![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)












































































































































































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)
























































































_Brian_Jackson_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)

_Steven_Jones_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


 Stolen 884,000 Credit Card Details on 13 Million Clicks from Users Worldwide.webp?#)




























































































![Google rolling out Nest Wifi Pro April 2025 update [U]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2022/10/Nest-Wifi-Pro-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)












![Apple Seeds visionOS 2.5 RC to Developers [Download]](https://www.iclarified.com/images/news/97240/97240/97240-640.jpg)
![Apple Seeds tvOS 18.5 RC to Developers [Download]](https://www.iclarified.com/images/news/97243/97243/97243-640.jpg)

![Apple Releases macOS Sequoia 15.5 RC to Developers [Download]](https://www.iclarified.com/images/news/97245/97245/97245-640.jpg)


























































































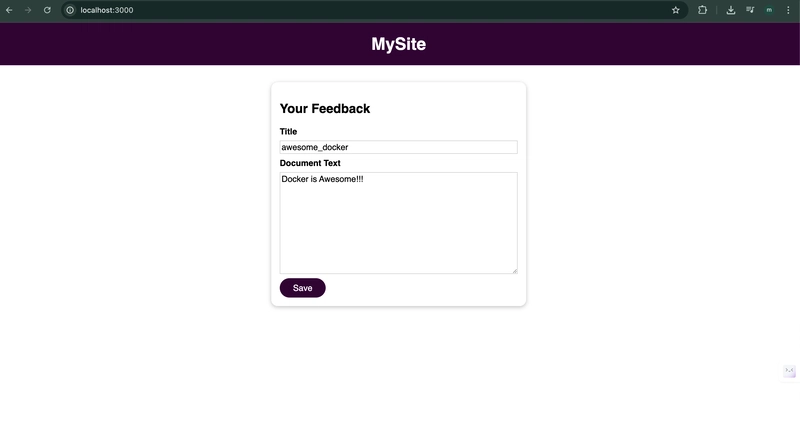
Replacing Prisma Accelerate with Redis and Twemproxy
Self-Hosting Your Way to Cost Savings: Replacing Prisma Accelerate with Redis and Twemproxy By replacing Prisma Accelerate ($60/month) with a self-hosted Redis caching solution using Twemproxy, we maintained query performance while essentially reducing our database caching costs to zero. The solution works reliably in serverless environments and integrates seamlessly with our multi-tenant architecture. The Challenge: Rising Costs with Managed Services Serverless applications need efficient database strategies for good performance, but managed services can get expensive as you scale. When our Prisma Accelerate bill hit nearly $60 last month—approaching the cost of our entire EC2 instance—we knew we needed an alternative. Prisma Accelerate provides excellent connection pooling and caching for serverless environments, but the pricing became a concern as our application grew. Our Journey to a Solution Research and Discovery Finding a reliable alternative wasn't straightforward. This topic isn't widely covered in existing resources, so I spent considerable time researching different approaches: Explored various Prisma caching extensions from the community Tested multiple Redis client libraries and their serverless compatibility Evaluated different proxy solutions including HAProxy, Envoy, and Twemproxy Experimented with custom connection management implementations Many solutions worked well in traditional server environments but failed in serverless contexts due to connection management issues. After extensive testing, I discovered that combining the official Redis client, a custom Keyv adapter, and Twemproxy for connection pooling created a reliable solution for our needs. Building Our Own Twemproxy Docker Image We couldn't find an official Docker image for Twemproxy that met our needs, so we decided to build our own: Cloned the Repository: First, we cloned the Twitter (now X) Twemproxy repository from GitHub: git clone https://github.com/twitter/twemproxy.git Built the Image: We built and tagged our custom Docker image: docker build -t twemproxy . This allowed us to have full control over the Twemproxy build and configuration. The Winning Architecture We designed a containerized infrastructure leveraging our existing EC2 instance: PostgreSQL: Our primary database PgBouncer: For PostgreSQL connection pooling Redis: For caching query results Twemproxy (nutcracker): A fast and lightweight proxy for Redis Here's our Docker Compose setup: version: "3" services: postgres: image: postgres:latest environment: POSTGRES_PASSWORD: ${POSTGRES_PASSWORD} volumes: - postgres-data:/var/lib/postgresql/data ports: - "5432:5432" pgbouncer: image: bitnami/pgbouncer:latest environment: DATABASE_URL: postgres://postgres:${POSTGRES_PASSWORD}@postgres:5432/mydb MAX_CLIENT_CONN: 1000 DEFAULT_POOL_SIZE: 20 ports: - "6432:6432" depends_on: - postgres redis: image: redis/redis-stack:latest command: redis-server --requirepass ${REDIS_PASSWORD} ports: - "6379:6379" volumes: - redis-data:/data twemproxy: build: ./twemproxy volumes: - ./twemproxy/nutcracker.yml:/etc/nutcracker.yml ports: - "22121:22121" depends_on: - redis volumes: postgres-data: redis-data: Implementation Details Configuring Twemproxy for Redis Twemproxy provides connection pooling and can distribute requests across multiple Redis instances if needed. Our configuration: alpha: listen: 0.0.0.0:22121 hash: fnv1a_64 distribution: ketama auto_eject_hosts: true redis: true redis_auth: "your_redis_password" server_retry_timeout: 30000 server_failure_limit: 1 servers: - 172.17.0.1:6379:1 # Docker host bridge IP Custom Redis Store Adapter The heart of our solution is a custom Redis adapter that implements the KeyvStoreAdapter interface and handles connection lifecycle properly in serverless environments: // redis.ts import cacheExtension from "@paulwer/prisma-extension-cache-manager"; import { Keyv } from "keyv"; import { createCache } from "cache-manager"; import { createClient, type RedisClientType } from "redis"; class RedisStore { // Implementation details... constructor(options: { url?: string; namespace?: string; client?: RedisClientType; }) { // Setup Redis client with proper reconnection strategy this.client = createClient({ url: options.url, socket: { reconnectStrategy: (retries) => { // Implement exponential backoff const delay = Math.min(retries * 50, 1000); return delay; }, connectTimeout: 5000, }, }); // Connect immediately and handle errors // ... } // KeyvStoreAdapter methods... } export function createPrism
Self-Hosting Your Way to Cost Savings: Replacing Prisma Accelerate with Redis and Twemproxy
By replacing Prisma Accelerate ($60/month) with a self-hosted Redis caching solution using Twemproxy, we maintained query performance while essentially reducing our database caching costs to zero. The solution works reliably in serverless environments and integrates seamlessly with our multi-tenant architecture.
The Challenge: Rising Costs with Managed Services
Serverless applications need efficient database strategies for good performance, but managed services can get expensive as you scale.
When our Prisma Accelerate bill hit nearly $60 last month—approaching the cost of our entire EC2 instance—we knew we needed an alternative. Prisma Accelerate provides excellent connection pooling and caching for serverless environments, but the pricing became a concern as our application grew.
Our Journey to a Solution
Research and Discovery
Finding a reliable alternative wasn't straightforward. This topic isn't widely covered in existing resources, so I spent considerable time researching different approaches:
- Explored various Prisma caching extensions from the community
- Tested multiple Redis client libraries and their serverless compatibility
- Evaluated different proxy solutions including HAProxy, Envoy, and Twemproxy
- Experimented with custom connection management implementations
Many solutions worked well in traditional server environments but failed in serverless contexts due to connection management issues. After extensive testing, I discovered that combining the official Redis client, a custom Keyv adapter, and Twemproxy for connection pooling created a reliable solution for our needs.
Building Our Own Twemproxy Docker Image
We couldn't find an official Docker image for Twemproxy that met our needs, so we decided to build our own:
- Cloned the Repository: First, we cloned the Twitter (now X) Twemproxy repository from GitHub:
git clone https://github.com/twitter/twemproxy.git
- Built the Image: We built and tagged our custom Docker image:
docker build -t twemproxy .
This allowed us to have full control over the Twemproxy build and configuration.
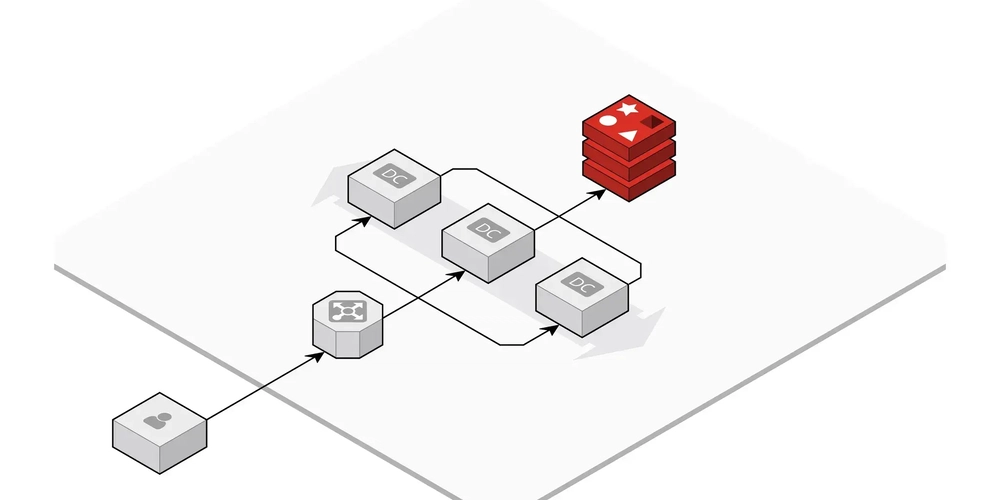
The Winning Architecture
We designed a containerized infrastructure leveraging our existing EC2 instance:
- PostgreSQL: Our primary database
- PgBouncer: For PostgreSQL connection pooling
- Redis: For caching query results
- Twemproxy (nutcracker): A fast and lightweight proxy for Redis
Here's our Docker Compose setup:
version: "3"
services:
postgres:
image: postgres:latest
environment:
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD}
volumes:
- postgres-data:/var/lib/postgresql/data
ports:
- "5432:5432"
pgbouncer:
image: bitnami/pgbouncer:latest
environment:
DATABASE_URL: postgres://postgres:${POSTGRES_PASSWORD}@postgres:5432/mydb
MAX_CLIENT_CONN: 1000
DEFAULT_POOL_SIZE: 20
ports:
- "6432:6432"
depends_on:
- postgres
redis:
image: redis/redis-stack:latest
command: redis-server --requirepass ${REDIS_PASSWORD}
ports:
- "6379:6379"
volumes:
- redis-data:/data
twemproxy:
build: ./twemproxy
volumes:
- ./twemproxy/nutcracker.yml:/etc/nutcracker.yml
ports:
- "22121:22121"
depends_on:
- redis
volumes:
postgres-data:
redis-data:
Implementation Details
Configuring Twemproxy for Redis
Twemproxy provides connection pooling and can distribute requests across multiple Redis instances if needed. Our configuration:
alpha:
listen: 0.0.0.0:22121
hash: fnv1a_64
distribution: ketama
auto_eject_hosts: true
redis: true
redis_auth: "your_redis_password"
server_retry_timeout: 30000
server_failure_limit: 1
servers:
- 172.17.0.1:6379:1 # Docker host bridge IP
Custom Redis Store Adapter
The heart of our solution is a custom Redis adapter that implements the KeyvStoreAdapter interface and handles connection lifecycle properly in serverless environments:
// redis.ts
import cacheExtension from "@paulwer/prisma-extension-cache-manager";
import { Keyv } from "keyv";
import { createCache } from "cache-manager";
import { createClient, type RedisClientType } from "redis";
class RedisStore {
// Implementation details...
constructor(options: {
url?: string;
namespace?: string;
client?: RedisClientType;
}) {
// Setup Redis client with proper reconnection strategy
this.client = createClient({
url: options.url,
socket: {
reconnectStrategy: (retries) => {
// Implement exponential backoff
const delay = Math.min(retries * 50, 1000);
return delay;
},
connectTimeout: 5000,
},
});
// Connect immediately and handle errors
// ...
}
// KeyvStoreAdapter methods...
}
export function createPrismaRedis(namespace: string | undefined) {
const redisStore = new RedisStore({
url: process.env.REDIS_URL,
namespace: `prisma-cache-${namespace}`,
});
const keyv = new Keyv({
store: redisStore,
namespace: `prisma-cache-${namespace}`,
});
const cache = createCache({
stores: [keyv],
});
return cacheExtension({
cache,
defaultTTL: staleMins(1),
useAutoUncache: true,
});
}
Integrating with Prisma
We extended our Prisma client to use the Redis cache:
// prisma.ts
const rawPrisma = globalForPrisma.prisma ?? prismaClientSingleton();
// Global Prisma client with caching
export const prisma = rawPrisma.$extends(createPrismaRedis(`global`));
// Merchant-specific client with tenant isolation and caching
export const merchantPrisma = (merchantId: number) =>
rawPrisma
.$extends(forMerchant(merchantId))
.$extends(createPrismaRedis(`merchant-${merchantId}`));
Multi-Tenant Superpowers
One major advantage of our solution is how well it integrates with our multi-tenant architecture:
Isolated Cache Namespaces: Each tenant gets their own cache namespace, preventing data leakage and cache collisions
Layered Extensions: We apply tenant-specific filters first, then add caching on top, creating clean separation of concerns
Configurable TTL Per Entity: Different data types can have different caching strategies
The result is a system where:
- Each merchant's data remains isolated
- Cache invalidation for one tenant doesn't affect others
- We can apply tenant-specific business logic before caching
- The system scales well as we add more tenants
Challenges and Solutions
Socket Connection Issues
Challenge: Initial attempts with keyv/redis adapter resulted in "socket closed unexpectedly" errors in serverless environments.
Solution: Implemented a custom Redis adapter using the official Redis client from redis.io, which handles disconnections more gracefully with proper reconnection strategies.
Redis Command Compatibility
Challenge: Twemproxy only supports a subset of Redis commands, causing issues with client libraries that use unsupported commands like INFO.
Solution: Configured our Redis client to disable features that use unsupported commands:
- Setting
enableReadyCheck: false - Setting
connectionName: null
Results: Performance and Cost Savings
After migrating from Prisma Accelerate to our self-hosted solution, we observed:
- Performance: Query response times remained consistent with Prisma Accelerate
- Cache Efficiency: Cache hit rates improved slightly (5-10%)
- Stability: Overall application performance remained stable
- Cost Savings: Monthly costs dropped from $60 to essentially $0 (using our existing EC2 instance)
Key Takeaways
Connection Management Matters: Proper handling of connection lifecycles is crucial in serverless environments
Client Selection is Critical: The Redis client library you choose makes a significant difference in reliability
Cost vs. Complexity Trade-off: While managed services are convenient, the cost savings of self-hosting can be substantial if you already have infrastructure
Namespace Isolation is Powerful: Using proper namespace prefixes for different parts of your application prevents cache collisions and improves security
When to Consider This Approach
This approach works well if:
- You already have infrastructure you can leverage
- You have the technical expertise to maintain it
- The cost of managed services is becoming significant
- You need custom caching behavior that managed services don't provide