![[The AI Show Episode 148]: Microsoft’s Quiet AI Layoffs, US Copyright Office’s Bombshell AI Guidance, 2025 State of Marketing AI Report, and OpenAI Codex](https://www.marketingaiinstitute.com/hubfs/ep%20148%20cover%20%281%29.png)


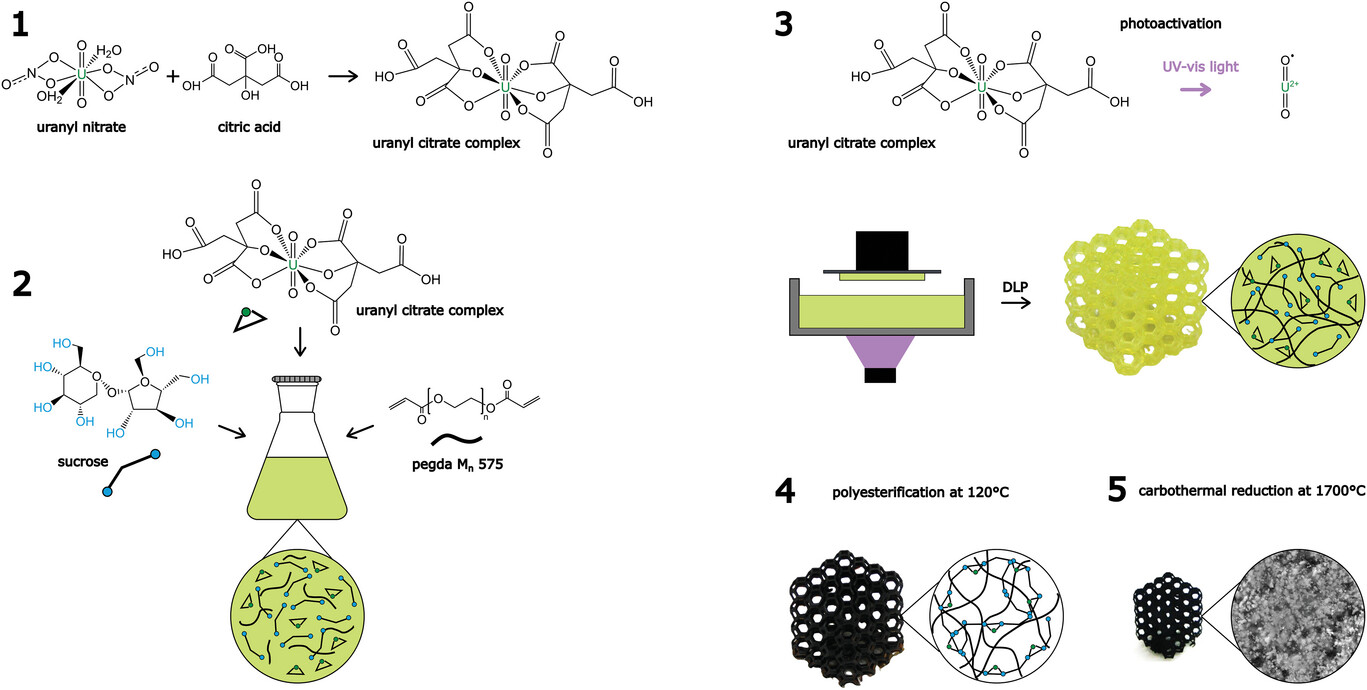
![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)














































































































































































-(1).jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)



























































.jpg?#)




.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)















































































































![What’s new in Android’s May 2025 Google System Updates [U: 5/19]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)

















![Apple's iPhone Shift to India Accelerates With $1.5 Billion Foxconn Investment [Report]](https://www.iclarified.com/images/news/97357/97357/97357-640.jpg)
![Apple Releases iPadOS 17.7.8 for Older Devices [Download]](https://www.iclarified.com/images/news/97358/97358/97358-640.jpg)



























































Interview with Filippos Gouidis: Object state classification
Filippos’s PhD dissertation focuses on developing a method for recognizing object states without visual training data. By leveraging semantic knowledge from online sources and Large Language Models, structured as Knowledge Graphs, Graph Neural Networks learn representations for accurate state classification. In this interview series, we’re meeting some of the AAAI/SIGAI Doctoral Consortium participants to find […]

