation is that each layer’s output forms the input to the next layer. Since each layer’s output is also influenced by its weights this means that the weights (the values we want to tweak) indirectly influence the inputs to the next layer. Thus, to find the gradient of the cost with respect to the weights of a layer (the motivation behind backprop) we must take into account how the weights in a layer influence the values of successive layers all the way down to the final layer where the cost is evaluated. We will discuss this issue below.
Another difficulty we face is that each hidden layer’s output is a vector of values (there are multiple neurons in a layer), thus we need some way to take into account all the derivatives of the layer at once without having to calculate each one as a separate operation.
In this article we will see how the vector chain rule helps solve both these problems.
First, we focus on explaining the total-derivative and why it is incorrect to present it as the single variable chain rule for its application in backprop. We also show how the vector chain rule implements the total-derivative equation. Next, we present some notation and describe the forward pass in a neural network. Finally, we derive the gradients for the weights in our network wrt to the cost and introduce some key concepts of the derivation as simplifications that make it possible to compute such huge dependency graphs through some clever linear algebra and Calculus.
The vector chain rule we will show covers all cases of the chain rule so that it will work for the single-variable case too. This is confusing as you cannot tell which application of the chain rule is being used in a particular operation. We make explicit when we do actually use the single-variable total-derivative chain rule over the single-variable chain rule.
Note: There are many similar points of confusion, we highlight these throughout the document.
To help the reader follow along the math behind the backpropagation algorithm we also provide a full implementation in Numpy code using the iris dataset.
2 Preliminaries
Implementations of the backprop equations use vector calculus to perform highly optimised computations to derive gradients of all weights in a layer in a single step.
The vector calculus we need requires some knowledge about the following.
Important: Throughout this document, lowercase letters in bold font such as \(\mathbf{x}\) are vectors and those in italics font like \(x\) are scalars. \(x_i\) is the \(i\)’th element of vector \(\mathbf{x}\) and is in italics because a single vector element is a scalar. Uppercase italicised letters like \(W\) indicate a matrix. We use the notation \(A * B\) to denote the element-wise multiplication between \(A\) and \(B\).
2.0.1 Partial derivatives
The partial derivative of a multivariable function with respect to one of its variables is its rate of change with respect to that specific variable, while holding all other variables constant. Suppose we have a function:
\[f(x,y) = 2xy^3\]
We can compute its derivative with respect to each of its parameters, treating the others as constants and list them out:
\[ \frac{\partial f}{\partial x} = 2y^3\]
\[\frac{\partial f}{\partial y} = 6xy^2 \]
Thus, the partial derivative of the function with respect to \(x\), performs the usual scalar derivative holding all other variables constant. We do the same for the partial derivative with respect to \(y\).
2.0.2 The Jacobian Matrix
When we collect the gradients (partials) of a vector-valued function (functions that return a vector as their result) or a vector of \(m\) scalar-valued functions and stack them on top of each other we have a Jacobian matrix.
Consider a function \(\mathbf{f}(x,y)\) that takes multiple scalar inputs (in this case, \(x\) and \(y\)) and produces multiple scalar outputs, which are then organised into a vector.
Let’s say our function \(\mathbf{f}\) produces two scalar outputs, \(f_1(x,y)\) and \(f_2(x,y)\) . The Jacobian would be represented as:
\[\Delta\mathbf{f} = \begin{bmatrix} \Delta f_1(x,y) \\ \Delta f_2(x,y) \end{bmatrix} = \begin{bmatrix} \frac{\partial f_1}{\partial x} & \frac{\partial f_1}{\partial y} \\ \frac{\partial f_2}{\partial x} & \frac{\partial f_2}{\partial y} \end{bmatrix}\] Each row contains the partials of one of the output functions wrt to the variables \(x\) and \(y\). The Jacobian organises the partials of multiple functions by stacking them to provide a matrix that describes the overall sensitivity of the output vector to changes in the input vector.
2.1 The Total Derivative
With the prerequisites covered we can now introduce the concept of the total-derivative. It is important to understand the concept to fully grasp the backpropagation equations presented later on.
We begin by stating the single-variable chain rules applicability for functions like \(f(g(x))\) where the derivative is simply \(f'(g(x)) * g'(x)\), or in other words:
\[\frac{df(g(x))}{dx} = \frac{df}{dg} \frac{dg}{dx}\]
However, what happens if we have a function like \(f(x(t),y(t))\) ?
For this function, we see that small changes in \(t\) affect \(f\) indirectly (through \(x\) and \(y\)) . As the intermediate functions are functions of the same variable we have to account for each change relative to its contribution to the change in \(f\).
To get the gradient of \(f\) wrt to \(t\), the law of total derivatives states that:
\[\frac{df(x(t),y(t))}{dt} = \frac{\partial f}{\partial t}\frac{dt}{dt} + \frac{\partial f}{\partial x}\frac{dx}{dt} + \frac{\partial f}{\partial y}\frac{dy}{dt}\]
In our case, \(f\) is not directly a function of \(t\) so we have \(\frac{df}{dt} \frac{dt}{dt} = 0\).
The equation can be viewed as a weighted sum of the contribution of \(t\) to the overall value of \(f\) through \(x\) and \(y\). That is \(\frac{\partial{f}}{\partial{t}}\), \(\frac{\partial{f}}{\partial{x}}\) and \(\frac{\partial{f}}{\partial{y}}\) can be viewed as weighting the overall contribution of \(t\) with respect to each of the parameters of \(f\).
