











































































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)







































































































































































































































.png?#)







































.webp?#)























































































![[Fixed] Gemini app is failing to generate Audio Overviews](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/03/Gemini-Audio-Overview-cover.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)

![What’s new in Android’s April 2025 Google System Updates [U: 4/14]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-3.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)














![Apple Seeds tvOS 18.5 Beta 2 to Developers [Download]](https://www.iclarified.com/images/news/97011/97011/97011-640.jpg)
![Apple Releases macOS Sequoia 15.5 Beta 2 to Developers [Download]](https://www.iclarified.com/images/news/97014/97014/97014-640.jpg)


















































































































"Unlocking Parallel LLMs: The Future of Efficient AI Collaboration"
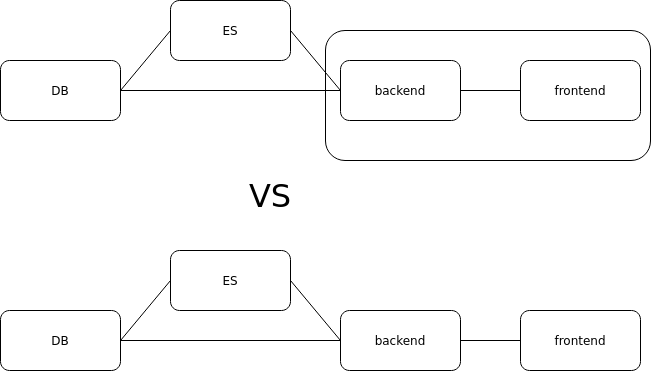
In a world where artificial intelligence is rapidly evolving, the quest for efficiency and collaboration has never been more critical. Have you ever felt overwhelmed by the sheer volume of data your AI systems must process? Or perhaps you've struggled to harness the full potential of multiple language models working in tandem? If so, you're not alone. Enter Parallel LLMs—an innovative approach that promises to revolutionize how we leverage AI capabilities across various domains. In this blog post, we'll demystify what Parallel LLMs are and explore their transformative benefits, from enhanced processing speeds to improved accuracy in real-world applications. But it's not all smooth sailing; we'll also address the challenges organizations face when implementing these cutting-edge technologies and discuss future trends that could shape AI collaboration as we know it. Whether you're an industry expert or just starting your journey into AI, understanding Parallel LLMs can unlock new avenues for growth and innovation in your projects. So join us as we delve deep into this exciting frontier of technology—your next breakthrough might be just a read away! What are Parallel LLMs? Parallel Large Language Models (LLMs) utilize concurrent attention synchronization to enhance performance in natural language processing tasks. The "Hogwild! Inference" approach is central to this concept, allowing multiple LLM instances to operate simultaneously while sharing a Key-Value cache. This method significantly improves hardware utilization and reduces latency during inference. Rotary Position Embeddings (RoPE) play a crucial role by facilitating better positional encoding, which enhances the model's ability to understand context across different inputs. Collaborative Problem-Solving The implementation of parallel inference not only boosts efficiency but also fosters collaboration among various models, enabling them to tackle complex problems more effectively. Research indicates that dynamic interaction among workers can lead to improved outcomes in reasoning and error detection within language models. Moreover, studies have demonstrated the effectiveness of alternative memory layouts for collaborative inference setups, showcasing how flexibility and adaptability are vital for optimizing performance in real-time applications. In summary, Parallel LLMs represent an innovative advancement in AI technology that leverages concurrency mechanisms for enhanced problem-solving capabilities across diverse fields such as machine learning and artificial intelligence. Benefits of Using Parallel LLMs Utilizing parallel Large Language Models (LLMs) offers significant advantages in enhancing computational efficiency and accuracy. The "Hogwild! Inference" approach facilitates concurrent attention synchronization, allowing multiple LLM instances to operate simultaneously while sharing a Key-Value cache. This setup not only optimizes hardware utilization but also reduces latency during inference tasks. By implementing Rotary Position Embeddings (RoPE), the models can better manage memory layouts for collaborative inference, leading to improved problem-solving capabilities. Enhanced Problem-Solving Efficiency Parallel LLMs foster collaboration among various model instances, enabling them to tackle complex problems more effectively than single-threaded approaches. This dynamic interaction enhances adaptability and flexibility within the system, addressing challenges such as computation overhead associated with traditional parallel computing methods. Furthermore, ongoing research into attention concurrency mechanisms promises even greater improvements in performance metrics like speed and accuracy. By leveraging interdisciplinary insights from natural language processing and machine learning domains, parallel LLMs are positioned at the forefront of AI advancements. Their ability to generate content across diverse formats—such as blogs or infographics—demonstrates their versatility and potential impact on future applications in technology-driven environments. Real-World Applications of Parallel LLMs Parallel Large Language Models (LLMs) are revolutionizing various fields by enhancing the efficiency and accuracy of natural language processing tasks. One significant application is in collaborative problem-solving, where multiple LLM instances can work concurrently to tackle complex queries or generate content. For instance, using the Hogwild! Inference approach allows for synchronized attention mechanisms that enable real-time collaboration among models, improving overall performance. Enhancing Content Generation In creative industries, parallel LLMs facilitate rapid content generation across different formats such as blogs, videos, and infographics. By leveraging shared Key-Value caches and Rotary Position Embeddings (RoPE), these models optimize hardware utilization while maintaining high-quality outputs. Additionally, projects like Om

