















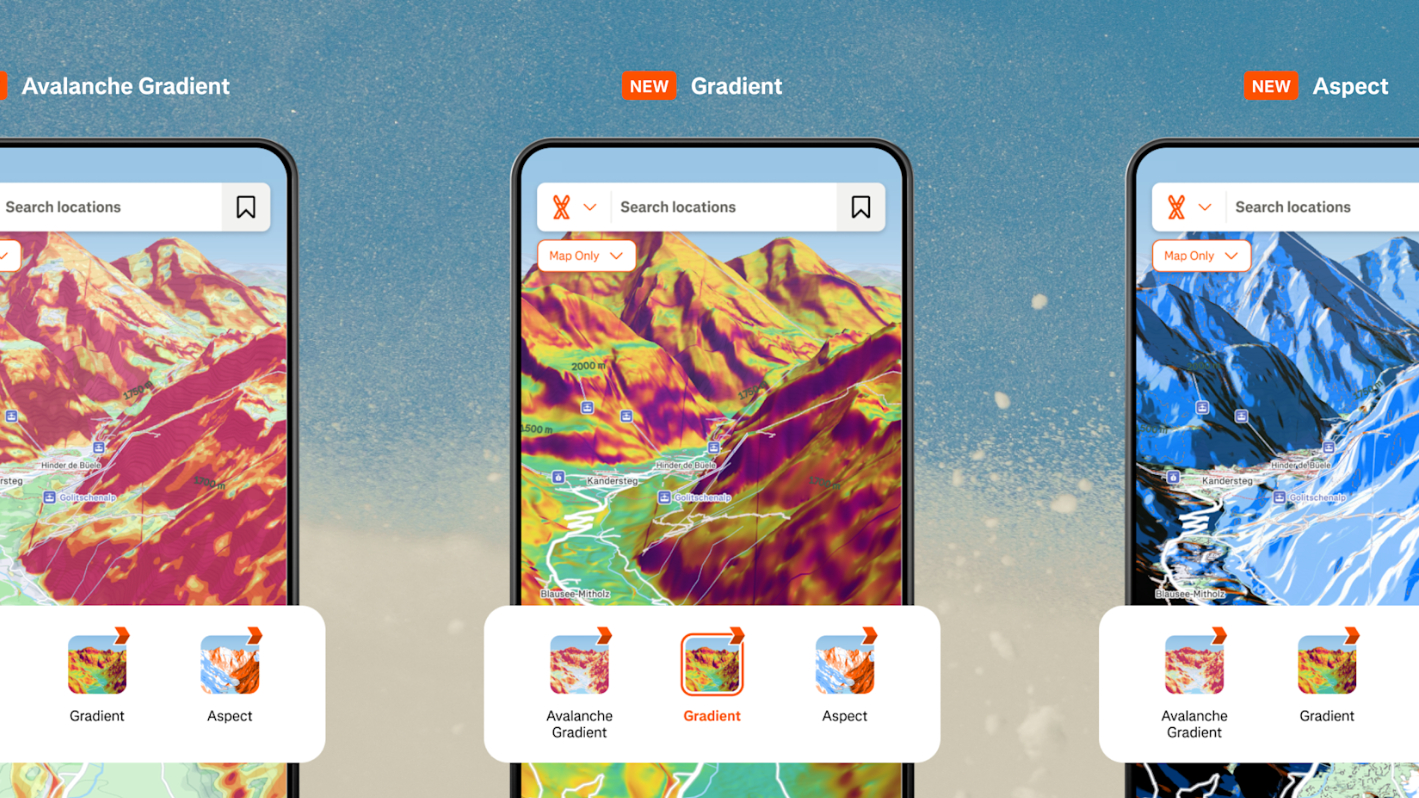

























































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)





































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)


















![What are the Best Practices for Structuring Modern Website Design and Development Services for Scalable Projects? [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)























.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)
































































.jpg?#)






.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)

























_ArtemisDiana_Alamy.jpg?#)









































































-xl.jpg)









