


























































.jpg)


















































































































![[The AI Show Episode 148]: Microsoft’s Quiet AI Layoffs, US Copyright Office’s Bombshell AI Guidance, 2025 State of Marketing AI Report, and OpenAI Codex](https://www.marketingaiinstitute.com/hubfs/ep%20148%20cover%20%281%29.png)


![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)











































































































































































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)



































































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)





















_Alan_Wilson_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_pichetw_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)













































































-xl.jpg)
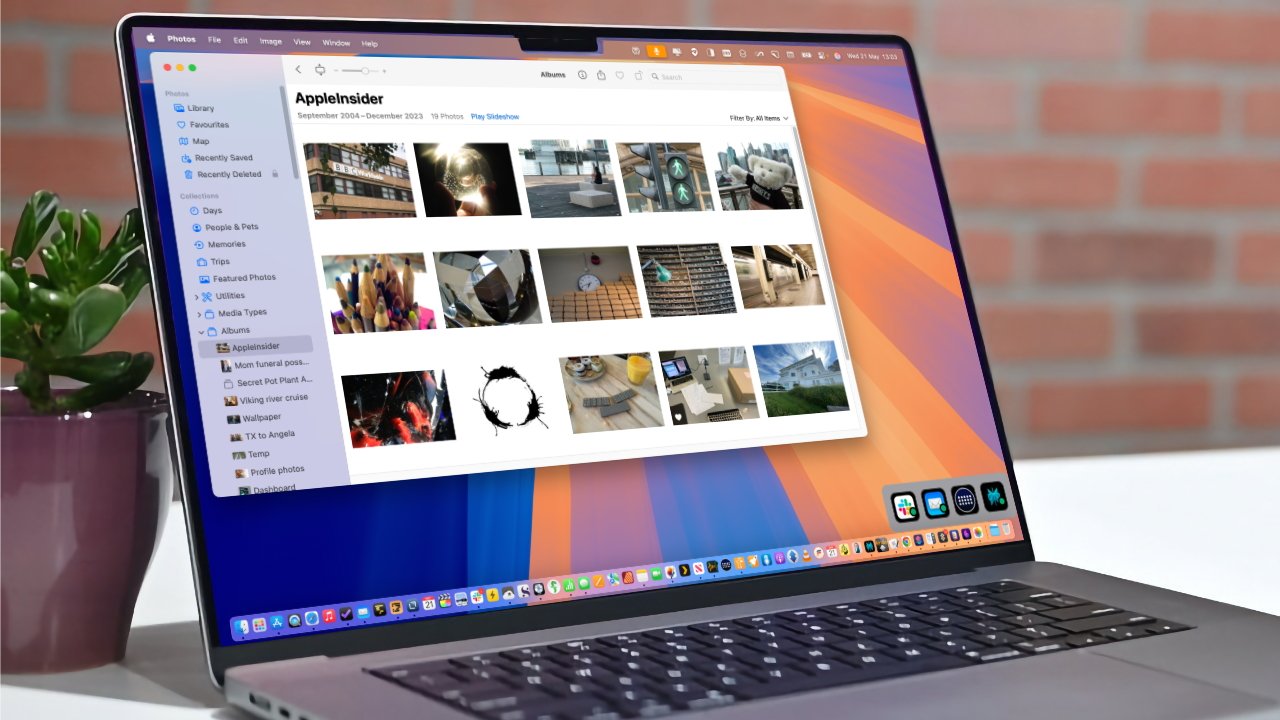


























![Apple Leads Global Wireless Earbuds Market in Q1 2025 [Chart]](https://www.iclarified.com/images/news/97394/97394/97394-640.jpg)

![OpenAI Acquires Jony Ive's 'io' to Build Next-Gen AI Devices [Video]](https://www.iclarified.com/images/news/97399/97399/97399-640.jpg)
![Apple Shares Teaser for 'Chief of War' Starring Jason Momoa [Video]](https://www.iclarified.com/images/news/97400/97400/97400-640.jpg)




























