The derivatives \(\frac{dt}{dt}\), \(\frac{dx}{dt}\) and \(\frac{dy}{dt}\) are ordinary derivatives since each parameter is a function of a single variable \(t\).
Important: If \(x\) was only a function of \(t\) (or \(y\)) the terms involving \(\frac{dy}{dt}\) become \(0\) and thus the total-derivative formulation reduces to the single-variable chain rule.
We can generalise this formula further by representing the parameters \(x\) and \(y\) as components of a vector \(\mathbf{u}\) so that:
\[f(\mathbf{u}(t)) = f(x(t),y(t))\]
Now if we substitute \(u_{n+1}\) as an alias for \(t\) we can write:
\[ \Delta f(\mathbf{u}(t)) = \frac{df}{dt} = \sum^{n+1}_{i = 1} \frac{\partial f}{\partial u_i} \frac{\partial u_i}{\partial t}\]
Notice the subtle difference in notation from the single-variable case. All of the derivatives are shown as partial derivatives because \(f\) and its parameters \(u_i\) are functions of multiple variables.
The summation looks like a vector dot product (or matrix multiplication if \(f\) was a vector function \(\mathbf{f}\)). Using this fact, we can denote the total-derivative in terms of two other Jacobians:
\[\Delta f(\mathbf{u}(t)) = \frac{\partial f}{\partial \mathbf{u}} \frac{\partial \mathbf{u}}{\partial t}\]
where the Jacobian \(\frac{\partial f}{\partial \mathbf{u}}\) is matrix multiplied by the Jacobian \(\frac{\partial \mathbf{u}}{\partial t}\) to produce the total derivative of \(f\) wrt to \(t\). Here the partial derivative notation is necessary because \(\mathbf{u}\) becomes a vector of functions of \(t\).
This formulation is known as the vector chain rule. The beauty is that the vector chain rule takes into consideration the total-derivative while maintaining the same notational simplicity of the single-variable chain rule.
Compare the vector chain rule above to the single-variable chain rule:
\[\Delta f(u(t)) = \frac{df}{du}\frac{du}{dt}\]
and we see the possible reason for some of the confusion.
2.2 Forward pass and some notation
Let’s move on to describing the forward pass in a neural network.
Single neuron output
A neuron’s output \(z\) is a weighted sum of its inputs and a bias term.
Thus we can write:
\[ z = x_{1}w_1 + x_{2}w_2 + \cdots + x_{n}w_n + b = \sum_{i=1}^{n} w_i x_i \]
If we define vectors \(\mathbf{w}\) and \(\mathbf{x}\) to represent each \(w_i\) , \(x_i\) value: \(\mathbf{w} = \begin{bmatrix} w_1 , w_2 , \cdots, w_n \end{bmatrix}\) and \(\mathbf{x} = \begin{bmatrix} x_1 , x_2 , \cdots, x_n \end{bmatrix}\) where \(\mathbf{w}\) is the neurons weight vector and \(\mathbf{x}\) is the vector of its inputs , we can then write the weighted sum as a dot product of the two vectors \(\mathbf{x}\) and \(\mathbf{w}\):
\[z = \mathbf{w} \cdot \mathbf{x} + b\]
An activation function is then applied to the output \(z\) to introduce non-linearity. Let’s denote the output after activation of the neuron as \(a\). Then:
\[a = \sigma(z)\]
where \(\sigma\) denotes the activation function.
Layer output
In practice, a layer contains multiple neurons so that \(z\) is a vector \(\mathbf{z}\), each with its own randomly initialised weight vector.
This means that instead of a vector of weights \(\mathbf{w}\) we have a matrix of weights \(W\), where the rows are given by the number of neurons in the current layer \(i\) and the columns by the number of neurons in the previous layer \(j\).
Important: Input vector \(\mathbf{x}\) would be a matrix \(X\) when considering multiple observations (a batch) for a single pass through our network.
Let’s denote the weights of a layer in matrix form:
\[W = \begin{bmatrix} \mathbf{w}_1 \\ \mathbf{w}_2 \\ \vdots \\ \mathbf{w}_i \end{bmatrix} = \begin{bmatrix} w_{1,1} & w_{1,2} & \cdots & w_{1,j} \\ w_{2,1} & w_{2,2} & \cdots & w_{2,j} \\ \vdots & \vdots & \ddots & \vdots \\ w_{i,1} & w_{i,2} & \cdots & w_{i,j} \end{bmatrix}\]
Note that each \(\mathbf{w}_i\) vector has a set of \(j\) elements corresponding to the number of neurons in the previous layer. This means that \(\mathbf{z}_i\) takes a vector of parameters \(\mathbf{w}_i\) with length \(|j|\).
Then for all the neurons in a layer \(L\) we have a vector \(\mathbf{z}\) where:
\[\mathbf{z}(W,\mathbf{x},\mathbf{b}) = \begin{bmatrix} z_1 \\ z_2 \\ \vdots \\ z_i \end{bmatrix} = \begin{bmatrix} \mathbf{w}_1 . \mathbf{x} + b_1 \\ \mathbf{w}_2 . \mathbf{x} + b_2\\ \vdots \\ \mathbf{w}_i . \mathbf{x} + b_i \end{bmatrix}\]
This can be written succinctly as a matrix multiplication between \(\mathbf{x}\) and \(W\):
\[\mathbf{z}(W,\mathbf{x},\mathbf{b}) = \mathbf{x}W^T + \mathbf{b}\]
It is important to remember that each neuron in a neural network has its own weight vector, so that \({z}_1\) is only a function of \(\mathbf{w}_1\), \(z_2\) of \(\mathbf{w}_2\) and so on.
