











































































































































































![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)









































































































































































.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)



































































































_Aleksey_Funtap_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_Sergey_Tarasov_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)











































































































![Apple Foldable iPhone to Feature New Display Tech, 19% Thinner Panel [Rumor]](https://www.iclarified.com/images/news/97271/97271/97271-640.jpg)
![Apple Developing New Chips for Smart Glasses, Macs, AI Servers [Report]](https://www.iclarified.com/images/news/97269/97269/97269-640.jpg)
![Apple Shares New Mother's Day Ad: 'A Gift for Mom' [Video]](https://www.iclarified.com/images/news/97267/97267/97267-640.jpg)
![Apple Shares Official Trailer for 'Stick' Starring Owen Wilson [Video]](https://www.iclarified.com/images/news/97264/97264/97264-640.jpg)



























































































Designing Data Models That Work for Both PostgreSQL and ClickHouse: A Developer’s Guide
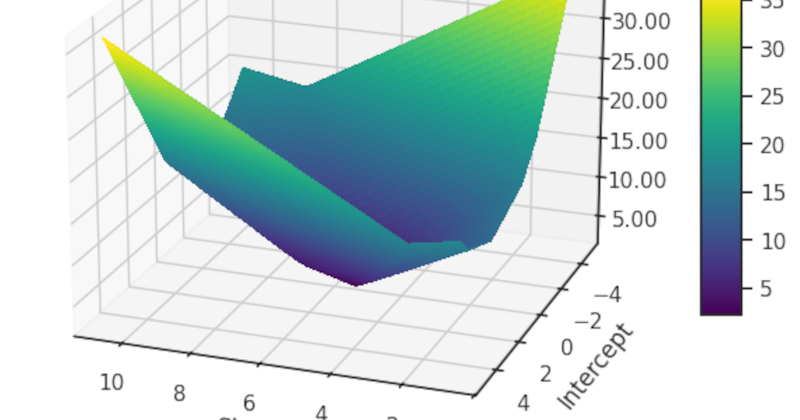
Modern applications are increasingly architected with PostgreSQL for OLTP (transactions) and ClickHouse for OLAP (analytics). This hybrid design gives you the best of both worlds: reliable writes and blazing-fast reads. But here’s the catch—you can’t model data the same way in both. A normalized model that’s perfect for Postgres could kill performance in ClickHouse. And a denormalized, flattened schema for ClickHouse might break constraints and business logic in Postgres. So how do you design a model that works well enough across both? Let’s walk through the key principles, trade-offs, and best practices for dual-target data modeling that won’t leave you regretting schema decisions six months later. Why Use PostgreSQL + ClickHouse? Before diving into data modeling, here’s the high-level architecture: PostgreSQL: Primary source of truth. Handles transactions, constraints, and app-level logic. ClickHouse: Secondary analytical store. Optimized for fast aggregates, filtering, time-series analysis, and dashboards. Common patterns for data syncing: Sync via Debezium / Kafka Periodic ETL using Airflow or DBT Event-based architecture using CDC (Change Data Capture) 1. Normalize in PostgreSQL, Denormalize in ClickHouse PostgreSQL loves third normal form. ClickHouse doesn’t. Feature PostgreSQL ClickHouse Join performance Efficient with indexes Costly, especially over large tables Normalization Encouraged (FKs, constraints) Discouraged (flatten your data) Write latency ACID-compliant, slower but reliable Fast inserts, optimized for batches Analytics Slow on large joins Optimized for OLAP queries Best Practice: Model your source data in normalized form in Postgres. When syncing to ClickHouse, flatten your facts and materialize your dimensions. 