




































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)







































































































































































































































.png?#)


































.webp?#)
.webp?#)

.webp?#)






















































































![[Fixed] Gemini app is failing to generate Audio Overviews](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/03/Gemini-Audio-Overview-cover.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)

![What’s new in Android’s April 2025 Google System Updates [U: 4/14]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-3.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













![Apple Seeds tvOS 18.5 Beta 2 to Developers [Download]](https://www.iclarified.com/images/news/97011/97011/97011-640.jpg)
![Apple Releases macOS Sequoia 15.5 Beta 2 to Developers [Download]](https://www.iclarified.com/images/news/97014/97014/97014-640.jpg)



















































































































How to Optimize Search Queries in Large Databases with PostgreSQL and GIN Indexes
In this article, I’m going to show you an easy and safe way to speed up search queries in large database sets using PostgreSQL. To demonstrate the process, I’ll use a common use case where you want to search through a database to find records that match a specific term. Repository link: https://github.com/venuziano/high-performance-search-large-set-database Let’s consider the following scenario as an example: Library admins want to search for books in a database that match a specific title or category. Their database contains over 2 million book records, with each book associated with 10 distinct categories (resulting in 20 million book-category relations). There are 100 categories in total. To start, we can use a simple endpoint, which returns a list of books with their categories. Here’s the documentation in Swagger: This endpoint has pagination, sort and filter functionalities. I used the URL below in Postman, but it will also work in Swagger, Curl and other API tools: /book/get/all?filter=romance&limit=50&page=1&order=ASC&sort=updated_at Next, we need to generate the database schema and the dataset. To do so, we can use migrations that execute SQL queries and procedures to save time. If you have a look at the folder migrations in the repository, it contains five migration files: the first file creates the book, category and book_categories database tables; the second, third and fourth files create the procedures that insert data into the database; and the last file creates the database indexes. The book data (name, author, publisher, etc.) and category names are randomly generated from a predefined list in the migration files. Check them for more details if you