

































-Reviewer-Photo-SOURCE-Julian-Chokkattu-(no-border).jpg)





















































































































![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)

































































































































![Life in Startup Pivot Hell with Ex-Microsoft Lonewolf Engineer Sam Crombie [Podcast #171]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746753508177/0cd57f66-fdb0-4972-b285-1443a7db39fc.png?#)




























































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)


















































-Nintendo-Switch-2-Hands-On-Preview-Mario-Kart-World-Impressions-&-More!-00-10-30.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)

























_Andrey_Khokhlov_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


_Aleksey_Funtap_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)





















































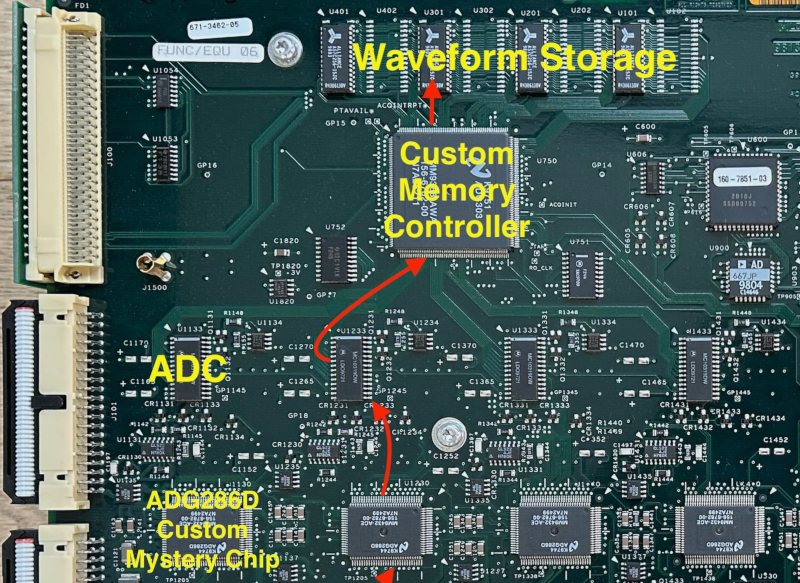





















































![Apple Foldable iPhone to Feature New Display Tech, 19% Thinner Panel [Rumor]](https://www.iclarified.com/images/news/97271/97271/97271-640.jpg)
![Apple Developing New Chips for Smart Glasses, Macs, AI Servers [Report]](https://www.iclarified.com/images/news/97269/97269/97269-640.jpg)
![Apple Shares New Mother's Day Ad: 'A Gift for Mom' [Video]](https://www.iclarified.com/images/news/97267/97267/97267-640.jpg)

































































![[Weekly funding roundup May 3-9] VC inflow into Indian startups touches new high](https://images.yourstory.com/cs/2/220356402d6d11e9aa979329348d4c3e/WeeklyFundingRoundupNewLogo1-1739546168054.jpg)


