![Yes, the Gemini icon is now bigger and brighter on Android [U]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/02/Gemini-on-Galaxy-S25.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)











![Apple Rushes Five Planes of iPhones to US Ahead of New Tariffs [Report]](https://www.iclarified.com/images/news/96967/96967/96967-640.jpg)
![Apple Vision Pro 2 Allegedly in Production Ahead of 2025 Launch [Rumor]](https://www.iclarified.com/images/news/96965/96965/96965-640.jpg)























































































































Streaming Large Files Between Microservices: A Go Implementation
Efficient Large Data Transfer Between Microservices (Go Demo) This project provides a practical demonstration in Go for efficiently transferring large files or data payloads between microservices. It seeks to directly address the challenge posed by Sumit Mukhija in this tweet: "Your microservice needs to transfer large amounts of data (e.g., files, images) between services. How do you design the communication to avoid performance bottlenecks and manage large payloads efficiently?" This implementation showcases a solution using standard HTTP protocols, focusing on: Memory Efficiency: Avoids loading entire large files into memory on either the client or server side. Bandwidth Efficiency: Uses selective compression to reduce network traffic for suitable content types. Resilience: Implements resumable downloads to handle network interruptions gracefully. Performance: Optimizes I/O using buffered readers/writers and standard library features. The entire code for this implementation can be found here. Key Features Chunked Transfers: Uses HTTP Range requests to transfer data in manageable chunks (configurable size). Resumable Downloads: The client can resume downloads from where they left off if interrupted. Selective Gzip Compression: The server intelligently compresses individual chunks based on content type and chunk size, only when beneficial and supported by the client (Accept-Encoding: gzip). Memory Efficiency: Leverages io.Reader, io.Writer, io.LimitReader, and bufio for streaming data without high memory allocation. Standard HTTP Protocols: Relies entirely on standard HTTP/1.1 features (HEAD, GET, Range headers, Content-Encoding) for maximum interoperability. Graceful Shutdown: Both client and server handle OS interrupt signals (SIGINT, SIGTERM, SIGHUP) for clean termination. Content Type Detection: Server uses file extension and content sniffing (http.DetectContentType) to determine MIME types for compression decisions. How it Works PS: A lot of folks in the replies to the tweet suggested different variations of "Put it on S3" and while I do not disagree- I actually do agree it is quite an efficient solution- but there's no fun in that and it doesn't relieve you of the JIRA ticket for getting the file from one service to another [S3 is a service]. Server Client sends us a Head request and we respond with the size of the file. This response is used by the client for different purposes but mainly to know if this is a partially downloaded file so we can resume the download. It can theoretically be used to choose the optimal chunk size to optimize the overhead of network requests. fileName := r.PathValue("fileName") // ensure this request is not trying to do something fishy if strings.Contains(fileName, "..") { http.Error(w, http.StatusText(http.StatusBadRequest), http.StatusBadRequest) return } dir, err := os.Getwd() if err != nil { http.Error(w, err.Error(), http.StatusInternalServerError) return } fileName = path.Join(dir, ContentFolderName, fileName) file, err := os.Open(fileName) if err != nil { http.Error(w, err.Error(), http.StatusInternalServerError) return } stat, err := file.Stat() if err != nil { http.Error(w, err.Error(), http.StatusInternalServerError) return } // if it is a head request, we send back the file size. The client will use // that data for resumability i.e to tell us if parts of the file have already // been downloaded and therefore where to resume from. The client can also use // the size to decide how to chunk the data to achieve a balance between number // of http calls and download speed per chunk. if r.Method == http.MethodHead { w.Header().Set("Content-Length", fmt.Sprintf("%d", stat.Size())) return } The client now sends further GET requests to the same endpoint with a range header. This range header is what we will use -like my favorite software, the browser- to stream the response back to the client: // Parse range header (required for our implementation) rangeHeader := r.Header.Get("Range") if rangeHeader == "" { http.Error(w, "Range header required", http.StatusBadRequest) return } // Parse the range var start, end int64 n, err := fmt.Sscanf(rangeHeader, "bytes=%d-%d", &start, &end) if err != nil || n != 2 { http.Error(w, "Invalid range format", http.StatusBadRequest) return } // Validate range if start = MinCompressionSize // Only compress chunks >= 8KB if shouldCompress { // For compressed chunks w.Header().Set("Content-Encoding", "gzip") // Cannot predict final Content-Length after compression // Set partial content status w.Header().Set("Content-Range", fmt.Sprintf("bytes %d-%d/%d", start, end, stat.S

Efficient Large Data Transfer Between Microservices (Go Demo)
This project provides a practical demonstration in Go for efficiently transferring large files or data payloads between microservices. It seeks to directly address the challenge posed by Sumit Mukhija in this tweet:
"Your microservice needs to transfer large amounts of data (e.g., files, images) between services. How do you design the communication to avoid performance bottlenecks and manage large payloads efficiently?"
This implementation showcases a solution using standard HTTP protocols, focusing on:
- Memory Efficiency: Avoids loading entire large files into memory on either the client or server side.
- Bandwidth Efficiency: Uses selective compression to reduce network traffic for suitable content types.
- Resilience: Implements resumable downloads to handle network interruptions gracefully.
- Performance: Optimizes I/O using buffered readers/writers and standard library features.
The entire code for this implementation can be found here.
Key Features
- Chunked Transfers: Uses HTTP
Rangerequests to transfer data in manageable chunks (configurable size). - Resumable Downloads: The client can resume downloads from where they left off if interrupted.
- Selective Gzip Compression: The server intelligently compresses individual chunks based on content type and chunk size, only when beneficial and supported by the client (
Accept-Encoding: gzip). - Memory Efficiency: Leverages
io.Reader,io.Writer,io.LimitReader, andbufiofor streaming data without high memory allocation. - Standard HTTP Protocols: Relies entirely on standard HTTP/1.1 features (HEAD, GET, Range headers, Content-Encoding) for maximum interoperability.
- Graceful Shutdown: Both client and server handle OS interrupt signals (SIGINT, SIGTERM, SIGHUP) for clean termination.
- Content Type Detection: Server uses file extension and content sniffing (
http.DetectContentType) to determine MIME types for compression decisions.
How it Works
PS: A lot of folks in the replies to the tweet suggested different variations of "Put it on S3" and while I do not disagree- I actually do agree it is quite an efficient solution- but there's no fun in that and it doesn't relieve you of the JIRA ticket for getting the file from one service to another [S3 is a service].
Server
Client sends us a Head request and we respond with the size of the file. This response is used by the client for different purposes but mainly to know if this is a partially downloaded file so we can resume the download. It can theoretically be used to choose the optimal chunk size to optimize the overhead of network requests.
fileName := r.PathValue("fileName")
// ensure this request is not trying to do something fishy
if strings.Contains(fileName, "..") {
http.Error(w, http.StatusText(http.StatusBadRequest), http.StatusBadRequest)
return
}
dir, err := os.Getwd()
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
fileName = path.Join(dir, ContentFolderName, fileName)
file, err := os.Open(fileName)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
stat, err := file.Stat()
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
// if it is a head request, we send back the file size. The client will use
// that data for resumability i.e to tell us if parts of the file have already
// been downloaded and therefore where to resume from. The client can also use
// the size to decide how to chunk the data to achieve a balance between number
// of http calls and download speed per chunk.
if r.Method == http.MethodHead {
w.Header().Set("Content-Length", fmt.Sprintf("%d", stat.Size()))
return
}
The client now sends further GET requests to the same endpoint with a range header. This range header is what we will use -like my favorite software, the browser- to stream the response back to the client:
// Parse range header (required for our implementation)
rangeHeader := r.Header.Get("Range")
if rangeHeader == "" {
http.Error(w, "Range header required", http.StatusBadRequest)
return
}
// Parse the range
var start, end int64
n, err := fmt.Sscanf(rangeHeader, "bytes=%d-%d", &start, &end)
if err != nil || n != 2 {
http.Error(w, "Invalid range format", http.StatusBadRequest)
return
}
// Validate range
if start < 0 || end < start || end >= stat.Size() {