2. Watch for Type Compatibility (JSON, UUID, Timestamps) Some Postgres types don’t map cleanly to ClickHouse. Here are common gotchas: PostgreSQL Type ClickHouse Equivalent Notes UUID String No native UUID support, stringify it JSONB String or Nested Consider flattening or casting to string TIMESTAMPTZ DateTime64 Ensure timezones are handled correctly NUMERIC Decimal(18,4) Match precision explicitly Pro Tip: Use a schema registry or intermediate layer (like DBT or protobuf) to enforce compatibility across both systems. 3. Optimize Time-Based Partitioning for ClickHouse ClickHouse thrives when data is partitioned and sorted effectively. PostgreSQL: Use created_at or updated_at for tracking changes. Use indexes on frequently filtered fields. ClickHouse: Partition by toYYYYMM(created_at) or toYYYYMMDD(). Sort key: (user_id, created_at) for segment elimination (faster filtering). 4. Avoid Foreign Keys in ClickHouse ClickHouse does not support foreign key constraints. This means you need to flatten joins ahead of time. Example: PostgreSQL Schema: users(id, name, email) orders(id, user_id, total_amount, created_at) ClickHouse Flattened Table: orders_flat ( order_id UUID, user_id UUID, user_email String, user_name String, total_amount Decimal(10,2), created_at DateTime64 ) ETL pipelines should enrich the data before writing to ClickHouse. 5. Model for Read Patterns, Not Write Patterns ClickHouse thrives on append-only, query-optimized data. Instead of this: SELECT COUNT(*) FROM events WHERE user_id = 'abc123'; Pre-aggregate it: CREATE MATERIALIZED VIEW daily_event_counts AS SELECT user_id, toDate(event_time) AS event_date, count(*) AS daily_count FROM events GROUP BY user_id, event_date; Then query from daily_event_counts instead. 6. Be Cautious with Schema Evolution PostgreSQL handles schema changes gracefully. ClickHouse… doesn’t (yet). Tips: Avoid adding columns frequently in ClickHouse. Use wide-table design (predefine a large schema if possible). Prefer additive changes (append-only, soft deletes). To manage schema drift: Use tools like DBT, Airbyte, or LakeSoul with versioned schemas. Log schema changes and sync them across systems in CI/CD. 7. Use Separate ETL Pipelines for OLTP and OLAP Instead of writing the same data model into both systems directly, maintain two pipelines: OLTP write → PostgreSQL OLTP sync → Enriched + transformed → ClickHouse This decouples constraints, allows async processing, and optimizes each layer for its strength. TL;DR: Unified Modeling Principles Principle PostgreSQL (OLTP) ClickHouse (OLAP) Normalization ✅ Yes ❌ No Joins ✅ Fast ❌ Avoid Constraints ✅ Enforced ❌ Manual Types ✅ Strong, varied ❌ Simpler Writes ✅ Row-based ❌ Batch-based Queries ✅ Indexed row access ❌ Columnar, vectorized Evolution ✅ Flexible ❌ Careful planning needed Final Thoughts Designing data models across PostgreSQL and ClickHouse isn’t about picking one approach—

