






































































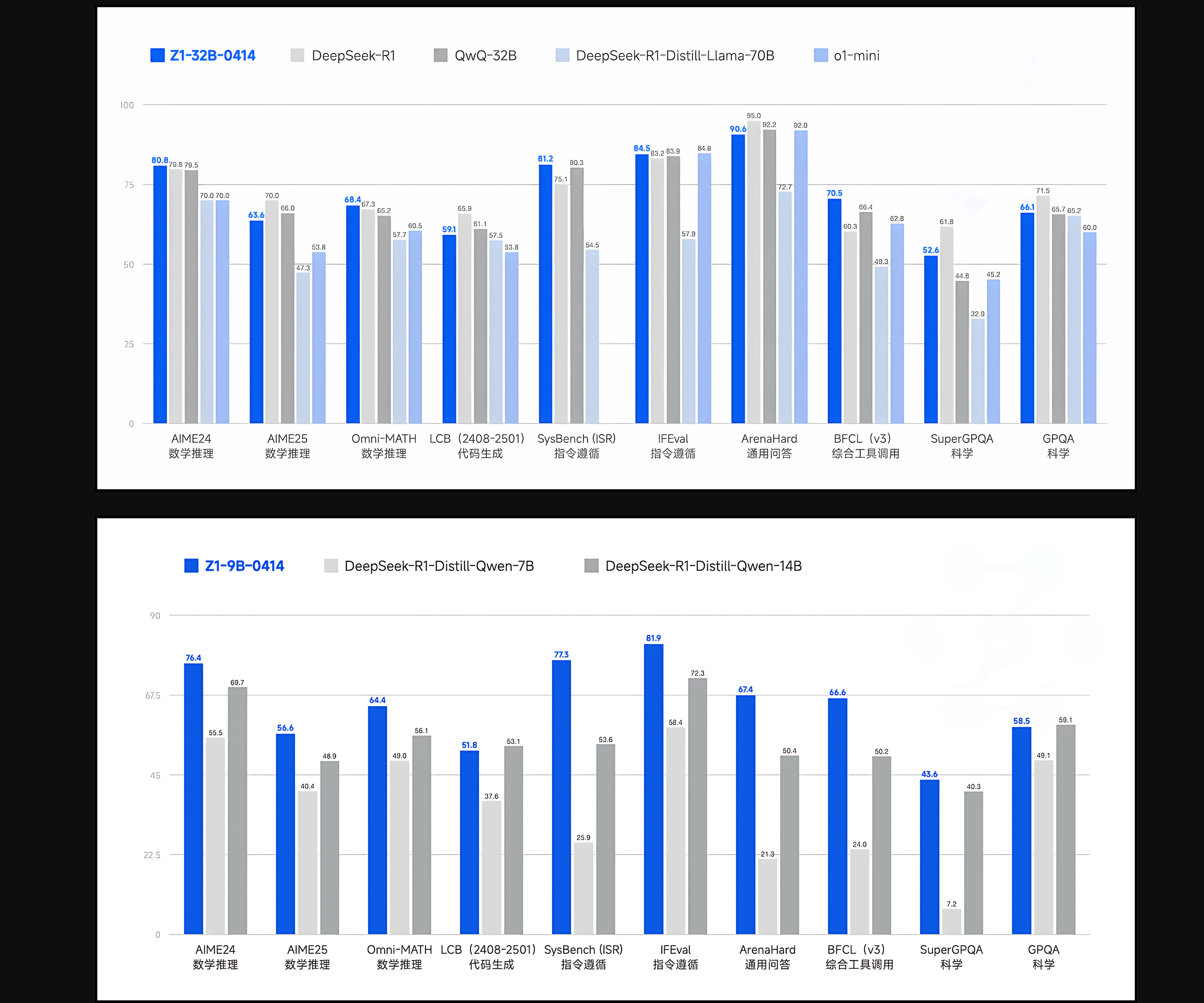





































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)







































































































































































































































.png?#)


































.webp?#)
.webp?#)

.webp?#)






















































































![[Fixed] Gemini app is failing to generate Audio Overviews](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/03/Gemini-Audio-Overview-cover.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)

![What’s new in Android’s April 2025 Google System Updates [U: 4/14]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-3.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













![Apple Seeds tvOS 18.5 Beta 2 to Developers [Download]](https://www.iclarified.com/images/news/97011/97011/97011-640.jpg)
![Apple Releases macOS Sequoia 15.5 Beta 2 to Developers [Download]](https://www.iclarified.com/images/news/97014/97014/97014-640.jpg)



















































































