would like to understand what’s happening in the background. Now, for testing purposes, let’s use the search terms “special book”, “category” and “romance”. When searching for “special book”, the endpoint returns 7 results among 20 millions records within 300 ms: Searching for “category”, the endpoint returns 1 result within 800 ms: Finally, when searching for “romance”, the endpoint returns around 1.2 million results within 3.5 seconds: From the results, we can see that the search performance was good, despite the large amount of records in the database. This is because, instead of using built-in ORM methods and multi-table JOINs in the SELECT query, I used the following raw SELECT query to fetch data (as we have pagination, we need to do the same for the COUNT query): ` SELECT *, ( SELECT jsonb_agg(jsonb_build_object('category', to_jsonb(c.*))) FROM book_categories bc JOIN category c ON c.id = bc.category_id WHERE bc.book_id = b.id ) AS "bookCategories" FROM ( SELECT * FROM book b WHERE to_tsvector('english', coalesce(b.name, '') || ' ' || coalesce(b.author, '') || ' ' || coalesce(b.publisher, '')) @@ to_tsquery('english', $1) UNION SELECT * FROM book b WHERE EXISTS ( SELECT 1 FROM book_categories bc JOIN category c ON c.id = bc.category_id WHERE bc.book_id = b.id AND to_tsvector('english', c.name) @@ to_tsquery('english', $1) ) ) b ORDER BY b.${sortField} ${sortOrder} LIMIT $2 OFFSET $3; ` This is the key to achieving such high performance, although results may vary depending on your machine hardware and how many fields in the database need to be scanned with the inputted search term. Key takeaways: In my example, I used the jsonb_agg aggregate function to fetch the category data in a JSON format: We use the aggregate function to group related data into one field, reducing the number of JOINs and simplifying how nested data is returned to the application. The SELECT query also uses to_tsvector to convert text data into a searchable format using GIN indexes. This speeds up full-text searches by allowing the database to quickly filter out non-matching rows instead of scanning each row with pattern matching. The UNION operator combines two search conditions: one that directly searches the book’s own text fields and another that searches within its related categories. UNION inherently removes duplicates, so this optimizes each subquery to ensure that you only retrieve relevant book data. Given these points, we can see that this is an efficient query because the database handles complex data transformations—for example, using the jsonb_agg aggregate function—, which leverages full-text search optimizations and combines results efficiently using the UNION operator. (If you were to use regular JOINs and indexes without the listed key points, SELECT and COUNT queries would take more than 15 seconds to fetch records.) Moreover, this approach can be used for other use cases as well, such as to search for customer information and their software licenses, specific items in a store, stock names in a user’s trading history, etc.—just customize the quer