Important: The vector of inputs \(\mathbf{x}\) is simply the outputs of the neurons from the previous layer (or the number of features for the first layer). Thus for all layers but the input layer: \[\mathbf{x}^l = \mathbf{a}^{l-1}\]
Layer output after activation
Finally, for our network to be able to explain more complex phenomena we introduce non-linearity to a neuron’s output. We do this by applying a nonlinear function over the outputs \(\mathbf{z}\) of the neurons in layer \(l\).
The outputs of a layer \(l\) can then be represented as:
\[\mathbf{a}^{[l]}(\mathbf{z}) = \begin{bmatrix} \sigma(z_1) \\ \sigma(z_2)\\ \vdots \\ \sigma(z_i ) \end{bmatrix} \]
Where the activation function \(\sigma\) is applied element wise to the layers pre-activation output \(\mathbf{z}\).
Consequently, the activation of a layer can then be written as a function of \(W\), \(\mathbf{x}\) and \(\mathbf{b}\):
\[\mathbf{a}^{[l]}(W,\mathbf{x},\mathbf{b}) = \begin{bmatrix} \sigma(\mathbf{w}^{[l]}_1 . \mathbf{x} + b_1) \\ \sigma(\mathbf{w}^{[l]}_2 . \mathbf{x} + b_2)\\ \vdots \\ \sigma(\mathbf{w}^{[l]}_i . \mathbf{x} + b_i) \end{bmatrix}\qquad{(1)}\]
Notice how the output of a layer resembles the vector function \(\mathbf{f}\) from the description of a Jacobian matrix in sec. 2.0.2.
In fact, each layer in a neural net can be seen as a vector function that receives a vector of inputs and maps (transforms) them to an output vector. The dimensionality of the output vector is determined by the number of neurons in that layer.
In other words, each neuron \(i\) takes input vectors \(\mathbf{x}\) and \(\mathbf{w}_i\) and outputs a scalar value \(z_i\), where each neurons output form the elements of the vector output of the layer.
Note: This can be defined as a linear transformation of the inputs or more precisely an affine transformation as it is a linear transformation \(xW^T\) followed by a translation (addition of the \(\mathbf{b}\) term).
Lastly, a desirable characteristic of activation functions, in addition to their non-linear nature, is that their derivatives can be conveniently calculated (often) based on the function’s value itself. This make the calculation of gradients more computationally efficient. We will explore this in detail in sec. 3.2.2.
Now that we understand the basics of the feed-forward mechanism, let’s focus on the derivation of the backpropagation equations.
3 The Gradient of the Cost Function
During backpropagation we are interested in finding the gradient (rate of change) of the cost function with respect to the weights in each layer of our neural net. This will allow us to update the weights in the direction of lower cost after each pass through our neural network. Simply put, since the gradient will tell us the values of the ‘slopes’ that produce greater cost we update the weights in the opposite direction instead to minimise it.

As touched upon earlier, we need to account for the overall change in loss by considering the effect each of the weights and biases in our neural network have on subsequent layers in our network during the forward pass.
We limit our focus on the derivation of the gradient with respect to the weights in this article (extending the concept for the bias terms is trivial once this is grasped – see how the bias term is handled in our implementation).
For our explanation we consider the network shown in fig. 1. We will treat the derivation of the gradients of the weights for the output layer and the hidden layers separately as they require slightly different techniques conceptually.
To get a more intuitive feel of the indirect dependencies involved we begin by denoting the cost as a composite function.
3.1 Cost as a composite function
3.1.1 Final layer
The cost of a network can be viewed as a function of two parameters so that:
\[ C(\mathbf{y},\mathbf{\hat{y}})\]
where \(\mathbf{y}\) is the vector of true labels and \(\mathbf{\hat{y}}\) a vector of our corresponding predictions.
Using our notation as before (eq. 1) and applying them to our neural network in fig. 1 , let \(\mathbf{a}_L\) be a vector of the final layers (\(L\)) outputs, so that:
\[\mathbf{a}_L(W_L,\mathbf{a}_{L-1}) = \begin{bmatrix} \sigma(z_1(\mathbf{w}_1,\mathbf{a}_{L-1})) \\ \sigma(z_2(\mathbf{w}_2,\mathbf{a}_{L-1})) \\ \sigma(z_3(\mathbf{w}_3,\mathbf{a}_{L-1})) \end{bmatrix}\]
Treating \(\mathbf{a}_{L}\) as a vector function as we have, we see that it is a function of two parameters \(W_L\) and \(\mathbf{a}_{L – 1}\) (leaving out the bias term \(\mathbf{b}\)).
Since the activation of the last layer \(L\) is the prediction of our model \(\mathbf{\hat{y}} = \mathbf{a}_L\) we can represent the cost as a composite function of the previous layers activation :
\[C(\mathbf{y},\mathbf{\hat{y}}) = C(\mathbf{y},\mathbf{a}_L(W_L,\mathbf{a}_{L-1}))\qquad{(2)}\]
Expanded this would look like (we omit the superscript \(L\) for the last layer parameters \(z_i\), \(\mathbf{w}_i\)):
\[C(\mathbf{y},\sigma(z_1(\mathbf{w}_1,\mathbf{a}_{L-1})),\sigma(z_2(\mathbf{w}_2,\mathbf{a}_{L-1})),\sigma(z_3(\mathbf{w}_3,\mathbf{a}_{L-1})))\qquad{(3)}\]
In the final layer’s weights, this equation reveals a direct path of influence: each weight vector \(\mathbf{w}_i\) impacts the cost solely through its associated \(z_i\). Consequently, calculating the gradient with respect to these weights primarily requires applying the vector extension of the single-variable chain rule, without the need for the total derivative.