Bad Data Is Breaking AI: The Cost, the Risks, and How to Fix It
AI promises better decisions, faster operations, and game-changing innovation. But when the data is wrong, everything breaks. Bad data has become one of the biggest and most underestimated threats to AI success. It causes models to fail, decisions to skew, and costs to spiral. This article explores how poor data quality impacts AI, examines the real-world damage it’s caused, and outlines practical strategies to fix it before it sinks your systems. The Business Impact of Bad Data Bad data is not just a technical nuisance, it’s a bottom-line killer. In 2016, IBM estimated that poor data quality cost U.S. companies around $3.1 trillion annually. More recent per-company estimates suggest the damage adds up to $12–15 million each year. On average, research shows bad data can erode 12% of a company’s revenue. That’s a massive hit to performance and profitability, one that compounds as AI becomes more central to business operations. Customer insight is one of the first areas to suffer. When data is inaccurate or incomplete, AI can’t properly segment users, personalize experiences, or predict behavior. This leads to wasted marketing spend, missed opportunities, and faulty automation. Some reports states that 88% of U.S. companies believed bad data had a direct impact on their ability to understand customers, resulting in lost revenue and reduced competitive edge. Real-World Failures That Trace Back to Bad Data The consequences of bad data aren’t abstract, they’ve played out in high-profile, costly, and public failures. In 2018, Samsung Securities accidentally issued 100 billion dollars worth of phantom shares due to a fat-finger error. Before the mistake could be corrected, employees had already sold about $300 million worth of nonexistent stock. That single input error spiraled into a financial and reputational crisis. Uber experienced a different kind of data problem in 2017, when it miscalculated commission rates and overcharged drivers. The company ended up repaying tens of millions, about $900 per driver because a simple data-processing error had gone unnoticed for months. Amazon ran into deeper, more systemic trouble with its AI hiring tool. Trained on historical resume data from a male-dominated industry, the tool learned to downgrade resumes that mentioned “women’s” organizations or came from all-women’s colleges. The bias was baked into the data, and as a result, the system became unusable. The project was scrapped in 2018, highlighting how easily bad data can introduce ethical and legal risks. More recently, Equifax made headlines in 2022 when a coding error caused credit scores for more than 300,000 consumers to be reported incorrectly. The mistake triggered legal challenges and a 5% drop in the company’s stock, further proof that data quality isn’t just about internal efficiency, it affects real people and public trust. Technical Failures and AI Performance Issues From a technical standpoint, bad data can cripple AI systems. Even small flaws lead to big drops in performance. A study from the University of Twente showed that just 5% mislabeled data can reduce model accuracy, while other research observed performance drops of up to 5% when support vector machines were trained on datasets with 20–30% mislabels. These aren’t minor dips, they can mean the difference between a system that works and one that fails in production. Bias is another critical issue. When training data reflects existing inequalities or errors, AI systems replicate and even amplify those patterns. Amazon’s hiring algorithm is the textbook example, but similar issues have been observed in facial recognition, healthcare diagnostics, and fraud detection. Another underappreciated consequence is data downtime, when AI systems or data pipelines break due to corrupt, missing, or malformed data. In a 2024 report from Dynatrace, 98% of tech leaders said they were concerned about AI’s vulnerability to bias, misinformation, and data error. These issues aren’t caught during development, they’re often discovered by end users. Different studies agree that almost 74% of data quality issues are first identified by stakeholders or customers, long after the damage is done. There are some projections that 85% of AI projects will fail to deliver meaningful results, with data quality named as one of the main culprits. When systems are built on shaky foundations, even the best models can’t make up the difference. The Scope of the Problem: Data Quality by the Numbers The scale of data quality challenges is massive. Harvard Business Review found that only 3% of enterprise data meets basic quality standards. While some estimates suggest 99% of AI projects encounter data-related issues, exact figures vary across studies. Still, the direction is clear: almost every AI system is wrestling with unreliable inputs. Operationally, this takes a toll on data teams. Data engineers reportedly spend 30–40% of t