In a world where artificial intelligence is rapidly evolving, the quest for efficiency and collaboration has never been more critical. Have you ever felt overwhelmed by the sheer volume of data your AI systems must process? Or perhaps you've struggled to harness the full potential of multiple language models working in tandem? If so, you're not alone. Enter Parallel LLMs—an innovative approach that promises to revolutionize how we leverage AI capabilities across various domains. In this blog post, we'll demystify what Parallel LLMs are and explore their transformative benefits, from enhanced processing speeds to improved accuracy in real-world applications. But it's not all smooth sailing; we'll also address the challenges organizations face when implementing these cutting-edge technologies and discuss future trends that could shape AI collaboration as we know it. Whether you're an industry expert or just starting your journey into AI, understanding Parallel LLMs can unlock new avenues for growth and innovation in your projects. So join us as we delve deep into this exciting frontier of technology—your next breakthrough might be just a read away!
What are Parallel LLMs?
Parallel Large Language Models (LLMs) utilize concurrent attention synchronization to enhance performance in natural language processing tasks. The "Hogwild! Inference" approach is central to this concept, allowing multiple LLM instances to operate simultaneously while sharing a Key-Value cache. This method significantly improves hardware utilization and reduces latency during inference. Rotary Position Embeddings (RoPE) play a crucial role by facilitating better positional encoding, which enhances the model's ability to understand context across different inputs.
Collaborative Problem-Solving
The implementation of parallel inference not only boosts efficiency but also fosters collaboration among various models, enabling them to tackle complex problems more effectively. Research indicates that dynamic interaction among workers can lead to improved outcomes in reasoning and error detection within language models. Moreover, studies have demonstrated the effectiveness of alternative memory layouts for collaborative inference setups, showcasing how flexibility and adaptability are vital for optimizing performance in real-time applications.
In summary, Parallel LLMs represent an innovative advancement in AI technology that leverages concurrency mechanisms for enhanced problem-solving capabilities across diverse fields such as machine learning and artificial intelligence.
Benefits of Using Parallel LLMs
Utilizing parallel Large Language Models (LLMs) offers significant advantages in enhancing computational efficiency and accuracy. The "Hogwild! Inference" approach facilitates concurrent attention synchronization, allowing multiple LLM instances to operate simultaneously while sharing a Key-Value cache. This setup not only optimizes hardware utilization but also reduces latency during inference tasks. By implementing Rotary Position Embeddings (RoPE), the models can better manage memory layouts for collaborative inference, leading to improved problem-solving capabilities.
Enhanced Problem-Solving Efficiency
Parallel LLMs foster collaboration among various model instances, enabling them to tackle complex problems more effectively than single-threaded approaches. This dynamic interaction enhances adaptability and flexibility within the system, addressing challenges such as computation overhead associated with traditional parallel computing methods. Furthermore, ongoing research into attention concurrency mechanisms promises even greater improvements in performance metrics like speed and accuracy.
By leveraging interdisciplinary insights from natural language processing and machine learning domains, parallel LLMs are positioned at the forefront of AI advancements. Their ability to generate content across diverse formats—such as blogs or infographics—demonstrates their versatility and potential impact on future applications in technology-driven environments.