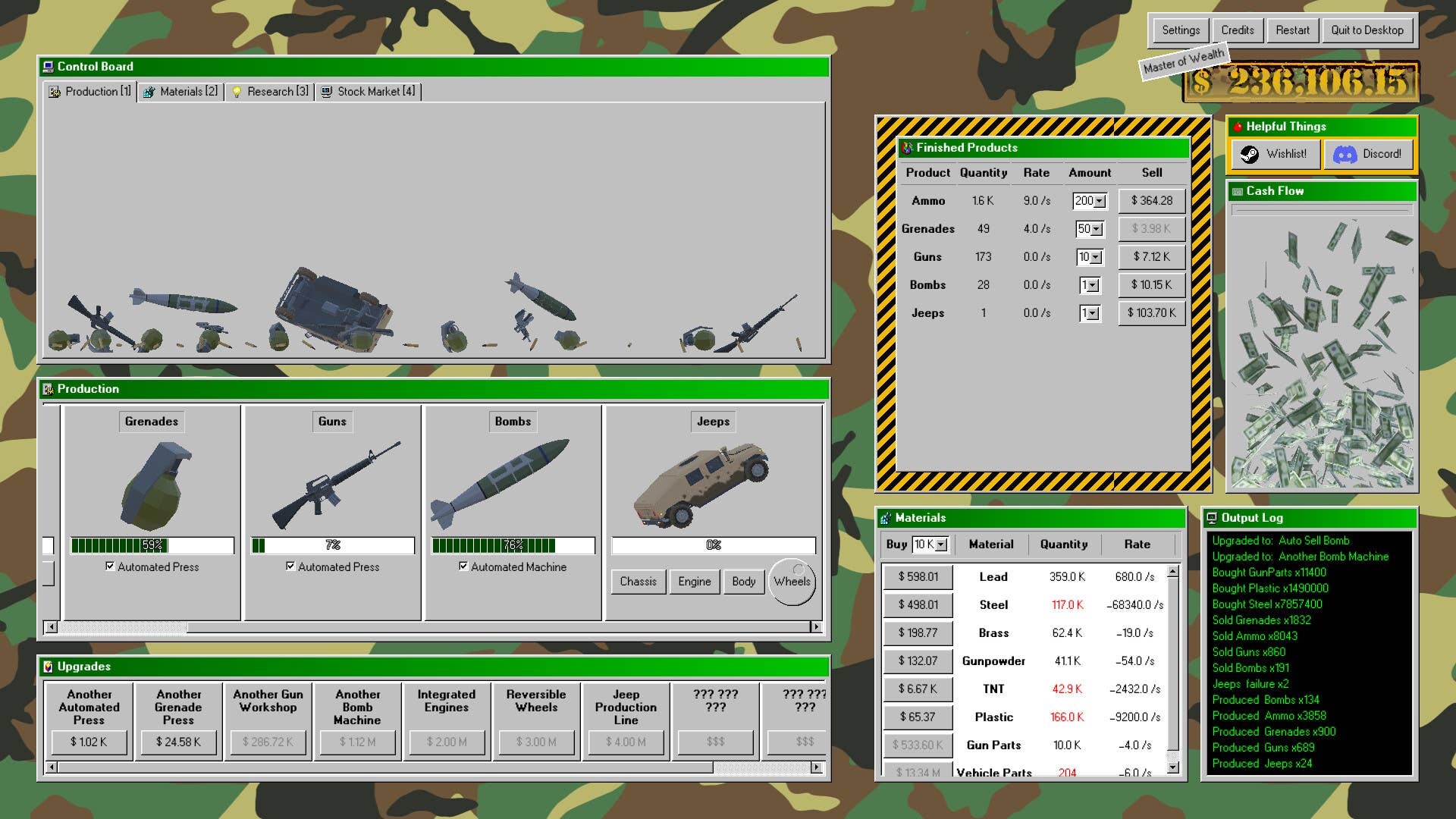
i built a FastAPI tool that automatically converts dense PDFs into Anki flashcards using LLMs—but not without battling slow APIs, broken parsing, and cursed 404 errors. Here’s how I fixed it (and how you can too). As a student, it took me hours on end to be able to manually create flashcards. until i realized Anki has their own API Interface, which made me realize that i can automate this task, efficiently, while also getting hand on experience using FastAPI and LLMs (but am i going to change the stack later?.. lets see) First off, the task seemed pretty easy Parse from PDF -> Chunk PDF content to paragraphs -> Send Chunks to through the API Port to generate the flashcards using DeepSeek -> get response as a txt file (which will be changed later to Anki Format (.apkg) Simple right?.. right First problem i faced was how slow it is to send the LLM Requests, chunk by chunk , which was extremely slow especially for large PDFs like the one i tested at first. This Problem stayed with me for a while, how can i optimize the response time? since i knew the bottle neck was in the function that handled exactly.. back to this problem in a bit, lets see what smaller problems i faced Ready? its PARSING HELL and no, its not parsing from input PDF Problem: The API returned "question\answer" placeholders instead of real content. it was literally just : Question: Answer: Question: Answer: . . . Question: Answer: Debugging Steps: Realized the LLM response format was inconsistent. Switched to regex parsing for robustness: def parse_flashcards_response(response: str) -> list[dict]: matches = re.findall(r"Question:\s*(.*?)\s*Answer:\s*(.*?)(?=(?:Question:|$))", response, re.DOTALL) return [{"question": q.strip(), "answer": a.strip()} for q, a in matches] and finally.. it worked. and then i faced another problem , OpenRouter's daily rate limit of 5 requests/day.. which was a nightmare not just for scalability, but for even testing. So i switched to Groq's llama3-8b-8192 Which has a very generous token and requests, daily limit. You can find all their free and paid tier available models and their rate limits on their website now my application is 10x faster due to async chunk feeding to the API and my new Cool model. Next step -> Actually adding the Anki file formation logic mentioned earlier (.apkg) Using genanki, the process was straight forward, instead of my initial .txt output, now its a full on functional .apkg that can be imported directly to the Anki App as a studying deck. which i faced a problem with my old parsing and cleaning logic.. which in the output looked something like this After changing the logic behind parsing with even more (jumpscare warning) regex it kind of got fixed. finally, some prompt engineering to ensure that there is no numbering, no headings, no fluff is there, i used this prompt : f"""Convert to flashcards using EXACTLY this format: Question: [Your question here] Answer: [Your answer here] NO other text, NO numbering, NO headers, just alternating Question/Answer pairs. Content to convert: {batch_text}""" After adding some simple error handling for each page, and testing the error handling functionality, i could say that the backend is officially done and i couldn't be happier :) Now for the Frontend, i decided i will be using React with TailwindCSS for a clean, sleek frontend. im not a frontend master or anything, but i got it sorted out, the frontend is MVP ready! now, for some final E2E Testing.. i used more dense lecture PDFs, and thankfully it passed all checks ✅ Hosting.. hosting... hosting... hosting was a problem for me at first, since i didn't really want to pay at the start since its a hobby MVP with no revenue, i used Render's free tier for the backend hosting and used https://vercel.com/ and with that i could say i have a viable MVP! And of course, the app still needs polishing like.. Better Prompt engineering, Tweak frontend bugs, and so on.. Thank you for reading! i hope that was a pretty good read, it was my first time writing about a project im working on. here is the link incase you want to check out the MVP! Recallr