AI promises better decisions, faster operations, and game-changing innovation. But when the data is wrong, everything breaks.
Bad data has become one of the biggest and most underestimated threats to AI success. It causes models to fail, decisions to skew, and costs to spiral.
This article explores how poor data quality impacts AI, examines the real-world damage it’s caused, and outlines practical strategies to fix it before it sinks your systems.
The Business Impact of Bad Data
Bad data is not just a technical nuisance, it’s a bottom-line killer. In 2016, IBM estimated that poor data quality cost U.S. companies around $3.1 trillion annually.
More recent per-company estimates suggest the damage adds up to $12–15 million each year. On average, research shows bad data can erode 12% of a company’s revenue. That’s a massive hit to performance and profitability, one that compounds as AI becomes more central to business operations.
Customer insight is one of the first areas to suffer. When data is inaccurate or incomplete, AI can’t properly segment users, personalize experiences, or predict behavior. This leads to wasted marketing spend, missed opportunities, and faulty automation.
Some reports states that 88% of U.S. companies believed bad data had a direct impact on their ability to understand customers, resulting in lost revenue and reduced competitive edge.
Real-World Failures That Trace Back to Bad Data
The consequences of bad data aren’t abstract, they’ve played out in high-profile, costly, and public failures.
In 2018, Samsung Securities accidentally issued 100 billion dollars worth of phantom shares due to a fat-finger error. Before the mistake could be corrected, employees had already sold about $300 million worth of nonexistent stock. That single input error spiraled into a financial and reputational crisis.
Uber experienced a different kind of data problem in 2017, when it miscalculated commission rates and overcharged drivers. The company ended up repaying tens of millions, about $900 per driver because a simple data-processing error had gone unnoticed for months.
Amazon ran into deeper, more systemic trouble with its AI hiring tool. Trained on historical resume data from a male-dominated industry, the tool learned to downgrade resumes that mentioned “women’s” organizations or came from all-women’s colleges. The bias was baked into the data, and as a result, the system became unusable. The project was scrapped in 2018, highlighting how easily bad data can introduce ethical and legal risks.
More recently, Equifax made headlines in 2022 when a coding error caused credit scores for more than 300,000 consumers to be reported incorrectly. The mistake triggered legal challenges and a 5% drop in the company’s stock, further proof that data quality isn’t just about internal efficiency, it affects real people and public trust.
Technical Failures and AI Performance Issues
From a technical standpoint, bad data can cripple AI systems. Even small flaws lead to big drops in performance. A study from the University of Twente showed that just 5% mislabeled data can reduce model accuracy, while other research observed performance drops of up to 5% when support vector machines were trained on datasets with 20–30% mislabels. These aren’t minor dips, they can mean the difference between a system that works and one that fails in production.
Bias is another critical issue. When training data reflects existing inequalities or errors, AI systems replicate and even amplify those patterns. Amazon’s hiring algorithm is the textbook example, but similar issues have been observed in facial recognition, healthcare diagnostics, and fraud detection.
Another underappreciated consequence is data downtime, when AI systems or data pipelines break due to corrupt, missing, or malformed data. In a 2024 report from Dynatrace, 98% of tech leaders said they were concerned about AI’s vulnerability to bias, misinformation, and data error. These issues aren’t caught during development, they’re often discovered by end users. Different studies agree that almost 74% of data quality issues are first identified by stakeholders or customers, long after the damage is done.
There are some projections that 85% of AI projects will fail to deliver meaningful results, with data quality named as one of the main culprits. When systems are built on shaky foundations, even the best models can’t make up the difference.
The Scope of the Problem: Data Quality by the Numbers
The scale of data quality challenges is massive. Harvard Business Review found that only 3% of enterprise data meets basic quality standards. While some estimates suggest 99% of AI projects encounter data-related issues, exact figures vary across studies. Still, the direction is clear: almost every AI system is wrestling with unreliable inputs.
Operationally, this takes a toll on data teams. Data engineers reportedly spend 30–40% of their time dealing with data quality issues, time that could otherwise go toward innovation or optimization. That firefighting mentality slows progress and increases technical debt, especially in fast-moving AI environments.
Looking ahead, the role of data quality is only going to grow. According to AIBase, by 2025, data quality will be a more important success factor in AI than the generative technologies getting most of the media attention today. And MIT Sloan’s 2025 trends report notes that organizations seeing the biggest productivity gains from AI are the ones that have invested in strong data foundations.
How to Fix It: Strategies for Clean, Reliable Data
Solving the data quality crisis requires more than one-off cleaning jobs. It demands structural change, cultural investment, and smart tooling. The first step is implementing automated data quality monitoring. Ideally systems that can track data freshness, schema changes, and volume anomalies in real-time, flagging issues before they hit production.
Equally important is assigning clear data ownership. When no one is responsible for data quality, problems slip through the cracks. Strong governance policies and data accountability structures help ensure consistency and integrity.
Training data also needs ongoing curation. AI models can’t be trained once and left alone. Data needs to be reviewed regularly for bias, labeling errors, and outdated information. Teams should treat training datasets as living assets, not static resources.
Finally, companies must foster a culture that prioritizes data quality. This includes educating teams about the real costs of bad data, aligning incentives with data reliability, and integrating data trust into every stage of AI development. It’s not just the job of data engineers anymore, it’s everyone’s responsibility.
Conclusion
Bad data is the silent killer of AI. It derails projects, drains resources, and destroys trust, often without being noticed until it’s too late.
But this isn’t a hopeless problem. With the right mix of monitoring tools, clear ownership, and cultural change, organizations can protect their AI investments and ensure that the systems they build deliver real value.
As we head deeper into 2025, one truth is becoming clear: the future of AI doesn’t just depend on better algorithms or more machine power, it also depends on better data.