3.1.2 Hidden layer(s)
For the hidden layer(s) we essentially need to look \(l\) layers ‘deeper’ to get the weights of layer \(l\) with respect to the cost. In our example in fig. 1, we have one hidden layer whose outputs are denoted \(\mathbf{a}_{L-1}\).
We can express eq. 2 with the hidden layer weights included:
\[C(\mathbf{y},\mathbf{a}_L(W_L,\mathbf{a}_{L-1}(W_{L-1},\mathbf{a}_{L-2})))\qquad{(4)}\]
Note: We have a single hidden layer in our network so \(\mathbf{a}_{L-2} = \mathbf{x}\), where \(\mathbf{x}\) is a vector of input features.
In eq. 4 we notice that the weights of each neuron in the hidden layer \(L-1\) affect the inputs to each neuron in the final layer \(L\). As a consequence, \(W_{L-1}\) affects the cost \(C\) through multiple paths \(\mathbf{a}_L\).
This inter-dependence necessitates the use of the total-derivative to compute \(\frac{\partial C}{\partial \mathbf{a}_{L-1}}\) and subsequently \(\frac{dC}{dW_{L-1}}\) for each hidden layer \(l\), the values we are actually interested in.
3.2 Finding the gradients
Now that we have a clearer understanding of the functions we need to solve for, we focus on deriving the backpropagation equations and highlighting the different applications of the chain rule that are used. We also cover how the pre-computation of gradients allows us to implement the algorithm. All examples consider a single observation (stochastic gradient descent) to simplify the notation.
3.2.1 Final layer
To reiterate, the task is for us to find the gradient of the cost with respect to all the weights in the weight matrix \(W_{L}\). In our example, this consists of \(15\) (\(i \times j\)) weights in all for the final layer.
We need to find: \[\frac{dC}{dW_L}\]
given the cost equation for the final layers weights in eq. 3.
As we have seen, the total-derivative is not required to calculate the gradient of the cost wrt the final layers’ weights. Here we simply need to use the single-variable chain rule extended to vectors.
Let’s write out the partials (Jacobians) we need, to also help visualise their dimensions:
I.
The gradient of the cost wrt to the predictions of our model \(\mathbf{a}_L\):
\[\frac{\partial C}{\partial \mathbf{a}_{L}} = \begin{bmatrix} \frac{\partial C}{\partial a^{[L]}_{1}} & \frac{\partial C}{\partial a^{[L]}_2} & \frac{\partial C}{\partial a^{[L]}_3} \end{bmatrix}\]
II.
The gradient of the predictions of our model wrt the pre-activation outputs \(\mathbf{a}_L\):
\[\frac{\partial \mathbf{a}_{L}}{\partial \mathbf{z}_{L}} = \begin{bmatrix} \frac{\partial a_1^{[L]}}{\partial z_1^{[L]}} & \frac{\partial a_1^{[L]}}{\partial z_2^{[L]}} & \frac{\partial a_1^{[L]}}{\partial z_3^{[L]}} \\ \frac{\partial a_2^{[L]}}{\partial z_1^{[L]}} & \frac{\partial a_2^{[L]}}{\partial z_2^{[L]}} & \frac{\partial a_2^{[L]}}{\partial z_3^{[L]}} \\ \frac{\partial a_3^{[L]}}{\partial z_1^{[L]}} & \frac{\partial a_3^{[L]}}{\partial z_2^{[L]}} & \frac{\partial a_3^{[L]}}{\partial z_3^{[L]}} \end{bmatrix}\]
Here, the off-diagonal elements go to zero since \(a_k\) is not a function of \(z_i\) when \(i \neq k\) so we have:
\[\frac{\partial \mathbf{a}_{L}}{\partial \mathbf{z}_{L}} = diag(\frac{\partial \mathbf{a}_{L}}{\partial \mathbf{z}_{L}}) = \begin{bmatrix} \frac{\partial a_1^{[L]}}{\partial z_1^{[L]}} & \frac{\partial a_2^{[L]}}{\partial z_2^{[L]}} & \frac{\partial a_3^{[L]}}{\partial z_3^{[L]}}\end{bmatrix}\]
III.