i built a FastAPI tool that automatically converts dense PDFs into Anki flashcards using LLMs—but not without battling slow APIs, broken parsing, and cursed 404 errors. Here’s how I fixed it (and how you can too).
As a student, it took me hours on end to be able to manually create flashcards.
until i realized Anki has their own API Interface, which made me realize that i can automate this task, efficiently, while also getting hand on experience using FastAPI and LLMs (but am i going to change the stack later?.. lets see)
First off, the task seemed pretty easy
Parse from PDF -> Chunk PDF content to paragraphs -> Send Chunks to through the API Port to generate the flashcards using DeepSeek -> get response as a txt file (which will be changed later to Anki Format (.apkg)
Simple right?.. right
First problem i faced was how slow it is to send the LLM Requests, chunk by chunk , which was extremely slow especially for large PDFs like the one i tested at first.
This Problem stayed with me for a while, how can i optimize the response time? since i knew the bottle neck was in the function that handled exactly..
back to this problem in a bit, lets see what smaller problems i faced
Ready? its PARSING HELL
and no, its not parsing from input PDF
Problem: The API returned "question\answer" placeholders instead of real content.
it was literally just :
Question: Answer:
Question: Answer:
.
.
.
Question: Answer:
Debugging Steps:
Realized the LLM response format was inconsistent.
Switched to regex parsing for robustness:
def parse_flashcards_response(response: str) -> list[dict]:
matches = re.findall(r"Question:\s*(.*?)\s*Answer:\s*(.*?)(?=(?:Question:|$))", response, re.DOTALL)
return [{"question": q.strip(), "answer": a.strip()} for q, a in matches]
and finally.. it worked.
and then i faced another problem , OpenRouter's daily rate limit of 5 requests/day.. which was a nightmare not just for scalability, but for even testing.
So i switched to Groq's llama3-8b-8192
Which has a very generous token and requests, daily limit.
You can find all their free and paid tier available models and their rate limits on their website
now my application is 10x faster due to async chunk feeding to the API and my new Cool model.
Next step -> Actually adding the Anki file formation logic mentioned earlier (.apkg)
Using genanki, the process was straight forward, instead of my initial .txt output, now its a full on functional .apkg that can be imported directly to the Anki App as a studying deck.
which i faced a problem with my old parsing and cleaning logic..
which in the output looked something like this
After changing the logic behind parsing with even more (jumpscare warning) regex
it kind of got fixed.
finally, some prompt engineering to ensure that there is no numbering, no headings, no fluff is there, i used this prompt :
f"""Convert to flashcards using EXACTLY this format:
Question: [Your question here]
Answer: [Your answer here]
NO other text, NO numbering, NO headers, just alternating Question/Answer pairs.
Content to convert:
{batch_text}"""
After adding some simple error handling for each page, and testing the error handling functionality, i could say that the backend is officially done and i couldn't be happier :)
Now for the Frontend, i decided i will be using React with TailwindCSS for a clean, sleek frontend.
im not a frontend master or anything, but i got it sorted out, the frontend is MVP ready!
now, for some final E2E Testing.. i used more dense lecture PDFs, and thankfully it passed all checks ✅
Hosting.. hosting... hosting...
hosting was a problem for me at first, since i didn't really want to pay at the start since its a hobby MVP with no revenue, i used Render's free tier for the backend hosting and used https://vercel.com/
and with that i could say i have a viable MVP!
And of course, the app still needs polishing like..
Better Prompt engineering, Tweak frontend bugs, and so on..
Thank you for reading! i hope that was a pretty good read, it was my first time writing about a project im working on.
here is the link incase you want to check out the MVP!
Recallr



