![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)















































































































































































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)



























































































_Steven_Jones_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_Brian_Jackson_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)




 Stolen 884,000 Credit Card Details on 13 Million Clicks from Users Worldwide.webp?#)















































































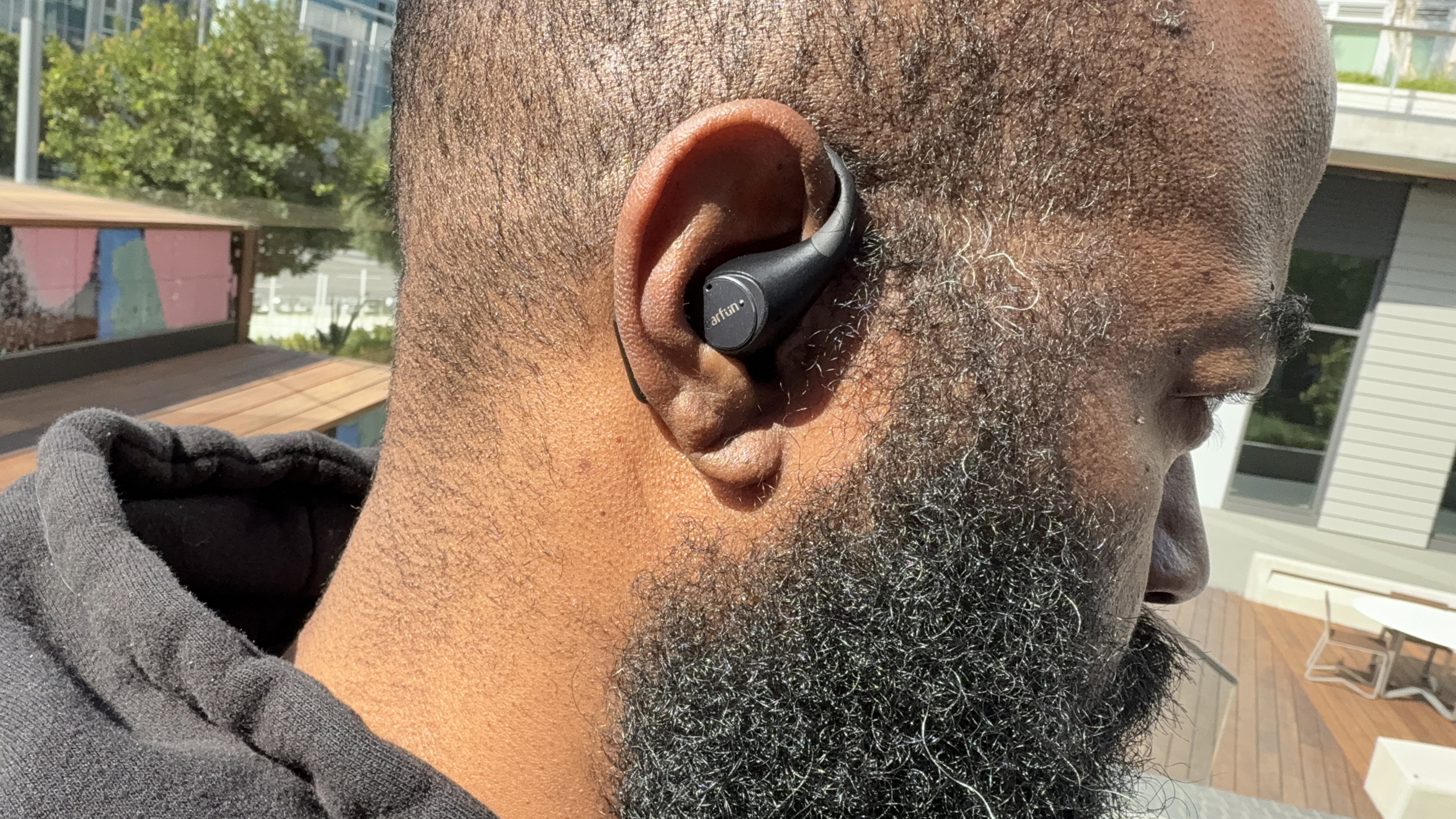






















![Google Mocks Rumored 'iPhone 17 Air' Design in New Pixel Ad [Video]](https://www.iclarified.com/images/news/97224/97224/97224-640.jpg)

![Apple Shares Official Teaser for 'Highest 2 Lowest' Starring Denzel Washington [Video]](https://www.iclarified.com/images/news/97221/97221/97221-640.jpg)



























































































지연(latency)에 대하여
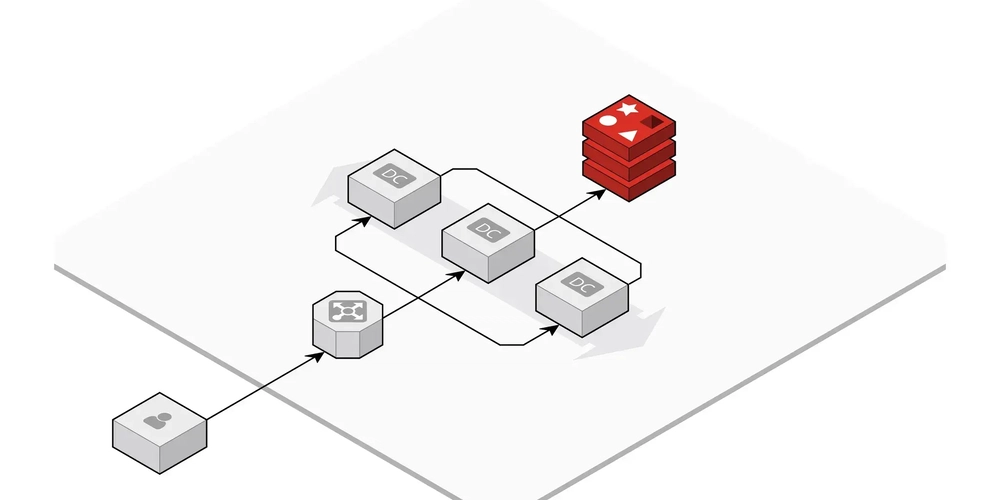
앞서 RDMA에 대한 글을 적으며, 한 가지 '지연(latency)'에 대한 용어에 대해 좀 더 상세히 설명해야겠다는 생각이 들었다. 왜냐하면, 지연(latency)이란 데이터가 한 지점에서 다른 지점으로 이동하는 데 걸리는 시간을 말한다. 다시 말해, 네트워크나 시스템에서 요청(Request)이 전송된 순간부터 응답(Response)을 받을 때까지 걸리는 시간이다. 1. 네트워크에서 지연시간 데이터 패킷이 출발지에서 목적지까지 도달하는 데 걸리는 시간 예) 사용자가 웹사이트를 클릭했을 때, 웹페이지가 로드될 때까지 걸리는 시간 주요 원인: 1) 거리(Distance) → 데이터가 먼 거리까지 이동할수록 지연 증가 2) 라우팅(Routing) → 데이터가 여러 네트워크 장치를 거치면 지연 증가 3) 네트워크 혼잡(Congestion) → 트래픽이 많을수록 패킷이 지연됨 4) 대역폭 제한(Bandwidth Limit) → 낮은 대역폭에서는 데이터 전송 속도가 느려짐 지연 시간 요인 설명 전파 지연 (Propagation Delay) 신호가 물리적인 전송 매체(예: 광케이블, 구리선)를 따라 이동하는 데 걸리는 시간 (거리 영향) 전송 지연 (Transmission Delay) 데이터가 송신 측에서 네트워크를 통해 전송되는 데 걸리는 시간 (패킷 크기 및 대역폭 영향) 처리 지연 (Processing Delay) 라우터나 스위치에서 패킷을 수신하고 검사하며 적절한 경로로 전달하기 위한 처리 시간 큐잉 지연 (Queuing Delay) 네트워크 장비에서 처리 대기 중인 패킷이 대기열에 쌓이면서 발생하는 시간 (혼잡도 영향) 2. 컴퓨터 시스템에서 지연시간 CPU, 메모리, 스토리지, 네트워크 간 데이터 이동 속도 차이로 인해 발생하는 지연 주요 원인: 1) CPU와 RAM 간 데이터 전송 속도 차이 2) 하드 디스크(HDD) vs. 반도체 저장 장치(SSD)의 데이터 접근 속도 차이 3) GPU와 CPU 간 데이터 교환 속도 3. 데이터센터 & AI 환경에서의 지연시간 분산 학습(Distributed Training) 및 RDMA 네트워크에서 매우 중요한 요소 - GPU 간 데이터 교환 속도 좌우 예) 256개의 GPU가 동시에 데이터를 교환할 때 레이턴시가 높으면 전체 AI 학습 속도가 크게 저하됨 주요 원인: 1) 인터 GPU 통신(Inter-GPU Communication)의 최적화 부족 * 단일 서버 내에서 GPU 간 통신: NVIDIA의 NVLink, AMD의 Infinity Fabric, Intel의 Direct Connect 등으로 해결 * 서버 간 GPU 통신 (Cross-Node Communication): InfiniBand 또는 Ethernet 기반 RDMA(Remote Direct Memory Access) 사용 2) RDMA(Remote Direct Memory Access) 오버헤드 3) 케이블 길이가 길면 신호 전달 속도 저하 지연시간 최적화 방법 1) 네트워크 병목(Bottleneck) 제거 → Non-Blocking 네트워크 설계 적용 2) RoCE (RDMA over Converged Ethernet) 사용 → TCP보다 빠른 데이터 전송 3) NVIDIA GPUDirect 사용 → GPU 메모리 간 직접 전송 지원 4. 지연시간을 줄이는 방법 1) 일반 네트워크에서의 최적화 * 대역폭(Bandwidth) 증대 → 100G, 400G 고속 네트워크 사용 * 라우팅 최적화 → 네트워크 홉(Hop) 수를 줄여 데이터 이동 거리 단축 * QoS (Quality of Service) 적용 → 중요 트래픽을 우선 처리 3) HPC&AI 환경에서의 최적화 * RDMA 기반 네트워크 사용 (RoCE, InfiniBand) * NVLink/NVSwitch 같은 GPU 전용 네트워크 활용 * 스파인-리프(Spine-Leaf) 네트워크 설계로 병목 제거 5. 결론 지연은 AI 및 데이터센터에서 가장 중요한 요소 중 하나 -> 네트워크 및 시스템 성능을 결정하는 핵심 지표 AI 및 HPC 환경에서는 낮은 저지연(low latency)가 필수ㄹ 네트워크 설계(Network Topology), RDMA 기술, 케이블 배선 최적화를 통해 최소화해야 함