In this article, I’m going to show you an easy and safe way to speed up search queries in large database sets using PostgreSQL. To demonstrate the process, I’ll use a common use case where you want to search through a database to find records that match a specific term.
Repository link: https://github.com/venuziano/high-performance-search-large-set-database
Let’s consider the following scenario as an example:
- Library admins want to search for books in a database that match a specific title or category.
- Their database contains over 2 million book records, with each book associated with 10 distinct categories (resulting in 20 million book-category relations).
- There are 100 categories in total.
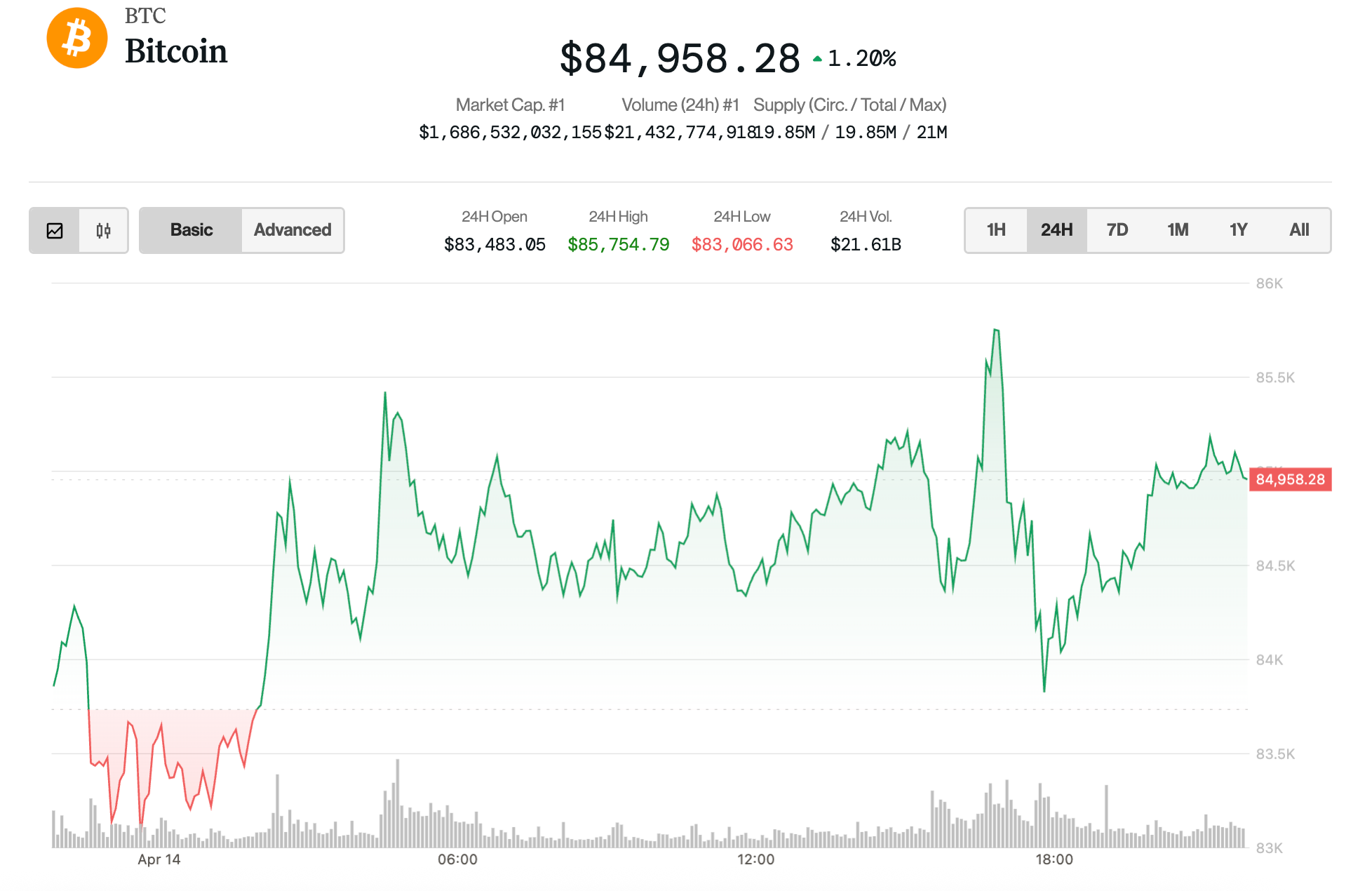
To start, we can use a simple endpoint, which returns a list of books with their categories. Here’s the documentation in Swagger:
This endpoint has pagination, sort and filter functionalities. I used the URL below in Postman, but it will also work in Swagger, Curl and other API tools:
/book/get/all?filter=romance&limit=50&page=1&order=ASC&sort=updated_at
Next, we need to generate the database schema and the dataset. To do so, we can use migrations that execute SQL queries and procedures to save time. If you have a look at the folder migrations in the repository, it contains five migration files: the first file creates the book, category and book_categories database tables; the second, third and fourth files create the procedures that insert data into the database; and the last file creates the database indexes. The book data (name, author, publisher, etc.) and category names are randomly generated from a predefined list in the migration files. Check them for more details if you would like to understand what’s happening in the background.
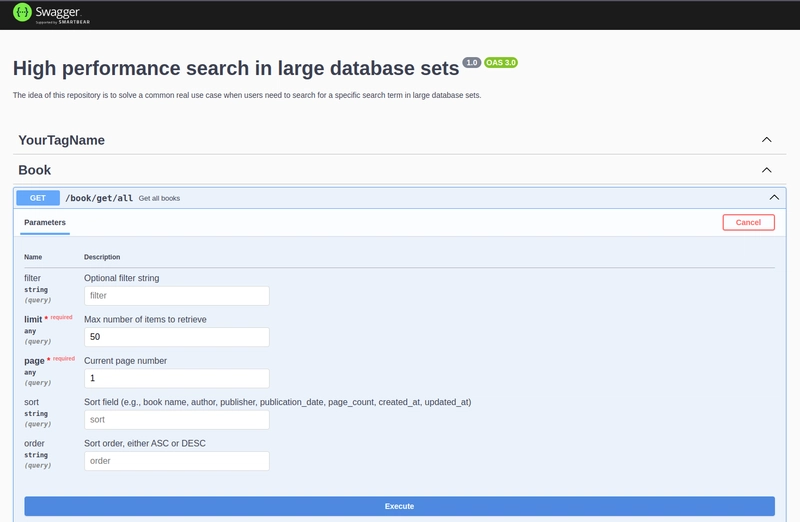
Now, for testing purposes, let’s use the search terms “special book”, “category” and “romance”. When searching for “special book”, the endpoint returns 7 results among 20 millions records within 300 ms:
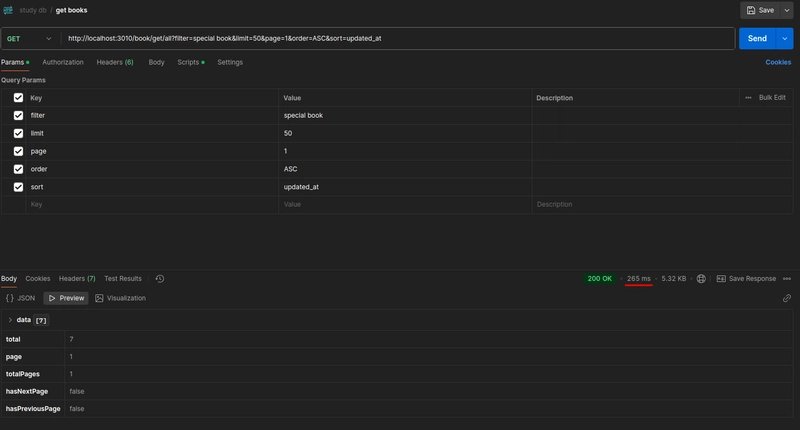
Searching for “category”, the endpoint returns 1 result within 800 ms:
Finally, when searching for “romance”, the endpoint returns around 1.2 million results within 3.5 seconds:
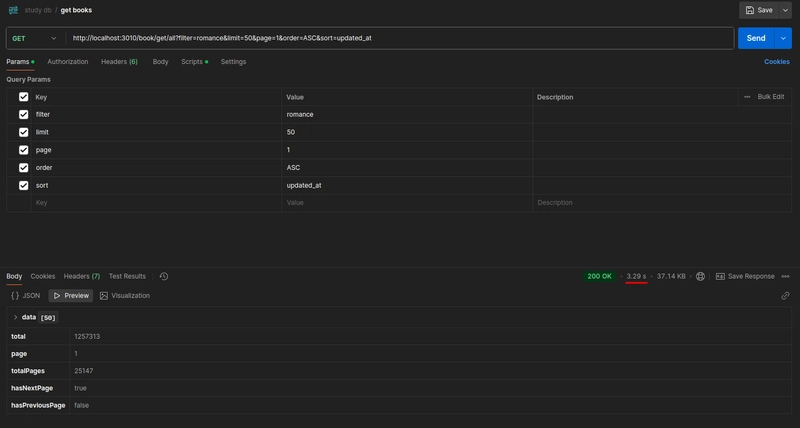
From the results, we can see that the search performance was good, despite the large amount of records in the database. This is because, instead of using built-in ORM methods and multi-table JOINs in the SELECT query, I used the following raw SELECT query to fetch data (as we have pagination, we need to do the same for the COUNT query):
`
SELECT
*,
(
SELECT jsonb_agg(jsonb_build_object('category', to_jsonb(c.*)))
FROM book_categories bc
JOIN category c ON c.id = bc.category_id
WHERE bc.book_id = b.id
) AS "bookCategories"
FROM (
SELECT
*
FROM book b
WHERE to_tsvector('english', coalesce(b.name, '') || ' ' || coalesce(b.author, '') || ' ' || coalesce(b.publisher, ''))
@@ to_tsquery('english', $1)
UNION
SELECT
*
FROM book b
WHERE EXISTS (
SELECT 1
FROM book_categories bc
JOIN category c ON c.id = bc.category_id
WHERE bc.book_id = b.id
AND to_tsvector('english', c.name) @@ to_tsquery('english', $1)
)
) b
ORDER BY b.${sortField} ${sortOrder}
LIMIT $2 OFFSET $3;
`
This is the key to achieving such high performance, although results may vary depending on your machine hardware and how many fields in the database need to be scanned with the inputted search term.
Key takeaways:
- In my example, I used the
jsonb_aggaggregate function to fetch the category data in a JSON format: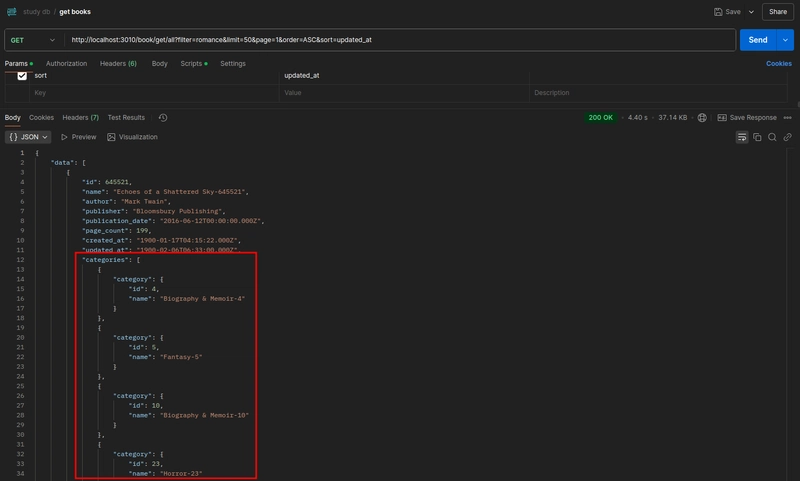 We use the aggregate function to group related data into one field, reducing the number of JOINs and simplifying how nested data is returned to the application.
We use the aggregate function to group related data into one field, reducing the number of JOINs and simplifying how nested data is returned to the application. - The SELECT query also uses
to_tsvectorto convert text data into a searchable format using GIN indexes. This speeds up full-text searches by allowing the database to quickly filter out non-matching rows instead of scanning each row with pattern matching. - The UNION operator combines two search conditions: one that directly searches the book’s own text fields and another that searches within its related categories. UNION inherently removes duplicates, so this optimizes each subquery to ensure that you only retrieve relevant book data.
Given these points, we can see that this is an efficient query because the database handles complex data transformations—for example, using the jsonb_agg aggregate function—, which leverages full-text search optimizations and combines results efficiently using the UNION operator. (If you were to use regular JOINs and indexes without the listed key points, SELECT and COUNT queries would take more than 15 seconds to fetch records.) Moreover, this approach can be used for other use cases as well, such as to search for customer information and their software licenses, specific items in a store, stock names in a user’s trading history, etc.—just customize the query above according to your needs. That said, in order to avoid SQL injection, remember to always use query parameters and sanitize user input values.
I encourage you to test this repository on your own. You can clone the repository, set up an .env file and execute the command docker compose up --build -d (refer to the Readme file for more details if necessary). The first initialization may take a few minutes due to the procedure that inserts the 20 million records into the book_categories table. This is what your Docker logs should look like when all the procedures have been executed:
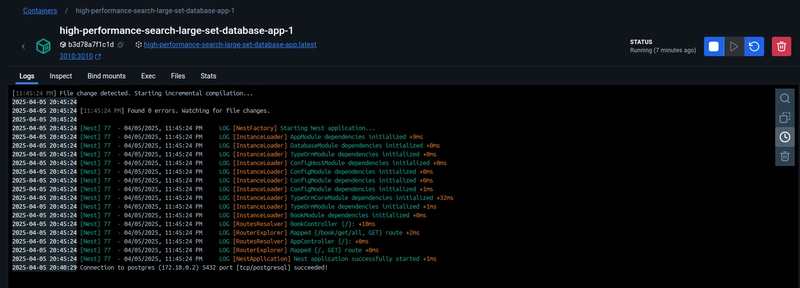
On a related note, have you ever needed to implement pagination, sort and filter functionalities using a large database set? If yes, was your implementation efficient?