Next, for the pre-activation outputs with respect to the weights \(\frac{\partial \mathbf{z}_L}{\partial W_{L}}\) we have:
\[ \frac{\partial \mathbf{z}_{L}}{\partial W_{L}} = \begin{bmatrix} \frac{\partial z_1^{[L]}}{\partial \mathbf{w_1}^{[L]}} \\ \frac{\partial z_2^{[L]}}{\partial \mathbf{w_2}^{[L]}} \\ \frac{\partial z_3^{[L]}}{\partial \mathbf{w_3}^{[L]}} \end{bmatrix} = \begin{bmatrix}\frac{\partial z_1^{[L]}}{\partial w_{11}^{[L]}} & \frac{\partial z_1^{[L]}}{\partial w_{12}^{[L]}} & \frac{\partial z_1^{[L]}}{\partial w_{13}^{[L]}} & \frac{\partial z_1^{[L]}}{\partial w_{14}^{[L]}} & \frac{\partial z_1^{[L]}}{\partial w_{15}^{[L]}} \\ \frac{\partial z_2^{[L]}}{\partial w_{21}^{[L]}} & \frac{\partial z_2^{[L]}}{\partial w_{22}^{[L]}} & \frac{\partial z_2^{[L]}}{\partial w_{23}^{[L]}} & \frac{\partial z_2^{[L]}}{\partial w_{24}^{[L]}} & \frac{\partial z_2^{[L]}}{\partial w_{25}^{[L]}} \\\frac{\partial z_3^{[L]}}{\partial w_{31}^{[L]}} & \frac{\partial z_3^{[L]}}{\partial w_{32}^{[L]}} & \frac{\partial z_3^{[L]}}{\partial w_{33}^{[L]}} & \frac{\partial z_3^{[L]}}{\partial w_{34}^{[L]}} & \frac{\partial z_3^{[L]}}{\partial w_{35}^{[L]}} \end{bmatrix}\]
Each column corresponds to a weight vector connecting a neuron \(j\) from the previous layer to neurons \(i\) in the current layer.
IV.
Finally, to find the intermediate partial \(\frac{\partial C}{\partial \mathbf{z}_L}\) we need to perform an element-wise multiplication between \(\frac{dC}{d\mathbf{a}_L}\) and \(\frac{d\mathbf{a}_L}{d\mathbf{z}_L}\) as all we need is the single-variable chain rule. This is because there are no indirect dependencies between layers to account for :
\[\frac{\partial C}{\partial \mathbf{z}_L} = \frac{\partial C}{\partial \mathbf{a}_L} * \frac{\partial \mathbf{a}_L}{\partial \mathbf{z}_L} = \begin{bmatrix} \frac{\partial C}{\partial a^{[L]}_{1}} & \frac{\partial C}{\partial a^{[L]}_2} & \frac{\partial C}{\partial a^{[L]}_3} \end{bmatrix} * \begin{bmatrix} \frac{\partial a_1^{[L]}}{\partial z_1^{[L]}} & \frac{\partial a_2^{[L]}}{\partial z_2^{[L]}} & \frac{\partial a_3^{[L]}}{\partial z_3^{[L]}}\end{bmatrix} \]
Now that we have found our partials we can use the chain rule for vectors to express the Jacobian we are interested in:
\[\frac{dC}{dW_{L}} = (\frac{\partial C}{\partial \mathbf{a}_L} * \frac{\partial \mathbf{a}_L}{\partial \mathbf{z}_L}) \otimes \frac{\partial \mathbf{z}_L}{\partial W_{L}} = \frac{\partial C}{\partial \mathbf{z}_{L}} \otimes \frac{\partial \mathbf{z}_{L}}{\partial W_{L}} = \begin{bmatrix} \frac{\partial C}{\partial z_1^{[L]}} \frac{\partial z_1^{[L]}}{\partial w_{11}^{[L]}} & \frac{\partial C}{\partial z_2^{[L]}} \frac{\partial z_2^{[L]}}{\partial w_{21}^{[L]}} & \frac{\partial C}{\partial z_3^{[L]}} \frac{\partial z_3^{[L]}}{\partial w_{31}^{[L]}} \\ \frac{\partial C}{\partial z_1^{[L]}} \frac{\partial z_1^{[L]}}{\partial w_{12}^{[L]}} & \frac{\partial C}{\partial z_2^{[L]}} \frac{\partial z_2^{[L]}}{\partial w_{22}^{[L]}} & \frac{\partial C}{\partial z_3^{[L]}} \frac{\partial z_3^{[L]}}{\partial w_{32}^{[L]}} \\ \frac{\partial C}{\partial z_1^{[L]}} \frac{\partial z_1^{[L]}}{\partial w_{13}^{[L]}} & \frac{\partial C}{\partial z_2^{[L]}} \frac{\partial z_2^{[L]}}{\partial w_{23}^{[L]}} & \frac{\partial C}{\partial z_3^{[L]}} \frac{\partial z_3^{[L]}}{\partial w_{33}^{[L]}} \\ \frac{\partial C}{\partial z_1^{[L]}} \frac{\partial z_1^{[L]}}{\partial w_{14}^{[L]}} & \frac{\partial C}{\partial z_2^{[L]}} \frac{\partial z_2^{[L]}}{\partial w_{24}^{[L]}} & \frac{\partial C}{\partial z_3^{[L]}} \frac{\partial z_3^{[L]}}{\partial w_{34}^{[L]}} \\ \frac{\partial C}{\partial z_1^{[L]}} \frac{\partial z_1^{[L]}}{\partial w_{15}^{[L]}} & \frac{\partial C}{\partial z_2^{[L]}} \frac{\partial z_2^{[L]}}{\partial w_{25}^{[L]}} & \frac{\partial C}{\partial z_3^{[L]}} \frac{\partial z_3^{[L]}}{\partial w_{35}^{[L]}} \end{bmatrix}^T\]
We will explain the choice of operators soon. For now, focus on the complexity of the calculation.
For a simple network like we have, we would need to compute the values of all the required partials to get the gradient of the cost wrt the weights of the final layer. We would then need to repeat the process for the hidden layers weights. Additionally, during training we typically pass many batches of data through our network. For each batch, we need to perform a forward pass to calculate the cost and a backward pass to compute the gradients.
