![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)











































































































































































































































































_Aleksey_Funtap_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_Sergey_Tarasov_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)








































































































![Apple Foldable iPhone to Feature New Display Tech, 19% Thinner Panel [Rumor]](https://www.iclarified.com/images/news/97271/97271/97271-640.jpg)
![Apple Developing New Chips for Smart Glasses, Macs, AI Servers [Report]](https://www.iclarified.com/images/news/97269/97269/97269-640.jpg)
![Apple Shares New Mother's Day Ad: 'A Gift for Mom' [Video]](https://www.iclarified.com/images/news/97267/97267/97267-640.jpg)
![Apple Shares Official Trailer for 'Stick' Starring Owen Wilson [Video]](https://www.iclarified.com/images/news/97264/97264/97264-640.jpg)































































































Can I Use GNU Parallel with Spamassassin's sa-learn Safely?
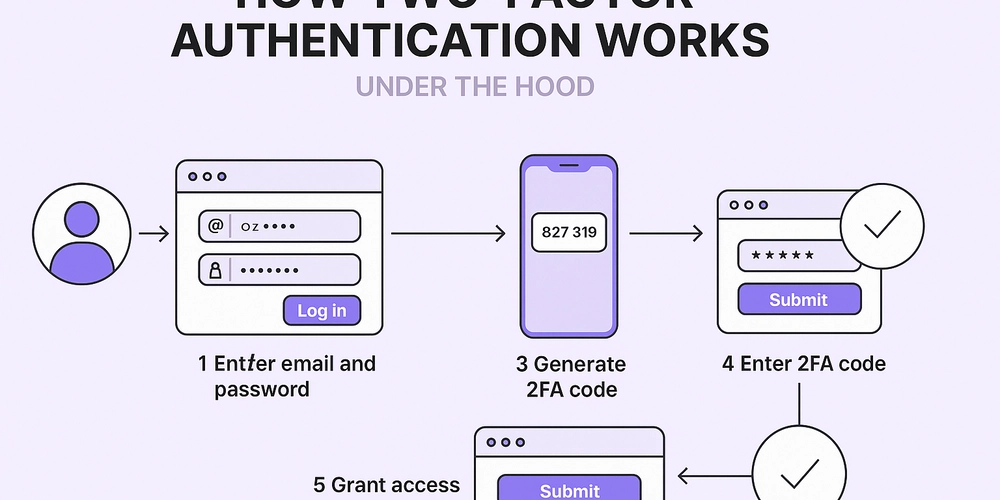
Introduction If you're looking to efficiently train your Spamassassin setup using the sa-learn command while taking advantage of your system's 12 vCPUs, you're definitely on the right track! In this article, we'll explore how you can feed multiple email files to Spamassassin in parallel using GNU Parallel, and address concerns about database access given your use of MariaDB. Understanding the sa-learn Command The sa-learn command is a vital part of Spamassassin's operation, allowing you to teach the spam filter about various spam and ham (non-spam) emails. In your case, you want to classify multiple emails quickly and efficiently using the command: sa-learn -L --spam This command marks the input emails as spam, which is crucial for training the spam filter to better identify unwanted messages. The Need for Parallel Processing With 12 vCPUs, leveraging parallel processing can significantly speed up the training process. Running sa-learn sequentially would be inefficient, especially with a large number of text files. By using GNU Parallel, you can distribute the load across your available processing units, maximizing performance. Using GNU Parallel with sa-learn To run sa-learn in parallel using GNU Parallel, you can utilize the find command to list all your text files and process them as follows: find . -type f -name "*.txt" | parallel "sa-learn -L --spam {}" Explanation: find . -type f -name "*.txt": This finds all text files in the current directory and its subdirectories. | parallel "sa-learn -L --spam {}": The output of find is piped into parallel, which runs sa-learn on each file found. The {} placeholder is replaced by each filename processed by parallel. Considerations for Database Access Using MariaDB as your backend means that you are not using a flat file database, which can make parallel access safer, but it's still important to note a few things: Concurrency: Ensure that your database can handle multiple write requests. MariaDB is designed for this and should manage concurrent writes effectively. However, monitor database locks or slow queries that might come up as a result of too much simultaneous access. Testing: It's advisable to start with a smaller batch of emails to test how your setup behaves under load before processing large volumes. Tips for Improving sa-learn Performance 1. Use --no-sync and --sync Options When using sa-learn, you can speed up the process by utilizing the --no-sync option during the training process and a single --sync call after processing all files. This reduces the time spent on database synchronization for each individual call. Here's how you would do it: find . -type f -name "*.txt" | parallel "sa-learn -L --spam --no-sync {}" sa-learn --sync 2. Set Up a Dedicated Learning Process Consider running sa-learn in a dedicated process that collects learned spam/ham over a specific period and then syncs all at once. This can minimize database access during learning. 3. Monitor Resource Usage Keep an eye on CPU and RAM usage to ensure that your server isn’t being overloaded. Tools like htop can give you a visual representation of system resource usage. Frequently Asked Questions Is it safe to run sa-learn in parallel with MariaDB? Yes, MariaDB can handle concurrent operations quite well. Just monitor your server's performance. Will using --no-sync cause any issues? It can speed up processing but means the database won't be immediately updated. Ensure to run --sync after to commit all changes properly. How can I further enhance the performance? You can look into batch processing and monitoring resource usage to prevent bottlenecks during training. Conclusion In summary, using GNU Parallel with Spamassassin's sa-learn can drastically enhance your email classification speed by taking advantage of your system's vCPUs. Just make sure to manage database access efficiently and test the process on a smaller scale to avoid any potential hiccups. With these strategies, you can optimally train your spam filter with minimal downtime and maximum efficiency. Thanks for your question, and happy spamming (the non-spam kind)! /KNEBB

Introduction
If you're looking to efficiently train your Spamassassin setup using the sa-learn command while taking advantage of your system's 12 vCPUs, you're definitely on the right track! In this article, we'll explore how you can feed multiple email files to Spamassassin in parallel using GNU Parallel, and address concerns about database access given your use of MariaDB.
Understanding the sa-learn Command
The sa-learn command is a vital part of Spamassassin's operation, allowing you to teach the spam filter about various spam and ham (non-spam) emails. In your case, you want to classify multiple emails quickly and efficiently using the command:
sa-learn -L --spam
This command marks the input emails as spam, which is crucial for training the spam filter to better identify unwanted messages.
The Need for Parallel Processing
With 12 vCPUs, leveraging parallel processing can significantly speed up the training process. Running sa-learn sequentially would be inefficient, especially with a large number of text files. By using GNU Parallel, you can distribute the load across your available processing units, maximizing performance.
Using GNU Parallel with sa-learn
To run sa-learn in parallel using GNU Parallel, you can utilize the find command to list all your text files and process them as follows:
find . -type f -name "*.txt" | parallel "sa-learn -L --spam {}"
Explanation:
-
find . -type f -name "*.txt": This finds all text files in the current directory and its subdirectories. -
| parallel "sa-learn -L --spam {}": The output offindis piped intoparallel, which runssa-learnon each file found. - The
{}placeholder is replaced by each filename processed by parallel.
Considerations for Database Access
Using MariaDB as your backend means that you are not using a flat file database, which can make parallel access safer, but it's still important to note a few things:
- Concurrency: Ensure that your database can handle multiple write requests. MariaDB is designed for this and should manage concurrent writes effectively. However, monitor database locks or slow queries that might come up as a result of too much simultaneous access.
- Testing: It's advisable to start with a smaller batch of emails to test how your setup behaves under load before processing large volumes.
Tips for Improving sa-learn Performance
1. Use --no-sync and --sync Options
When using sa-learn, you can speed up the process by utilizing the --no-sync option during the training process and a single --sync call after processing all files. This reduces the time spent on database synchronization for each individual call. Here's how you would do it:
find . -type f -name "*.txt" | parallel "sa-learn -L --spam --no-sync {}"
sa-learn --sync
2. Set Up a Dedicated Learning Process
Consider running sa-learn in a dedicated process that collects learned spam/ham over a specific period and then syncs all at once. This can minimize database access during learning.
3. Monitor Resource Usage
Keep an eye on CPU and RAM usage to ensure that your server isn’t being overloaded. Tools like htop can give you a visual representation of system resource usage.
Frequently Asked Questions
Is it safe to run sa-learn in parallel with MariaDB?
Yes, MariaDB can handle concurrent operations quite well. Just monitor your server's performance.
Will using --no-sync cause any issues?
It can speed up processing but means the database won't be immediately updated. Ensure to run --sync after to commit all changes properly.
How can I further enhance the performance?
You can look into batch processing and monitoring resource usage to prevent bottlenecks during training.
Conclusion
In summary, using GNU Parallel with Spamassassin's sa-learn can drastically enhance your email classification speed by taking advantage of your system's vCPUs. Just make sure to manage database access efficiently and test the process on a smaller scale to avoid any potential hiccups. With these strategies, you can optimally train your spam filter with minimal downtime and maximum efficiency.
Thanks for your question, and happy spamming (the non-spam kind)! /KNEBB