










































































































































































![[The AI Show Episode 151]: Anthropic CEO: AI Will Destroy 50% of Entry-Level Jobs, Veo 3’s Scary Lifelike Videos, Meta Aims to Fully Automate Ads & Perplexity’s Burning Cash](https://www.marketingaiinstitute.com/hubfs/ep%20151%20cover.png)

































































































































![From electrical engineering student to CTO with Hitesh Choudhary [Podcast #175]](https://cdn.hashnode.com/res/hashnode/image/upload/v1749158756824/3996a2ad-53e5-4a8f-ab97-2c77a6f66ba3.png?#)




































































































































_Michael_Vi_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)






































































































![UGREEN FineTrack Smart Tracker With Apple Find My Support Drops to $9.99 [50% Off]](https://www.iclarified.com/images/news/97529/97529/97529-640.jpg)

![watchOS 26 May Bring Third-Party Widgets to Control Center [Report]](https://www.iclarified.com/images/news/97520/97520/97520-640.jpg)































































BrightData's MCP: Fetching Real-time Web Data For LLMs
In the world of artificial intelligence, especially large language models (LLMs), there's a quiet revolution happening. It's called Model Context Protocol, or simply MCP. You may have encountered the term in AI communities or tool integrations, but what exactly is MCP, and why should you care? Let’s break it down, step by step, and show you how this simple yet powerful concept is solving one of the biggest headaches in AI, which is accessing real-time web data. What Is MCP (Model Context Protocol)? Imagine you’ve trained a brilliant AI that knows history, science, programming, and can even write poetry. But ask it what’s trending on Twitter or what the latest YouTube comments are on a viral video, and you’ll likely get outdated, static responses. Why? Because LLMs are not built for real-time web interaction out of the box. That’s where MCP steps in. MCP is an open standard that acts as a bridge between AI agents (like Claude, GPT, etc.) and real-time data sources like websites, APIs, or databases. Think of it as a universal translator that allows AI models to interact with the constantly-changing web securely and efficiently. Instead of hardcoding access to different websites or APIs, MCP standardizes the way AI tools request data. It makes live data scraping and interaction much more streamlined and predictable — no more breaking scripts or bot detection errors. Why Do LLMs Struggle with Real-Time Data? Let’s address the elephant in the room. LLMs like Claude, ChatGPT, and others are trained on massive datasets, but that training is static. This means the AI only knows what it was trained on. If you ask it for stock prices, breaking news, or fresh YouTube comments, it simply doesn’t know. Even worse, if it tries to guess, it might give you hallucinated or flat-out wrong answers. Sure, you could plug in some APIs or attempt to write your own scraping scripts. But anyone who's tried this knows how quickly you hit roadblocks: JavaScript rendering CAPTCHA and anti-bot detection Proxy rotation and management Data formatting inconsistencies Rate limits And much more... To obtain a list of recent comments or product prices, you find yourself immediately immersed in backend development. A Real-World Example: When LLMs Fail Let me give you a quick example. I asked Claude to fetch the latest comments from a YouTube video. It understood the request just fine… but couldn’t get the data. That’s because it doesn’t have native access to YouTube’s dynamic content. Claude can only interpret requests, but it can’t execute scraping logic on its own. This is a classic scenario where even the smartest LLMs fall short without real-time access tools. Building Your Own MCP? It’s Harder Than It Looks Technically, you can build your own MCP setup. You’d need to: Set up a scraping infrastructure. Manage rotating proxies. Handle headless browser environments. Deal with dynamic web rendering. Write adapters to plug data into your AI agent. Sounds doable at first, right? But trust me, you’ll soon find yourself debugging edge cases and fighting CAPTCHAs, all for a task that should feel simple. What starts as a weekend project quickly turns into a full-time scraping job. That’s why most developers and AI researchers look for managed solutions. Bright Data’s MCP: Your AI’s Web Gateway This is where Bright Data’s MCP changes the game. Bright Data, a leading data collection platform, has created a plug-and-play MCP service that gives your AI agent real-time access to the web without dealing with any of the complexity. Here’s what it offers: Unblockable access to websites like Amazon, YouTube, LinkedIn, Instagram, X (Twitter), Facebook, TikTok, Zillow, Reddit, and even Google. Built-in proxy handling – no need to rotate or manage IPs. Headless browser support – for rendering JavaScript-heavy pages. Remote browser APIs – so your agent can interact with pages like a real user. Plenty of ready-made scraping tools – for different websites and use cases. Everything is handled under the hood, and all you need to do is configure the access; no scraping code required. Let’s See It in Action I ran the same prompt with more tasks using Bright Data’s MCP: “Fetch the latest comments from a YouTube video and provide that data in a json file”. You can see that it worked and that too without any hassle. Behind the scenes, Bright Data’s tools were doing all the heavy lifting: launching a browser, unlocking the page, pulling the data, formatting it, and sending it back to the AI agent. No errors. No retries. Just results. How to Integrate Bright Data’s MCP with Claude Desktop Okay, now let’s go through how to actually connect Bright Data’s MCP with Claude Desktop. It’s simpler than you might think. Step 1: Install Node.js Make sure Node.js is installed on your system. You’ll need the npx command to run the MCP server. St