As network size grows, the computational burden quickly escalates to an impractical level. A key simplification arises from the fact that we can express these partial derivatives using values we have already determined.
3.2.2 Pre-computation of gradients
First, lets try to derive the partial of the weights wrt a single neuron output \(z_i\) and then see if we can extend this to a vector of outputs \(\mathbf{z}\). We omit the bias term to focus on the derivative of the dot-product operation:
\[z_i = \mathbf{w}_{i}^{[L]} \cdot \mathbf{a}^{[L-1]} = \sum_{k=1}^{n} (w_k a_k)\]
Notice how we don’t index \(\mathbf{a^{[l-1]}}\) this is because all \(z_i\) in the current layer share the same input vector, what changes are the weight and bias vectors between each \(z_i\).
Then the derivative of \(z_i\) wrt to a specific weight \(w_j\) is:
\[\frac{\partial z_i}{\partial w_j} = \sum_{k=1}^{n}\frac{\partial}{\partial w_j} (w_k a_k) = a_j\]
The summation disappears because \(\frac{\partial}{\partial w_j} w_k a_k\) reduces to a constant when \(j \neq k\), the derivative of which is \(0\).
Since the result is a scalar value when \(w\) is scalar, to extend this to a vector of \(\mathbf{w}_i\) we simply have:
\[\frac{\partial z_i}{\partial \mathbf{w}_i} = \begin{bmatrix} a_1^{[L-1]} & a_2^{[L-1]} & a_3^{[L-1]} & a_4^{[L-1]} & a_5^{[L-1]} \end{bmatrix} = \mathbf{a}^{[L-1]} \]
That’s a significantly easier computation as the activations have already been computed during the forward pass. This also means the gradients are shared across each \(z_i\). Instead of having to find \(15\) individual partials we just need to find \(5\) that have already been computed!
This result tells us that the gradient of the pre-activation output (\(z_i\)) of a neuron \(i\) wrt \(w_{ij}\) is the activation of the neuron \(j\) the weight originates from. This makes sense as the gradient of \(z_i\) with respect to \(w_{kj}\) is \(0\) when \(k \neq i\) so the partials should simply be a vector of length \(|j|\) for each \(z_i\).
Each column of this matrix conceptually represents how much a small change in the weights in \(\mathbf{w}_i\) affects the output \(z_i\). To get the effect the change has on the cost \(C\) we will need to use the chain rule.
Now we can write:
\[\frac{\partial C}{\partial W_{L}} = \frac{\partial C}{\partial \mathbf{z}_{L}}^T \otimes \mathbf{a}_{L-1} = \begin{bmatrix} \frac{\partial C}{\partial z^{[L]}_{1}} \\ \frac{\partial C}{\partial z^{[L]}_2} \\ \frac{\partial C}{\partial z^{[L]}_3} \end{bmatrix} \otimes \begin{bmatrix} a_1^{[L-1]} & a_2^{[L-1]} & a_3^{[L-1]} & a_4^{[L-1]} & a_5^{[L-1]} \end{bmatrix}\]
Thus, the derivative of the cost (the loss of our network) with respect to matrix \(W_L\) (through intermediate variables z) is a square matrix with elements computed using the outer product. We explicitly use the outer-product to indicate the operation does not use the total-derivative chain rule that the matrix-product operation introduces for the gradients of the hidden layer weights later on (eq. 5).
Important: A matrix multiplication between the partials \(\frac{\partial C}{\partial \mathbf{z}_{L}} \frac{\partial \mathbf{z}_{L}}{\partial W_{L}}\) is common when considering multiple observations (batch). This effectively sums along the partials for each observation to get a total contribution to the overall loss. The matrix product is not used to compute the total derivative in this case!
If we were to expand this operation for clarity, the complete Jacobian would look like:
\[\frac{dC}{dW_{L}} = \begin{bmatrix} \frac{\partial C}{\partial z^{[L]}_{1}} a_1^{[L-1]} & \frac{\partial C}{\partial z^{[L]}_{1}} a_2^{[L-1]} & \frac{\partial C}{\partial z^{[L]}_{1}} a_3^{[L-1]} & \frac{\partial C}{\partial z^{[L]}_{1}} a_4^{[L-1]} & \frac{\partial C}{\partial z^{[L]}_{1}} a_5^{[L-1]} \\ \frac{\partial C}{\partial z^{[L]}_{2}} a_1^{[L-1]} & \frac{\partial C}{\partial z^{[L]}_{2}} a_2^{[L-1]} & \frac{\partial C}{\partial z^{[L]}_{2}} a_3^{[L-1]} & \frac{\partial C}{\partial z^{[L]}_{2}} a_4^{[L-1]} & \frac{\partial C}{\partial z^{[L]}_{2}} a_5^{[L-1]} \\ \frac{\partial C}{\partial z^{[L]}_{3}} a_1^{[L-1]} & \frac{\partial C}{\partial z^{[L]}_{3}} a_2^{[L-1]} & \frac{\partial C}{\partial z^{[L]}_{3}} a_3^{[L-1]} & \frac{\partial C}{\partial z^{[L]}_{3}} a_4^{[L-1]} & \frac{\partial C}{\partial z^{[L]}_{3}} a_5^{[L-1]} \end{bmatrix}\]
Further, since the cost and activation functions are known and predetermined, the partial \(\frac{\partial C}{\partial \mathbf{z}_L}\) can usually be expressed in terms of the activation function and the true labels themselves. For example, the derivative of the cost wrt its pre-activation inputs \(\mathbf{z}_L\) is simply \(\mathbf{a}_L – \mathbf{y}\) when using a softmax activation over the final layer (given \(\mathbf{y}\) is a one-hot encoded vector of true labels and the cost function \(C\) is the cross-entropy loss).