Enhancing AI retrieval with HNSW in RAG applications
This tutorial was originally published on IBM Developer by Niranjan Khedkar Retrieval-Augmented Generation(RAG) improves how AI models find and generate relevant information, making responses more accurate and useful. However, as data grows, fast and efficient retrieval becomes essential. Traditional search methods such as brute-force similarity search, are slow and do not scale well. Hierarchical Navigable Small World (HNSW) is a graph-based Approximate Nearest Neighbor (ANN) search algorithm that offers high speed and scalability, making it a great fit for RAG systems. This tutorial explores how HNSW enhances retrieval in AI applications, particularly within IBM’s AI solutions. This tutorial also provides a step-by-step implementation guide and discusses optimizations for large-scale use. Why HNSW is ideal for RAG Efficient retrieval is key to AI-driven applications. Large-scale knowledge systems need high accuracy, low latency, and scalability. HNSW meets these needs by offering: Speed and scalability: Finds results quickly, even with millions of documents. High recall and accuracy: Outperforms other ANN methods such as LSH and IVFPQ. Efficient memory use: Balances performance with resource efficiency. Real-time updates: Supports adding and removing data dynamically. HNSW is ideal for AI chatbots, enterprise search, recommendation engines, and domain-specific assistants. By using HNSW, developers can improve both speed and precision in RAG applications. How to use HNSW in a RAG pipeline A RAG pipeline typically has four main stages: Document processing and embedding - Convert text documents into vector embeddings using models such as IBM watsonx.ai or Hugging Face Transformers. Indexing with HNSW – Store embeddings in an HNSW index for fast nearest-neighbor search. Retrieval and augmentation – Use HNSW to find the most relevant documents for a given query. Response generation – Feed retrieved data into an LLM (for example, IBM Granite) to generate a response. Replacing traditional search methods with HNSW significantly improves retrieval speed and accuracy in RAG applications. Implementing HNSW for RAG in Python Step 1. Install required libraries Continue reading on IBM Developer
This tutorial was originally published on IBM Developer by Niranjan Khedkar
Retrieval-Augmented Generation(RAG) improves how AI models find and generate relevant information, making responses more accurate and useful. However, as data grows, fast and efficient retrieval becomes essential. Traditional search methods such as brute-force similarity search, are slow and do not scale well.
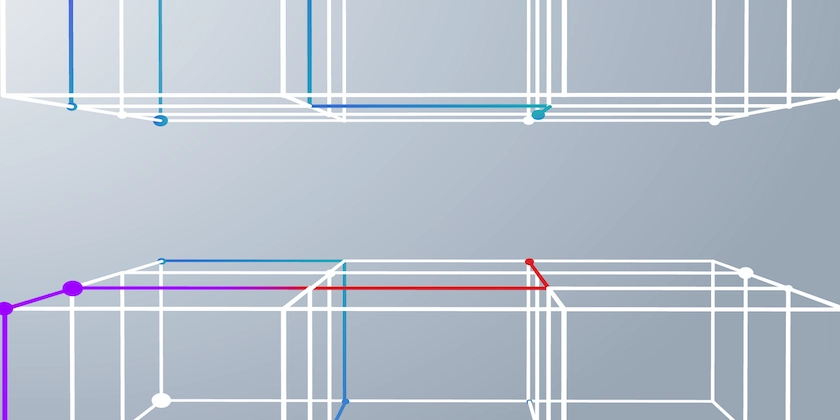
Hierarchical Navigable Small World (HNSW) is a graph-based Approximate Nearest Neighbor (ANN) search algorithm that offers high speed and scalability, making it a great fit for RAG systems. This tutorial explores how HNSW enhances retrieval in AI applications, particularly within IBM’s AI solutions. This tutorial also provides a step-by-step implementation guide and discusses optimizations for large-scale use.
Why HNSW is ideal for RAG
Efficient retrieval is key to AI-driven applications. Large-scale knowledge systems need high accuracy, low latency, and scalability. HNSW meets these needs by offering:
Speed and scalability: Finds results quickly, even with millions of documents.
High recall and accuracy: Outperforms other ANN methods such as LSH and IVFPQ.
Efficient memory use: Balances performance with resource efficiency.
Real-time updates: Supports adding and removing data dynamically.
HNSW is ideal for AI chatbots, enterprise search, recommendation engines, and domain-specific assistants. By using HNSW, developers can improve both speed and precision in RAG applications.
How to use HNSW in a RAG pipeline
A RAG pipeline typically has four main stages:
Document processing and embedding - Convert text documents into vector embeddings using models such as IBM watsonx.ai or Hugging Face Transformers.
Indexing with HNSW – Store embeddings in an HNSW index for fast nearest-neighbor search.
Retrieval and augmentation – Use HNSW to find the most relevant documents for a given query.
Response generation – Feed retrieved data into an LLM (for example, IBM Granite) to generate a response.
Replacing traditional search methods with HNSW significantly improves retrieval speed and accuracy in RAG applications.
Implementing HNSW for RAG in Python
Step 1. Install required libraries
Continue reading on IBM Developer