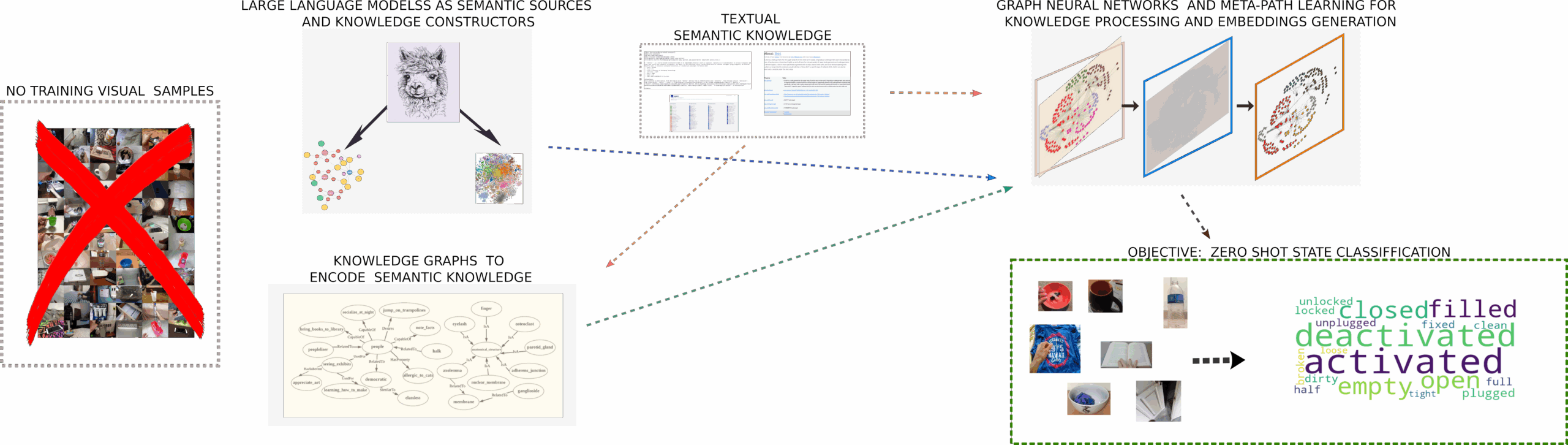 Filippos’s PhD dissertation focuses on developing a method for recognizing object states without visual training data. By leveraging semantic knowledge from online sources and Large Language Models, structured as Knowledge Graphs, Graph Neural Networks learn representations for accurate state classification.
Filippos’s PhD dissertation focuses on developing a method for recognizing object states without visual training data. By leveraging semantic knowledge from online sources and Large Language Models, structured as Knowledge Graphs, Graph Neural Networks learn representations for accurate state classification.
In this interview series, we’re meeting some of the AAAI/SIGAI Doctoral Consortium participants to find out more about their research. The Doctoral Consortium provides an opportunity for a group of PhD students to discuss and explore their research interests and career objectives in an interdisciplinary workshop together with a panel of established researchers. In this latest interview, we met with Filippos Gouidis, who has recently completed his PhD, and found out more about his research on object state classification.
Could you start by giving us a brief introduction to who you are, where you’re working and the main theme of your research?
I’m Filippos, and I’m currently a post-doc researcher at the Foundation for Research and Technology – Hellas (FORTH) at Crete, Greece. Typically I am also a PhD Student at the University of Crete. I say ‘typically’ because I’m currently awaiting my graduation ceremony. I did my Bachelor’s degree here and then two Masters – one in computer science and the other in cognitive science. I have now finished my PhD, which I defended in January.
The topic of my dissertation concerns a computer vision problem and, more specifically, object state classification. Object state classification is simple to understand. You have an object in an image or a video and you want to recognize the state of the object, which refers to its functional state. For example, this water bottle I’m holding right now is closed – that’s its state (to be more accurate, that represents one of its functional states). In the field of computer vision, one of the most important problems is the object recognition or classification problem: recognizing the class of an object. Object state classification is one step beyond this. As well as being able to recognise an object, sometimes it is equally important to recognize the state of the object because the actions you perform on an object depend on its state. For example, if a robot were to grasp a water bottle, its grasp would be different depending on whether the cap was open or closed, or whether the bottle was full or empty. So, this is not only a problem of theoretical importance, but also a problem with a lot of practical implications.
What was the state-of-the-art with regards to object state classification when you started your PhD and how has your work progressed this?
When I began my PhD, a lot of researchers were starting to focus on this problem. Over the last decade, a great amount of research effort has been invested into the closely related problem of object classification. We can say that now we have many powerful object classification systems that surpass the performance of humans. So the next logical step is to move and study object state classification. This problem is more challenging because typically it’s more difficult to solve with a standard deep learning algorithm. It’s much more difficult for a system to learn how to recognize the state of the object and to differentiate the state of the object than recognizing the class of the object. For example, if you had an image of a water bottle with the cap on and another image of the water bottle, but with the cap off, they appear visually similar. So, there is virtually no difference in the two images, but this small difference results in completely different states. So this is one of the major challenges here.
Another major challenge is that typically in AI we need a lot of data to train our models. When I started my PhD there was only one dataset for object states. In fact, as part of my dissertation, we created a new dataset for object state classification. A year after our dataset was published, another two datasets were published. So, now we have around four benchmark datasets.
To a large degree I would say that the problem has still not been resolved, but a lot of progress has been made over the last few years and more and more research focuses on this topic. And I would like to think that I have also contributed my share, however small, in progressing forward this problem.
Could you talk a bit about the method that you developed?
This problem is treated typically in the standard way computer vision problems have been addressed over the last few years where a deep learning approach is used. In our method we wanted to differentiate a little bit and opted to use a neurosymbolic approach. Just to explain what neurosymbolic means: with a pure deep learning method, like a standard convolutional neural network, the approach is completely data-driven. The neural network learns statistical patterns from the data, and while these patterns often help solve the task, they’re not always easily interpretable. For example, when we recognize a face, we intuitively focus on features like the eyes or the mouth. A deep learning system might also use similar cues, but the way it represents and uses this information is typically opaque — it doesn’t link directly to human-understandable concepts. This lack of interpretability can be a problem, especially in safety-critical or high-stakes applications. In contrast, symbolic approaches (what some call “classical AI”) rely on explicit, structured representations, such as rules and logical relations, which are often more interpretable and grounded in human knowledge. These two paradigms are complementary: symbolic systems offer interpretability and prior knowledge, while deep learning offers flexibility and adaptability.