The gradient of the weights of the final layer wrt the cost can then be expressed as a series of matrix operations betweeen the Jacobians:
\[\frac{dC}{dW_L} = (\frac{\partial C}{\partial \mathbf{a}_L} * \frac{\partial \mathbf{a}_L}{\partial \mathbf{z}_L}) \otimes \frac{\partial \mathbf{z}_L}{\partial W_{L}} \]
3.2.3 Hidden layer(s)
Recall the cost written as a composite equation in eq. 4. We saw that for each layer’s weight gradients we need to iteratively solve the nested composite function until we reach the input layer.
Let’s visualise the Jacobians we need to solve for layer \(L-1\) weights.
We’ve already written out the value of \(\frac{\partial C}{\partial \mathbf{z}_{L}}\) earlier.
I.
For the pre-activation outputs \(\mathbf{z}_{L}\) wrt inputs \(\mathbf{a}_{L -1}\) we have:
\[\frac{\partial \mathbf{z}_{L}}{\partial \mathbf{a}_{L-1}} = \begin{bmatrix} \frac{\partial z_1^{[L]}}{\partial a_1^{[L-1]}} & \frac{\partial z_1^{[L]}}{\partial a_2^{[L-1]}} & \frac{\partial z_1^{[L]}}{\partial a_3^{[L-1]}} & \frac{\partial z_1^{[L]}}{\partial a_4^{[L-1]}} & \frac{\partial z_1^{[L]}}{\partial a_5^{[L-1]}} \\ \frac{\partial z_2^{[L]}}{\partial a_1^{[L-1]}} & \frac{\partial z_2^{[L]}}{\partial a_2^{[L-1]}} & \frac{\partial z_2^{[L]}}{\partial a_3^{[L-1]}} & \frac{\partial z_2^{[L]}}{\partial a_4^{[L-1]}} & \frac{\partial z_2^{[L]}}{\partial a_5^{[L-1]}} \\ \frac{\partial z_3^{[L]}}{\partial a_1^{[L-1]}} & \frac{\partial z_3^{[L]}}{\partial a_2^{[L-1]}} & \frac{\partial z_3^{[L]}}{\partial a_3^{[L-1]}} & \frac{\partial z_3^{[L]}}{\partial a_4^{[L-1]}} & \frac{\partial z_3^{[L]}}{\partial a_5^{[L-1]}} \end{bmatrix}\]
Using the same process of differentiation as we did for \(\frac{\partial z}{\partial \mathbf{w}}\) earlier, the derivative of \(\mathbf{z}_l\) wrt its inputs is simply given by the layer \(l\) weight matrix :
\[\frac{\partial \mathbf{z}_{L}}{\partial \mathbf{a}_{L-1}} = W_{L} = \begin{bmatrix} w_{11} & w_{12} & w_{13} & w_{14} & w_{15} \\ w_{21} & w_{22} & w_{23} & w_{24} & w_{25} \\ w_{31} & w_{32} & w_{33} & w_{34} & w_{35} \end{bmatrix}\]
II.
Next, we find the intermediate partial \(\frac{\partial C}{\partial \mathbf{a}_{L-1}}\) (which will tell us how the hidden layers outputs affect the final cost):
The reason the computation differs from the final layer is that each \(z^{[L]}_i\) receives all \(a^{[L-1]}_j\) as inputs.
As a consequence, to find the intermediate partial \(\frac{\partial C}{\partial \mathbf{a}_{L-1}}\) using the Jacobians \(\frac{\partial C}{\partial \mathbf{z}_{L}}, \frac{\partial \mathbf{z}_{L}}{\partial \mathbf{a}_{L-1}}\) we must consider how each activation \(a_j\) in layer \(L-1\) influences the cost through its contribution to each \(a_i\) in the final layer \(L\) (through \(z_i^L\)).
This means (as mentioned in sec. 3.1.2) we need the total derivative to find the intermediate partial \(\frac{\partial C}{\partial \mathbf{a}_{L-1}}\).
Since we know the total-derivative can be expressed as a matrix product, the calculation of \(\frac{\partial C}{\partial \mathbf{a}_{L-1}}\) can be written explicitly as:
\[ \frac{\partial C}{\partial \mathbf{a}_{L-1}} = \frac{\partial C}{\partial \mathbf{z}_{L}} \frac{\partial \mathbf{z}_{L}}{\partial \mathbf{a}_{L-1}} = \frac{\partial C}{\partial \mathbf{z}_{L}} W_{L} = \begin{bmatrix} \frac{\partial C}{\partial z_1^{[L]}} w_{11} + \frac{\partial C}{\partial z_2^{[L]}} w_{21} + \frac{\partial C}{\partial z_3^{[L]}} w_{31} \\ \frac{\partial C}{\partial z_1^{[L]}} w_{12} + \frac{\partial C}{\partial z_2^{[L]}} w_{22} + \frac{\partial C}{\partial z_3^{[L]}} w_{32} \\ \frac{\partial C}{\partial z_1^{[L]}} w_{13} + \frac{\partial C}{\partial z_2^{[L]}} w_{23} + \frac{\partial C}{\partial z_3^{[L]}} w_{33} \\ \frac{\partial C}{\partial z_1^{[L]}} w_{14} + \frac{\partial C}{\partial z_2^s{[L]}} w_{24} + \frac{\partial C}{\partial z_3^{[L]}} w_{34} \\ \frac{\partial C}{\partial z_1^{[L]}} w_{15} + \frac{\partial C}{\partial z_2^{[L]}} w_{25} + \frac{\partial C}{\partial z_3^{[L]}} w_{35} \end{bmatrix}^T\qquad{(5)}\]
We now have the dependency ‘graph’ for the influence a small change in the activations of the hidden layer \(\mathbf{a}_{L-1}\) have on the cost.