Real-World Applications of Parallel LLMs
Parallel Large Language Models (LLMs) are revolutionizing various fields by enhancing the efficiency and accuracy of natural language processing tasks. One significant application is in collaborative problem-solving, where multiple LLM instances can work concurrently to tackle complex queries or generate content. For instance, using the Hogwild! Inference approach allows for synchronized attention mechanisms that enable real-time collaboration among models, improving overall performance.
Enhancing Content Generation
In creative industries, parallel LLMs facilitate rapid content generation across different formats such as blogs, videos, and infographics. By leveraging shared Key-Value caches and Rotary Position Embeddings (RoPE), these models optimize hardware utilization while maintaining high-quality outputs. Additionally, projects like OmniSVG demonstrate how parallel inference can streamline workflows in generating complex SVG graphics from text and images efficiently.
Advancements in Research Collaboration
Moreover, interdisciplinary research benefits significantly from parallel LLM applications. They enhance reasoning capabilities and error detection through dynamic interactions among model workers. This adaptability fosters innovative solutions across diverse domains such as machine learning and artificial intelligence—showcasing a promising future for collaborative AI systems in tackling multifaceted challenges effectively.# Challenges in Implementing Parallel LLMs
Implementing parallel Large Language Models (LLMs) presents several challenges that can hinder their effectiveness. One significant issue is the computation overhead associated with parallel computing, which can lead to inefficiencies if not managed properly. The Hogwild! Inference approach aims to synchronize concurrent attention but requires careful orchestration among multiple model instances to avoid contention and ensure optimal performance. Additionally, the integration of Rotary Position Embeddings (RoPE) for enhanced hardware utilization introduces complexity in memory management and layout configurations necessary for collaborative inference tasks. Ensuring dynamic interaction among workers while maintaining flexibility and adaptability further complicates implementation efforts.
Memory Management Concerns
Another challenge lies in managing shared Key-Value caches across different LLM instances during inference. This necessitates a robust architecture capable of efficiently handling data flow without introducing latency or bottlenecks. Moreover, as models scale up, ensuring accuracy while minimizing resource consumption becomes increasingly difficult; thus, ongoing research into alternative concurrency mechanisms is essential for improving overall system efficiency and reliability in practical applications of parallel LLMs.# Future Trends in AI Collaboration
The future of AI collaboration is poised to be significantly shaped by advancements in parallel Large Language Models (LLMs) and their efficient synchronization. The "Hogwild! Inference" approach, which allows for concurrent attention mechanisms among multiple LLM instances, will likely become a cornerstone of collaborative problem-solving frameworks. This method not only enhances hardware utilization through Rotary Position Embeddings (RoPE) but also facilitates dynamic interactions among models, promoting adaptability in real-time applications. As researchers explore alternative schemes for parallel inference and address challenges such as computation overhead, we can expect an increase in interdisciplinary projects that leverage these technologies across various domains.
Enhancing Problem-Solving Efficiency
Future trends will emphasize the need for flexible architectures that support seamless integration between different LLMs. By utilizing shared Key-Value caches and innovative memory layouts, teams can enhance collaborative efficiency while minimizing latency during inference tasks. Furthermore, ongoing research into attention concurrency mechanisms promises to refine how models interact with one another—ultimately leading to more sophisticated reasoning capabilities and error detection methods within language processing systems. These developments are expected to foster greater innovation across industries reliant on natural language understanding and generation.
Getting Started with Parallel LLMs
To effectively engage with parallel Large Language Models (LLMs), one must understand the foundational concepts and techniques involved. The "Hogwild! Inference" approach is pivotal, allowing for concurrent attention synchronization across multiple instances of LLMs. This method enhances hardware utilization through innovative strategies like Rotary Position Embeddings (RoPE) and shared Key-Value caches, which facilitate collaborative inference. When starting out, it’s essential to explore various memory layouts that optimize performance while addressing computation overhead challenges inherent in parallel computing environments.
Implementation Strategies
Begin by setting up a robust infrastructure capable of supporting dynamic interactions among workers. Flexibility in model architecture will allow adaptation to different tasks and datasets, such as those found in natural language processing or machine learning projects. Experimenting with diverse configurations can yield insights into efficiency gains during problem-solving processes. Future research directions may include refining attention concurrency mechanisms and developing alternative schemes tailored for specific applications within AI collaboration frameworks.
By leveraging interdisciplinary approaches, practitioners can enhance their understanding of how these models function collectively, leading to improved reasoning capabilities and error detection methodologies within complex systems.

In conclusion, the exploration of Parallel LLMs reveals a transformative potential for AI collaboration that can significantly enhance efficiency and productivity across various sectors. By understanding what Parallel LLMs are and their inherent benefits, such as improved processing speed and resource optimization, organizations can harness these models to drive innovation. Real-world applications demonstrate their versatility in fields ranging from healthcare to finance, showcasing how they can solve complex problems collaboratively. However, challenges like integration complexities and data privacy concerns must be addressed to fully realize their capabilities. As we look toward future trends in AI collaboration, it becomes evident that adopting Parallel LLMs will not only streamline workflows but also foster an environment ripe for creative solutions. For those eager to embark on this journey, starting with a clear strategy will be essential in unlocking the full potential of these advanced technologies.
FAQs about Parallel LLMs
1. What are Parallel LLMs?
Parallel LLMs, or Large Language Models, refer to a framework where multiple language models operate simultaneously to process and generate text more efficiently. This approach leverages the strengths of various models working in tandem, allowing for improved performance in tasks such as natural language understanding and generation.
2. What are the benefits of using Parallel LLMs?
The primary benefits of using Parallel LLMs include enhanced processing speed, increased accuracy through collaborative learning, and the ability to handle larger datasets effectively. Additionally, they can reduce computational costs by distributing workloads across different models rather than relying on a single model.
3. How are Parallel LLMs applied in real-world scenarios?
Parallel LLMs have been successfully implemented in various domains including customer service chatbots that provide instant responses by analyzing multiple queries at once, content creation tools that assist writers with suggestions from diverse perspectives, and advanced translation services that improve accuracy by considering context from several languages concurrently.
4. What challenges exist when implementing Parallel LLMs?
Implementing Parallel LLMs comes with challenges such as managing communication between different models to ensure coherence in outputs, addressing potential latency issues due to simultaneous processing demands, and ensuring data privacy while sharing information among parallel systems.
5. What future trends can we expect in AI collaboration involving Parallel LLMs?
Future trends may include greater integration of multi-modal capabilities (combining text with images or audio), advancements in federated learning techniques for better privacy protection during training processes, and ongoing improvements in model interoperability which will enhance collaborative efforts across various AI applications.