In the last decade the dominant approach for solving computer vision problems was following a pure deep learning approach. Our method combines the best of both worlds: the flexibility of neural networks with the structured reasoning of symbolic knowledge, represented through knowledge graphs. Graphs are mathematical structures that enable us to represent relations between different concepts in a structured and scalable way. Graphs essentially consist of two types of entities: nodes and edges. For example the metro maps shown in train carriages are graphs. In our case we used a special type of graphs: knowledge graphs which allow the representation of different types of knowledge, such as commonsense knowledge, i.e., knowledge regarding everyday life. The knowledge graph we used was based on the object, states and their relations to other concepts. In order to construct them we relied on online repositories of knowledge.
Our latest neurosymbolic method (which was presented at WACV) combines the deep-learning approach with knowledge graphs. Essentially it introduces a novel variation for the object state classification task. So this novel variation is a zero-shot variation. It’s zero-shot in the sense that you can classify the state of an object but you don’t need any visual data to train the model. It sounds magical, but it’s not. If we consider a human reading a book, for example, and they are reading a book about some animal that they’ve never seen before, the brain has the capacity to recognise the animal in an image even if it’s the first time they’ve seen it, just by reading the characteristic details. In a broader sense, we did this with our zero-shot variation. We have to find information in a place other than images, so we are using the knowledge graph in order to leverage this type of additional information.
Our method is also object-agnostic. That means that without using any cue or any other explicit information for the class of the object, we can classify the state. For example, we might have some objects that are unknown, but we can still classify the states of these unknown objects.
So, to sum up, this method is both zero-shot and object agnostic. This is something novel and promising in the way that it’s more appropriate for real-time problems. In real life, you might encounter novel and unknown objects because we have many thousands of objects that we encounter in everyday life. And also because, even if we have some known object, we always have the problem of not having correctly defined the class of the object. So if we depend on an accurate classification on the class of the object, this error might cascade to the state classification. So if we have an object-agnostic state classifier, we avoid this danger.
How was the Doctoral Consortium experience at AAAI 2025?
It was fascinating. The two keynotes were really good, especially the second one because it was very close to my topic. It covered robotics stuff that was really close to object state, so that was really interesting to me.
There were two different sessions where we were split into groups of eight-ten PhD students and we sat with a mentor. We were able to ask the mentor questions and meet other participants as well. The most fascinating thing for me was that I got to meet a lot of people, a lot of interesting PhD students, and I would say maybe some of us could collaborate in the near future.
What was it that made you want to study AI and this topic in particular?
When I began my Bachelor’s, AI wasn’t the popular term that it is now. Now, everybody uses the term AI, but then, at the beginning of the Bachelor’s the deep learning paradigm began. I remember that we had another graduate course on AI but there were very few people in attendance. I then read a book on AI from the 1980s titled The Mind’s I, by Douglas Hofstadter (a computer scientist) and Daniel Dennett (a philosopher). It’s really a book concerning all the philosophical implications of AI. After I read this book, I realised that this is what I wanted to do. I was very lucky because AI was becoming more and more entrenched and it was easier to find a Master’s and PhD in AI than it would have been years before.
For our final question, could you tell us an interesting fact about you, or any hobbies that you enjoy outside of your research?
I really like reading. I read books about everything – literature, philosophy, poetry. In fact, I love anything written in a book. I’m also a fan of watching movies. I also like cycling and running. These activities have helped me with my research. For example, if there is some problem I need to solve, the best way to resolve it is to go on a 15km run or a 50 km bike ride, and I can think more clearly and the ideas come.
To conclude, I’d like to add one more thought. We live in strange times actually. AI has changed our lives in a spectacular way (and I fear that the overall balance is not positive). It becomes more and more evident that there is also a responsibility for anyone who works with AI, either in academia or industry, due to the effect that AI has on society. I would like to be optimistic and think that AI can be used to make the world a better place.
About Filippos

|
Filippos Gouidis is a postdoctoral researcher at the Foundation for Research and Technology – Hellas (FORTH) in Greece. He holds a Bachelor’s and an MSc in Computer Science, as well as an MSc in Cognitive Science. His PhD focused on zero-shot object state classification. His research interests lie in knowledge representation, neurosymbolic integration, and zero-shot learning. |