앞서 RDMA에 대한 글을 적으며, 한 가지 '지연(latency)'에 대한 용어에 대해 좀 더 상세히 설명해야겠다는 생각이 들었다.
왜냐하면, 지연(latency)이란 데이터가 한 지점에서 다른 지점으로 이동하는 데 걸리는 시간을 말한다. 다시 말해, 네트워크나 시스템에서 요청(Request)이 전송된 순간부터 응답(Response)을 받을 때까지 걸리는 시간이다.
1. 네트워크에서 지연시간
- 데이터 패킷이 출발지에서 목적지까지 도달하는 데 걸리는 시간
- 예) 사용자가 웹사이트를 클릭했을 때, 웹페이지가 로드될 때까지 걸리는 시간
- 주요 원인: 1) 거리(Distance) → 데이터가 먼 거리까지 이동할수록 지연 증가 2) 라우팅(Routing) → 데이터가 여러 네트워크 장치를 거치면 지연 증가 3) 네트워크 혼잡(Congestion) → 트래픽이 많을수록 패킷이 지연됨 4) 대역폭 제한(Bandwidth Limit) → 낮은 대역폭에서는 데이터 전송 속도가 느려짐
| 지연 시간 요인 | 설명 |
|---|---|
| 전파 지연 (Propagation Delay) | 신호가 물리적인 전송 매체(예: 광케이블, 구리선)를 따라 이동하는 데 걸리는 시간 (거리 영향) |
| 전송 지연 (Transmission Delay) | 데이터가 송신 측에서 네트워크를 통해 전송되는 데 걸리는 시간 (패킷 크기 및 대역폭 영향) |
| 처리 지연 (Processing Delay) | 라우터나 스위치에서 패킷을 수신하고 검사하며 적절한 경로로 전달하기 위한 처리 시간 |
| 큐잉 지연 (Queuing Delay) | 네트워크 장비에서 처리 대기 중인 패킷이 대기열에 쌓이면서 발생하는 시간 (혼잡도 영향) |
2. 컴퓨터 시스템에서 지연시간
CPU, 메모리, 스토리지, 네트워크 간 데이터 이동 속도 차이로 인해 발생하는 지연
주요 원인:
1) CPU와 RAM 간 데이터 전송 속도 차이
2) 하드 디스크(HDD) vs. 반도체 저장 장치(SSD)의 데이터 접근 속도 차이
3) GPU와 CPU 간 데이터 교환 속도
3. 데이터센터 & AI 환경에서의 지연시간
- 분산 학습(Distributed Training) 및 RDMA 네트워크에서 매우 중요한 요소 - GPU 간 데이터 교환 속도 좌우
예) 256개의 GPU가 동시에 데이터를 교환할 때 레이턴시가 높으면 전체 AI 학습 속도가 크게 저하됨
주요 원인:
1) 인터 GPU 통신(Inter-GPU Communication)의 최적화 부족
* 단일 서버 내에서 GPU 간 통신: NVIDIA의 NVLink, AMD의 Infinity Fabric, Intel의 Direct Connect 등으로 해결
* 서버 간 GPU 통신 (Cross-Node Communication): InfiniBand 또는 Ethernet 기반 RDMA(Remote Direct Memory Access) 사용
2) RDMA(Remote Direct Memory Access) 오버헤드
3) 케이블 길이가 길면 신호 전달 속도 저하지연시간 최적화 방법
1) 네트워크 병목(Bottleneck) 제거 → Non-Blocking 네트워크 설계 적용
2) RoCE (RDMA over Converged Ethernet) 사용 → TCP보다 빠른 데이터 전송
3) NVIDIA GPUDirect 사용 → GPU 메모리 간 직접 전송 지원
4. 지연시간을 줄이는 방법
1) 일반 네트워크에서의 최적화
* 대역폭(Bandwidth) 증대 → 100G, 400G 고속 네트워크 사용
* 라우팅 최적화 → 네트워크 홉(Hop) 수를 줄여 데이터 이동 거리 단축
* QoS (Quality of Service) 적용 → 중요 트래픽을 우선 처리
3) HPC&AI 환경에서의 최적화
* RDMA 기반 네트워크 사용 (RoCE, InfiniBand)
* NVLink/NVSwitch 같은 GPU 전용 네트워크 활용
* 스파인-리프(Spine-Leaf) 네트워크 설계로 병목 제거
5. 결론
- 지연은 AI 및 데이터센터에서 가장 중요한 요소 중 하나 -> 네트워크 및 시스템 성능을 결정하는 핵심 지표
- AI 및 HPC 환경에서는 낮은 저지연(low latency)가 필수ㄹ
- 네트워크 설계(Network Topology), RDMA 기술, 케이블 배선 최적화를 통해 최소화해야 함