Modern applications are increasingly architected with PostgreSQL for OLTP (transactions) and ClickHouse for OLAP (analytics). This hybrid design gives you the best of both worlds: reliable writes and blazing-fast reads.
But here’s the catch—you can’t model data the same way in both. A normalized model that’s perfect for Postgres could kill performance in ClickHouse. And a denormalized, flattened schema for ClickHouse might break constraints and business logic in Postgres.
So how do you design a model that works well enough across both?
Let’s walk through the key principles, trade-offs, and best practices for dual-target data modeling that won’t leave you regretting schema decisions six months later.
Why Use PostgreSQL + ClickHouse?
Before diving into data modeling, here’s the high-level architecture:
- PostgreSQL: Primary source of truth. Handles transactions, constraints, and app-level logic.
- ClickHouse: Secondary analytical store. Optimized for fast aggregates, filtering, time-series analysis, and dashboards.
Common patterns for data syncing:
- Sync via Debezium / Kafka
- Periodic ETL using Airflow or DBT
- Event-based architecture using CDC (Change Data Capture)
1. Normalize in PostgreSQL, Denormalize in ClickHouse
PostgreSQL loves third normal form. ClickHouse doesn’t.
| Feature | PostgreSQL | ClickHouse |
|---|---|---|
| Join performance | Efficient with indexes | Costly, especially over large tables |
| Normalization | Encouraged (FKs, constraints) | Discouraged (flatten your data) |
| Write latency | ACID-compliant, slower but reliable | Fast inserts, optimized for batches |
| Analytics | Slow on large joins | Optimized for OLAP queries |
Best Practice:
Model your source data in normalized form in Postgres. When syncing to ClickHouse, flatten your facts and materialize your dimensions.
2. Watch for Type Compatibility (JSON, UUID, Timestamps)
Some Postgres types don’t map cleanly to ClickHouse. Here are common gotchas:
| PostgreSQL Type | ClickHouse Equivalent | Notes |
|---|---|---|
UUID |
String |
No native UUID support, stringify it |
JSONB |
String or Nested
|
Consider flattening or casting to string |
TIMESTAMPTZ |
DateTime64 |
Ensure timezones are handled correctly |
NUMERIC |
Decimal(18,4) |
Match precision explicitly |
Pro Tip:
Use a schema registry or intermediate layer (like DBT or protobuf) to enforce compatibility across both systems.
3. Optimize Time-Based Partitioning for ClickHouse
ClickHouse thrives when data is partitioned and sorted effectively.
-
PostgreSQL:
- Use
created_atorupdated_atfor tracking changes. - Use indexes on frequently filtered fields.
- Use
-
ClickHouse:
- Partition by
toYYYYMM(created_at)ortoYYYYMMDD(). - Sort key:
(user_id, created_at)for segment elimination (faster filtering).
- Partition by
4. Avoid Foreign Keys in ClickHouse
ClickHouse does not support foreign key constraints. This means you need to flatten joins ahead of time.
Example:
PostgreSQL Schema:
users(id, name, email)
orders(id, user_id, total_amount, created_at)
ClickHouse Flattened Table:
orders_flat (
order_id UUID,
user_id UUID,
user_email String,
user_name String,
total_amount Decimal(10,2),
created_at DateTime64
)
ETL pipelines should enrich the data before writing to ClickHouse.
5. Model for Read Patterns, Not Write Patterns
ClickHouse thrives on append-only, query-optimized data.
Instead of this:
SELECT COUNT(*) FROM events WHERE user_id = 'abc123';
Pre-aggregate it:
CREATE MATERIALIZED VIEW daily_event_counts AS
SELECT user_id, toDate(event_time) AS event_date, count(*) AS daily_count
FROM events
GROUP BY user_id, event_date;
Then query from daily_event_counts instead.
6. Be Cautious with Schema Evolution
PostgreSQL handles schema changes gracefully. ClickHouse… doesn’t (yet).
Tips:
- Avoid adding columns frequently in ClickHouse.
- Use wide-table design (predefine a large schema if possible).
- Prefer additive changes (append-only, soft deletes).
To manage schema drift:
- Use tools like DBT, Airbyte, or LakeSoul with versioned schemas.
- Log schema changes and sync them across systems in CI/CD.
7. Use Separate ETL Pipelines for OLTP and OLAP
Instead of writing the same data model into both systems directly, maintain two pipelines:
- OLTP write → PostgreSQL
- OLTP sync → Enriched + transformed → ClickHouse
This decouples constraints, allows async processing, and optimizes each layer for its strength.
TL;DR: Unified Modeling Principles
| Principle | PostgreSQL (OLTP) | ClickHouse (OLAP) |
|---|---|---|
| Normalization | ✅ Yes | ❌ No |
| Joins | ✅ Fast | ❌ Avoid |
| Constraints | ✅ Enforced | ❌ Manual |
| Types | ✅ Strong, varied | ❌ Simpler |
| Writes | ✅ Row-based | ❌ Batch-based |
| Queries | ✅ Indexed row access | ❌ Columnar, vectorized |
| Evolution | ✅ Flexible | ❌ Careful planning needed |
Final Thoughts
Designing data models across PostgreSQL and ClickHouse isn’t about picking one approach—it’s about understanding what each engine excels at and designing your sync + transformations accordingly.
Get this right, and you’ll enjoy the flexibility of Postgres with the speed and scalability of ClickHouse—without constantly fixing pipelines or rewriting queries.
Coming Soon:


