









































































































































































![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)







































































































































































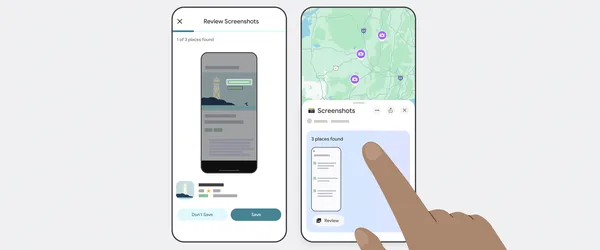














































































































































































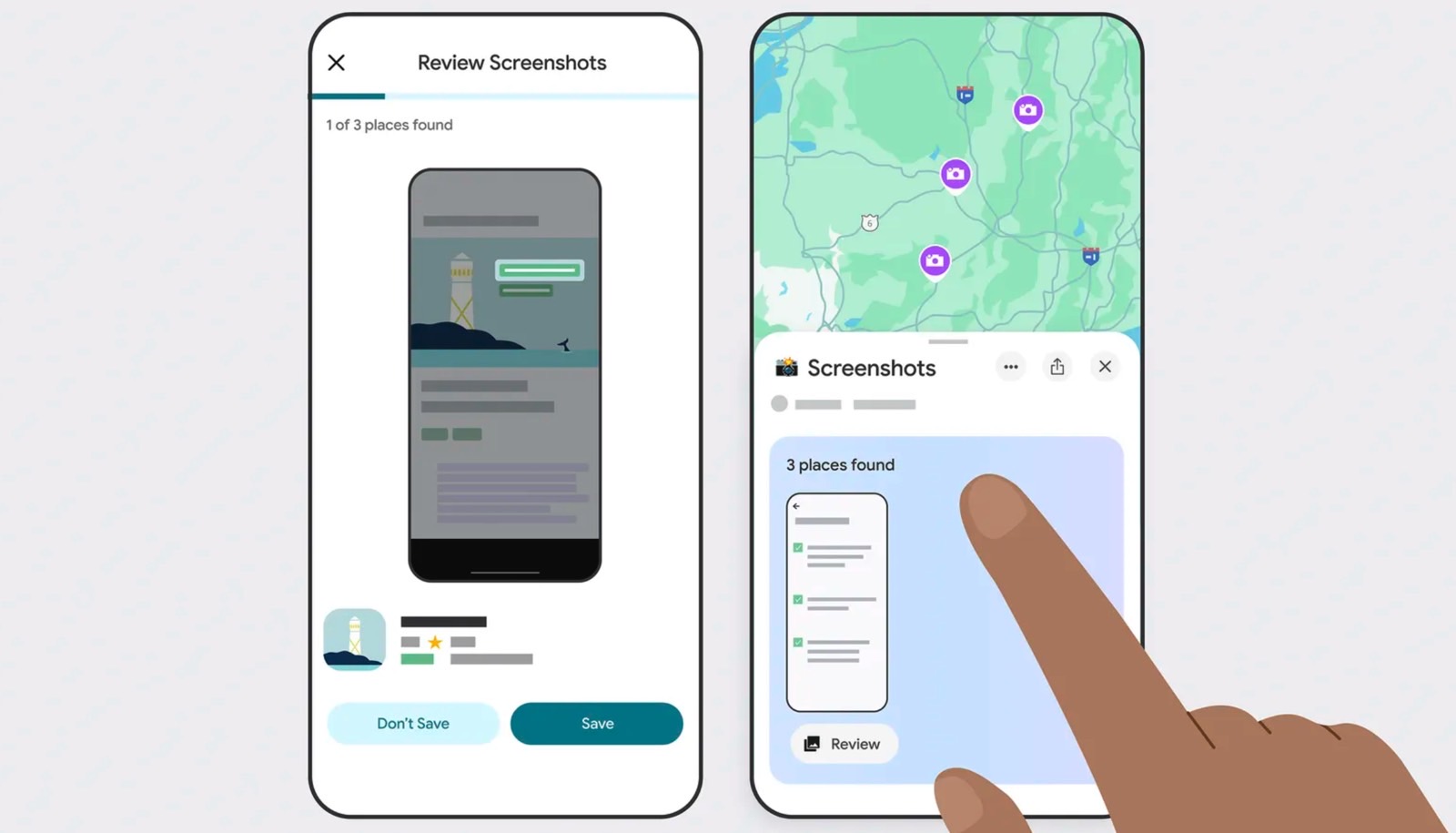



















![Honor 400 series officially launching on May 22 as design is revealed [Video]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/05/honor-400-series-announcement-1.png?resize=1200%2C628&quality=82&strip=all&ssl=1)













![Beats Studio Pro Wireless Headphones Now Just $169.95 - Save 51%! [Deal]](https://www.iclarified.com/images/news/97258/97258/97258-640.jpg)

























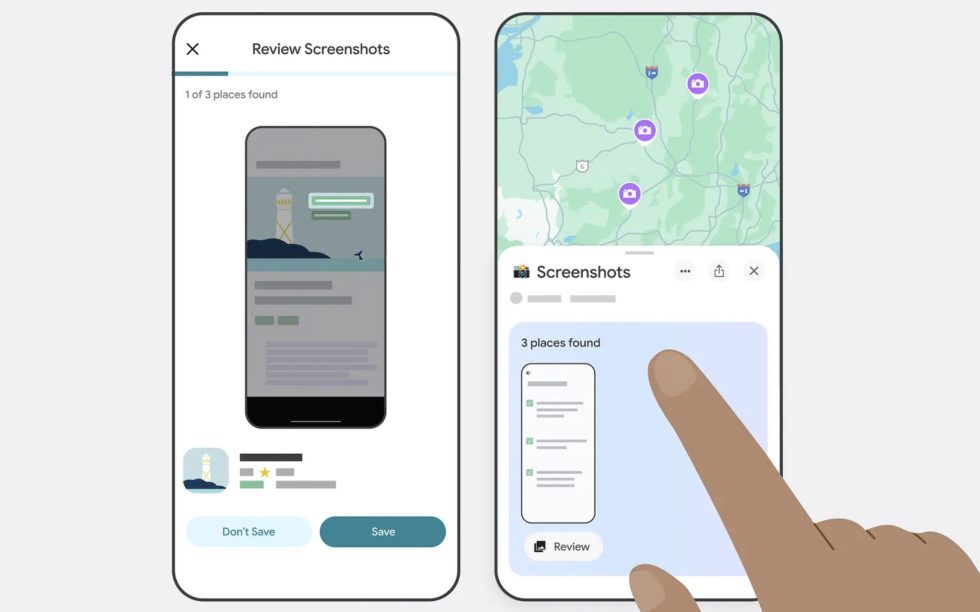















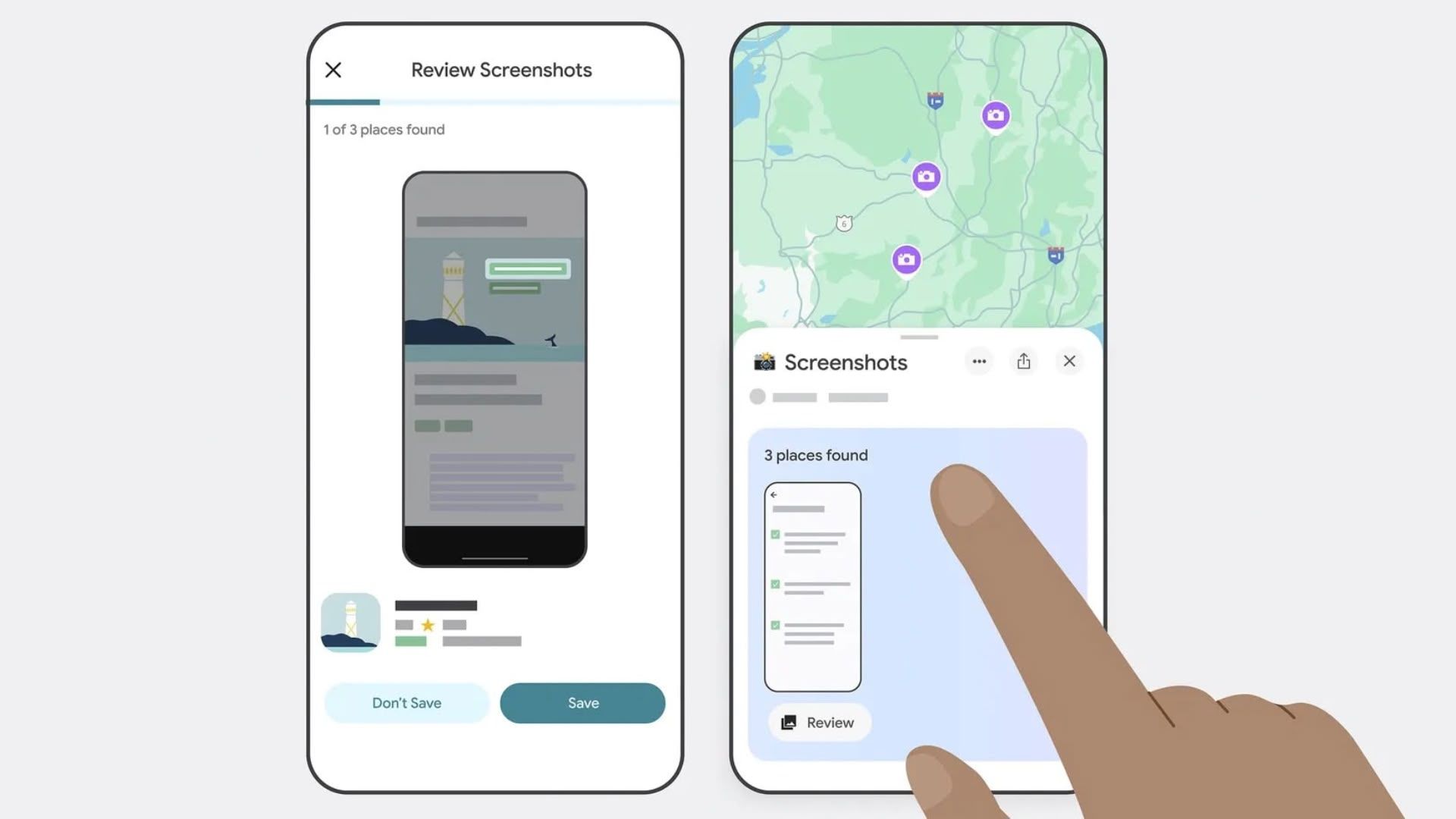


















































Why Data Versioning Matters in Machine Learning Projects
Building reproducible models' accuracy is equally essential with model performance results in today's rapidly evolving machine learning (ML) environment. The practice of tracking and managing changes to datasets through time receives insufficient attention despite the focus on selecting the correct algorithms and adjusting hyperparameters. Data versioning practice is a critical management system that succeeds or fails an entire ML project. Data versioning implementation remains crucial for both machine learning courses in Canada and professional practitioners of AI because it enables team-based collaboration with consistent and reproducible data across all teams. The upcoming section addresses the importance of data versioning and effective methods to integrate it into your ML pipeline. Why Data Versioning Matters Reproducibility and Traceability Machine learning functions best when researchers maintain the ability to reproduce their outcomes. Model result reproducibility transforms into a random guessing process when you fail to version your data. When you retrain your model, it should deliver uniform results after each dataset variation. However, imagine seeing different outcomes because new records were entered, fixed errors, or outdated content was removed from the dataset. With data versioning, you can precisely follow all changes to experiment data, making it possible to recreate previous research outcomes accurately. Efficient Collaboration Diverse collaboration remains the standard in most machine learning projects because they are often too complex to handle individually. Data scientists work alongside engineers and analysts to share their datasets and models within joint teams. The lack of proper data change management systems creates high risks because team collaboration produces confusion and model breakdowns and data duplicates. Data versioning establishes team-wide understanding so everyone uses the appropriate dataset rendition. Better Experiment Management Experiments comprise a significant component of machine learning systems. You modify different model parameters and transform pre-processing operations during your experiments. Different experimental sets demand specific data distributions and transformation procedures. By implementing version control, you can track data modifications to identify which setup brought the most positive performance results. Auditability and Compliance The need to abide by regulations is an absolute necessity within industries such as healthcare, finance, and self-driving vehicles. Businesses under regulatory obligations must disclose every detail about their training methods, including all dataset usages. Records in version-controlled datasets serve dual purposes by maintaining validity for audits and regulatory compliance. Students taking a machine learning course in Canada must complete real-world assignments involving compliance and audit capabilities, because these capabilities are essential for industrial work. How to Implement Data Versioning Moving forward, we will discuss the application methods for data versioning after we have discussed its critical importance. A systematic approach makes implementing the process simple according to your needs. File-Based Versioning A simple method known as file-based versioning works well for managing updates to CSV databases that don't exceed certain size thresholds. Using Git to track modifications works best on files that contain text content. Flawless data versioning results from storing different versions separately in dedicated directories named progressively following patterns such as data_v1.0, data_v1.1, and beyond. The operation requires the README documents for versioning notes and proper version-naming directories. Because standard Git works inefficiently with big datasets, you must implement Git LFS (Large File Storage) to manage such large files. Data Version Control (DVC) Data Version Control serves ML workflows through its Git integration, allowing researchers to version datasets alongside pipelines and models. DVC provides the vital functionality of tracking big files outside standard Git while maintaining full version control features. The tool provides an environment to duplicate your ML experiments through versioning data and code, and includes extensive dataset cloud storage capabilities. Students who study a machine learning course in Canada will gain special advantages by including DVC in their toolkit to handle complex projects. Cloud-Based Data Versioning AWS S3 and Azure and Google Cloud Storage provide native versioning features to their cloud storage platforms. When you activate storage versioning on your buckets, the system automatically preserves, retrieves, and restores all versions of your stored objects. Large-scale datasets benefit significantly from this method, delivering automated backup systems and seamless integration with automated ML pipelines. D

Building reproducible models' accuracy is equally essential with model performance results in today's rapidly evolving machine learning (ML) environment. The practice of tracking and managing changes to datasets through time receives insufficient attention despite the focus on selecting the correct algorithms and adjusting hyperparameters. Data versioning practice is a critical management system that succeeds or fails an entire ML project.
Data versioning implementation remains crucial for both machine learning courses in Canada and professional practitioners of AI because it enables team-based collaboration with consistent and reproducible data across all teams. The upcoming section addresses the importance of data versioning
and effective methods to integrate it into your ML pipeline.
Why Data Versioning Matters
- Reproducibility and Traceability Machine learning functions best when researchers maintain the ability to reproduce their outcomes. Model result reproducibility transforms into a random guessing process when you fail to version your data. When you retrain your model, it should deliver uniform results after each dataset variation. However, imagine seeing different outcomes because new records were entered, fixed errors, or outdated content was removed from the dataset. With data versioning, you can precisely follow all changes to experiment data, making it possible to recreate previous research outcomes accurately.
- Efficient Collaboration Diverse collaboration remains the standard in most machine learning projects because they are often too complex to handle individually. Data scientists work alongside engineers and analysts to share their datasets and models within joint teams. The lack of proper data change management systems creates high risks because team collaboration produces confusion and model breakdowns and data duplicates. Data versioning establishes team-wide understanding so everyone uses the appropriate dataset rendition.
- Better Experiment Management Experiments comprise a significant component of machine learning systems. You modify different model parameters and transform pre-processing operations during your experiments. Different experimental sets demand specific data distributions and transformation procedures. By implementing version control, you can track data modifications to identify which setup brought the most positive performance results.
- Auditability and Compliance The need to abide by regulations is an absolute necessity within industries such as healthcare, finance, and self-driving vehicles. Businesses under regulatory obligations must disclose every detail about their training methods, including all dataset usages. Records in version-controlled datasets serve dual purposes by maintaining validity for audits and regulatory compliance. Students taking a machine learning course in Canada must complete real-world assignments involving compliance and audit capabilities, because these capabilities are essential for industrial work.
How to Implement Data Versioning
Moving forward, we will discuss the application methods for data versioning after we have discussed its critical importance. A systematic approach makes implementing the process simple according to your needs.
- File-Based Versioning A simple method known as file-based versioning works well for managing updates to CSV databases that don't exceed certain size thresholds. Using Git to track modifications works best on files that contain text content. Flawless data versioning results from storing different versions separately in dedicated directories named progressively following patterns such as data_v1.0, data_v1.1, and beyond. The operation requires the README documents for versioning notes and proper version-naming directories. Because standard Git works inefficiently with big datasets, you must implement Git LFS (Large File Storage) to manage such large files.
- Data Version Control (DVC) Data Version Control serves ML workflows through its Git integration, allowing researchers to version datasets alongside pipelines and models. DVC provides the vital functionality of tracking big files outside standard Git while maintaining full version control features. The tool provides an environment to duplicate your ML experiments through versioning data and code, and includes extensive dataset cloud storage capabilities. Students who study a machine learning course in Canada will gain special advantages by including DVC in their toolkit to handle complex projects.
- Cloud-Based Data Versioning AWS S3 and Azure and Google Cloud Storage provide native versioning features to their cloud storage platforms. When you activate storage versioning on your buckets, the system automatically preserves, retrieves, and restores all versions of your stored objects. Large-scale datasets benefit significantly from this method, delivering automated backup systems and seamless integration with automated ML pipelines.
- Database Versioning In SQL-based data environments, seek database snapshots or implement Liquibase or Flyway tools to perform versioning for your tables and data schema. Time-based tag systems should be used for naming purposes, and you should keep your migration scripts accessible for reproduction.
Real-World Example: A versioning approach that applies to retail forecasting models
Building a model to predict retail product demand serves as our real-world example. Your team gathers new information, including seasonal data, promotional offers and competitor pricing, as it accumulates over time. Model retraining without proper data versioning makes it impossible to determine what factor led to performance enhancements between new features or data.
Data versioning will generate snapshots from your dataset when an update occurs. You register the version ID together with measurement results for the model's performance. You can return to earlier dataset versions while training your model with that specific data collection. AI and ML courses in Canada dedicate extensive instruction to this methodical method, which prioritizes practical application alongside the ability to reproduce results in the real world.
Integrating Data Versioning into ML Workflows
Data versioning represents an essential component that requires planning at the project's initiation stage. Data versioning needs to exist as an integral part of your workflow from the first step. Relational record keeping begins when you save raw data as version v1.0. The post-cleaning data transformation process would result in version v1.1. After applying feature engineering methods to your dataset, you should create version v1.2. You need to train your model through the v1.2 dataset input before capturing the resulting data. The final labeled model and dataset are deployed to production after you've applied version tags and implemented the push.
By making data a foremost component in your version control system, you will achieve stronger ML systems that are better documented and easier to manage. Many enterprise organizations are implementing this approach, while it remains a fundamental aspect of AI and ML courses in Canadian institutions.
Final Thoughts
Machine learning development relies fundamentally on data versioning because it establishes a necessary foundation for responsible work with efficient, scalable systems. Integration of data versioning systems into your workflow adds value through increased efficiency alongside better accuracy and certifiable reproducibility for practitioners at every skill level.
You need to establish machine learning expertise along with industry practice skills, including data versioning. Students can choose between a machine learning course in Canada or study comprehensive AI and ML courses in Canada, which combine theoretical and practical training. Both your future models and you will experience gratitude because of your current actions.