In the world of artificial intelligence, especially large language models (LLMs), there's a quiet revolution happening. It's called Model Context Protocol, or simply MCP. You may have encountered the term in AI communities or tool integrations, but what exactly is MCP, and why should you care?
Let’s break it down, step by step, and show you how this simple yet powerful concept is solving one of the biggest headaches in AI, which is accessing real-time web data.
What Is MCP (Model Context Protocol)?
Imagine you’ve trained a brilliant AI that knows history, science, programming, and can even write poetry. But ask it what’s trending on Twitter or what the latest YouTube comments are on a viral video, and you’ll likely get outdated, static responses. Why? Because LLMs are not built for real-time web interaction out of the box.
That’s where MCP steps in.
MCP is an open standard that acts as a bridge between AI agents (like Claude, GPT, etc.) and real-time data sources like websites, APIs, or databases. Think of it as a universal translator that allows AI models to interact with the constantly-changing web securely and efficiently.
Instead of hardcoding access to different websites or APIs, MCP standardizes the way AI tools request data. It makes live data scraping and interaction much more streamlined and predictable — no more breaking scripts or bot detection errors.
Why Do LLMs Struggle with Real-Time Data?
Let’s address the elephant in the room.
LLMs like Claude, ChatGPT, and others are trained on massive datasets, but that training is static. This means the AI only knows what it was trained on. If you ask it for stock prices, breaking news, or fresh YouTube comments, it simply doesn’t know. Even worse, if it tries to guess, it might give you hallucinated or flat-out wrong answers.
Sure, you could plug in some APIs or attempt to write your own scraping scripts. But anyone who's tried this knows how quickly you hit roadblocks:
JavaScript rendering
CAPTCHA and anti-bot detection
Proxy rotation and management
Data formatting inconsistencies
Rate limits
And much more...
To obtain a list of recent comments or product prices, you find yourself immediately immersed in backend development.
A Real-World Example: When LLMs Fail
Let me give you a quick example.
I asked Claude to fetch the latest comments from a YouTube video. It understood the request just fine… but couldn’t get the data. That’s because it doesn’t have native access to YouTube’s dynamic content. Claude can only interpret requests, but it can’t execute scraping logic on its own.
This is a classic scenario where even the smartest LLMs fall short without real-time access tools.
Building Your Own MCP? It’s Harder Than It Looks
Technically, you can build your own MCP setup. You’d need to:
Set up a scraping infrastructure.
Manage rotating proxies.
Handle headless browser environments.
Deal with dynamic web rendering.
Write adapters to plug data into your AI agent.
Sounds doable at first, right? But trust me, you’ll soon find yourself debugging edge cases and fighting CAPTCHAs, all for a task that should feel simple. What starts as a weekend project quickly turns into a full-time scraping job.
That’s why most developers and AI researchers look for managed solutions.
Bright Data’s MCP: Your AI’s Web Gateway
This is where Bright Data’s MCP changes the game.
Bright Data, a leading data collection platform, has created a plug-and-play MCP service that gives your AI agent real-time access to the web without dealing with any of the complexity.
Here’s what it offers:
Unblockable access to websites like Amazon, YouTube, LinkedIn, Instagram, X (Twitter), Facebook, TikTok, Zillow, Reddit, and even Google.
Built-in proxy handling – no need to rotate or manage IPs.
Headless browser support – for rendering JavaScript-heavy pages.
Remote browser APIs – so your agent can interact with pages like a real user.
Plenty of ready-made scraping tools – for different websites and use cases.
Everything is handled under the hood, and all you need to do is configure the access; no scraping code required.
Let’s See It in Action
I ran the same prompt with more tasks using Bright Data’s MCP: “Fetch the latest comments from a YouTube video and provide that data in a json file”.
You can see that it worked and that too without any hassle.