III.
For the derivative of the hidden layers activations \(a_i^{L-1}\) wrt its pre-activation outputs \(z_i^{L-1}\) we need to first define an activation function. We use a ReLU activation, defined as:
\[\sigma_{ReLU} = max(0,z_i^{L-1})\]
Then the derivative of the activation wrt to the pre-activation inputs of layer \(L-1\) is a matrix of \(1\)’s and \(0\)’s: \[ \frac{\partial \mathbf{a}_{L-1}}{\partial \mathbf{z}_{L-1}} = \sigma_{ReLU}'(z_i^{L-1}) = \begin{cases} 1 & \text{if } z_i^{L-1} > 0 \\ 0 & \text{if } z_i^{L-1} \leq 0 \end{cases}\]
IV.
From before we know the gradient of the weights of a layer wrt its pre-activation outputs is simply the layers inputs. Since we have a single hidden layer the inputs to it are the models input features \(\mathbf{x}\):
\[\frac{\partial \mathbf{z}_{L-1}}{\partial W_{L-1}} = \mathbf{x}\]
Now that we have found our Jacobians, all that’s left do is multiply out the corresponding partials using the single variable chain-rule extended to vectors. This is because the total-derivative calculation in step II has already accounted for the indirect inter-layer dependencies. We now only need to focus on the ‘local’ derivatives within the hidden layer.
Finally, we can represent the gradient of the cost wrt the weights in our hidden layer as a series of matrix operations:
\[ \frac{dC}{dW_{L-1}} = \frac{\partial C}{\partial \mathbf{z}_{L}}\frac{\partial \mathbf{z}_{L}}{\partial \mathbf{a}_{L-1}} * \frac{\partial \mathbf{a}_{L-1}}{\partial \mathbf{z}_{L-1}} \otimes \frac{\partial \mathbf{z}_{L-1}}{\partial W_{L-1}} = ( \frac{\partial C}{\partial \mathbf{z}_{L}}W_{L} * \frac{\partial \mathbf{a}_{L-1}}{\partial \mathbf{z}_{L-1}} ) \otimes \mathbf{x} \]
which can be written simply as:
\[\frac{dC}{dW_{L-1}} = \frac{\partial C}{\partial \mathbf{z}_{L-1}} \otimes \mathbf{x}\]
By caching the value of the intermediate partial \(\frac{\partial C}{\partial \mathbf{z}_{L – l}}\) for all hidden layers \(l\) we can recursively apply this method to each hidden layers weights.
Notice again how closely this resembles the simple single-variable chain rule if the operators between the Jacobians were not written out explicitly. The form of the equation is similar because the matrix product operation takes into account the total derivative in its computation.
4 Conclusion
In this article, we have demonstrated how the common representation of the single-variable chain rule, as applied to the backpropagation equations, is misleading or incorrect. We highlighted the necessity of using the total-derivative (a more general form of the chain rule) due to the composite nature of the backpropagation equations we are solving and explained how the vector chain rule implements this total derivative through matrix operations.
Furthermore, we explored why the different chain rules are often conflated in explanations. Several factors contribute to this confusion:
- The vector chain rule employs notation that resembles the single-variable chain rule.
- In many specific instances, such as when determining the weights of the final layer (as discussed in sec. 3.2.1), the vector chain rule simplifies to the single-variable chain rule.
- The use of matrix multiplication to aggregate gradients from a batch of observations contrasts with its role in implementing the total derivative in other parts of the backpropagation equations.
These factors make it challenging to consistently identify which chain rule is being applied.
Beyond addressing the confusion, our derivation also revealed the key ideas that make the backpropagation equations tractable:
- The matrix product operation between Jacobians takes into account the total derivative.
- Computation is largely unnecessary for the required partials:
- the gradient of the weighted sum of a layer wrt its inputs is simply given by the layers weight matrix.
- similarly, the gradient of the weighted sum of a layer wrt its weights is given by the previous layers activation.
- an activation function is chosen so that the gradient of the output of a layer \(\mathbf{a}_L\) wrt to its pre-activation output \(\mathbf{z}_L\) can often be expressed in terms of the activation function itself.
- Calculations involved in finding the gradient of the cost wrt a layers weights helps us find the gradient of the cost with respect to the previous layers weights until we reach the input layer. Like this, backpropagation recursively finds the gradients for each layer.
These ideas simplify the math and indeed make backpropagation computationally possible!
Finally, to verify our understanding we implemented our own neural net in numpy and trained it to classify species of iris given its sepal and petal length and width. You can try it out yourself in this colab notebook.
The post The Total Derivative: Correcting the Misconception of Backpropagation’s Chain Rule appeared first on Towards Data Science.