Behind the scenes, Bright Data’s tools were doing all the heavy lifting: launching a browser, unlocking the page, pulling the data, formatting it, and sending it back to the AI agent.
No errors. No retries. Just results.
How to Integrate Bright Data’s MCP with Claude Desktop
Okay, now let’s go through how to actually connect Bright Data’s MCP with Claude Desktop. It’s simpler than you might think.
Step 1: Install Node.js
Make sure Node.js is installed on your system. You’ll need the npx command to run the MCP server.
Step 2: Create a Bright Data Account
Head over to Bright Data and sign up. Once your account is ready, log in to the user dashboard.
Step 3: Prepare the Claude Desktop Configuration
Open the Claude desktop app.
Click on File → Settings → Developer → Edit File.
This opens a file named claude-desktop-config.json.
Open it in your favorite text editor.
Step 4: Add MCP Configuration
Now, go to the GitHub repository provided by Bright Data and copy the MCP config code.

Paste that into the claude-desktop-config.json file.

Step 5: Insert Your Real MCP Credentials
Once you’ve pasted the configuration block into the claude-desktop-config.json file, it’s time to replace the placeholders with your actual values. This is what will connect your Claude Desktop app to Bright Data’s MCP system.
Here’s how to do it:
Head to Your Bright Data Dashboard
Log in to your Bright Data account and navigate to the Proxies & Scraping section. This is where you’ll manage the tools needed to enable real-time scraping.

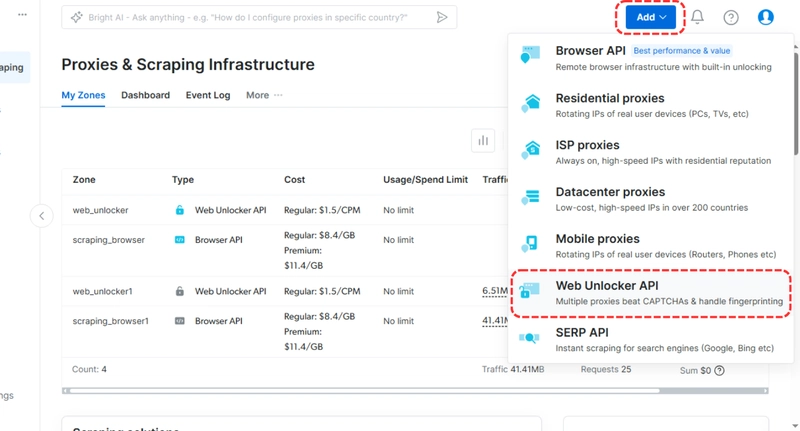
Create a Scraping Zone
Click the “Add” button and choose “Web Unlocker API” as your tool. Once created, you’ll see a dashboard showing your new zone.
Copy the API Key
You’ll find your API key in the “Account Settings” section. Alternatively, Bright Data may have emailed it to you when you signed up. Either way, copy this key and paste it into the relevant "API_TOKEN" field in your config file.

Add the Web Unlocker Zone Name
Still in your dashboard, find the name of the Web Unlocker zone you just created. Copy it and paste it into the "WEB_UNLOCKER_ZONE" field in your configuration.

Enable Remote Browsing with Browser API
Want to supercharge your scraping setup with headless browser access? You can!
Just add a Browser API by clicking “Browser API” in the “Add” section.

Give it a name — something like my-browser-api.
After it's created, you’ll see a string.
Copy just the key part (not the full URL) and paste it into the "BROWSER_AUTH" field in your config.

This optional step enables your AI agent to interact with websites that require full browser emulation, which is perfect for scraping JavaScript-heavy pages or logging into websites.
Step 6: Restart Claude
Save the configuration file, quit Claude Desktop, and restart the app.

Once you open it again, you’ll see that all Bright Data MCP tools are now available to use directly within Claude. That’s it, now you’re ready to start scraping real-time web data with zero friction.
The Big Picture
The MCP isn’t just another API — it’s a protocol that aims to standardize how AI tools interact with dynamic data sources. And with platforms like Bright Data offering powerful plug-and-play integrations, you can start building real-time, context-aware agents without worrying about the plumbing.
Instead of writing your own scrapers, debugging browser sessions, or juggling proxies, you can focus on what matters: creating intelligent workflows that adapt to live information.
Whether you're working on:
Competitive intelligence
Social media monitoring
Real-time news summaries
E-commerce pricing trackers
AI research assistants
...MCP opens up a whole new world of possibilities.
Conclusion
Large Language Models are impressive — but without live data, they’re limited. MCP is the missing puzzle piece, and Bright Data’s implementation makes it incredibly easy to adopt.
If you're tired of watching your AI fumble on basic real-time tasks, give MCP a shot. It’s fast, powerful, and surprisingly easy to set up. And if you're using Claude Desktop, the whole thing takes under 10 minutes to integrate.
Your AI just got a whole lot smarter.
That’s all for now.
Keep Coding✌✌