http.Error(w, "Invalid range", http.StatusRequestedRangeNotSatisfiable)
return
}
chunkSize := end - start + 1
contentType := getContentType(fileName, file)
w.Header().Set("Content-Type", contentType)
Now, that we have parsed the range headers and have the chunk size, this is where it gets interesting. We have to find the requested chunk in the file but we must also ensure not to put the entire chunk in memory. We also have to make a decision on compression. If it is a compression friendly file eg., text based files, we compress the chunk else we just stream the chunk back to the client:
// Set the file offset to the provided start point.
// We do not want to read from the start of the file.
// We want to "resume" from where they stopped
_, err = file.Seek(start, io.SeekStart)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
// Create a limited reader for just this chunk.
// Why? This is exactly why it exists. Alternatively, we could create a
// buffer to minimize syscalls but it won't be necessary here.
// We use io.copy to stream the response to the client. Given we also don't
// know what is contained in the file, we will have to read the whole chunk size
// into memory:
//
// data := make([]byte, chunkSize)
// reader := bufio.NewReader(file)
// n, _ := reader.Read(data)
//
// we have already added 516kb of memory to the program [512 for chunk size
// and 4kb for the buffer] and lost the benefits of streaming. Just 10 concurrent
// requests and we are already at 5mb of memory.
//
// Meanwhile we already have io.Copy with its buffer that streams 32kb chunks from the file to the connection.
reader := io.LimitReader(file, chunkSize)
Now, we make a decision on compression. First, we check if the client supports compression- we use just gzip to keep it simple- and the file is compression friendly, and it is above 8kb which is the threshold where compression has benefits (according to our AI overlords btw. Gemini, GPT 4, and Claude 3.7 Sonnet all said the same thing so it must be true). If it is compression friendly, we compress it and use io.Copy to stream the chunk from the file (through the LimitReader) to the client. At no point, do we have the entire chunk or file in memory or in transit. The LimitReader will read from the file up till the chunk size and then return EOF.
acceptsGzip := strings.Contains(r.Header.Get("Accept-Encoding"), "gzip")
shouldCompress := acceptsGzip &&
isCompressibleType(contentType) &&
chunkSize >= MinCompressionSize // Only compress chunks >= 8KB
if shouldCompress {
// For compressed chunks
w.Header().Set("Content-Encoding", "gzip")
// Cannot predict final Content-Length after compression
// Set partial content status
w.Header().Set("Content-Range", fmt.Sprintf("bytes %d-%d/%d", start, end, stat.Size()))
w.WriteHeader(http.StatusPartialContent)
// Create gzip writer with fast compression
gz, err := gzip.NewWriterLevel(w, gzip.BestSpeed)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
defer gz.Close()
// Send compressed chunk
_, err = io.Copy(gz, reader)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
return
}
// For uncompressed chunks
w.Header().Set("Content-Length", fmt.Sprintf("%d", chunkSize))
w.Header().Set("Content-Range", fmt.Sprintf("bytes %d-%d/%d", start, end, stat.Size()))
w.WriteHeader(http.StatusPartialContent)
// Send uncompressed chunk
_, err = io.Copy(w, reader)
if err != nil {
log.Printf("Error sending chunk: %v", err)
return
}
Client
The client is a simpler implementation. We get the file size from the server with a HEAD request and check to see if it is a fresh download or a partial download.
fileName := r.PathValue("fileName")
if strings.Contains(fileName, "..") {
http.Error(w, http.StatusText(http.StatusBadRequest), http.StatusBadRequest)
return
}
file, err := os.OpenFile(fileName, os.O_CREATE|os.O_RDWR, 0666)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
defer file.Close()
// Get file info to check existing size
stat, err := file.Stat()
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
fileSize := stat.Size()
client := http.DefaultClient
url := fmt.Sprintf("%s/download/%s", serviceUrl, fileName)
// make head request to get the file size. this helps with resumability
req, err := http.NewRequestWithContext(r.Context(), http.MethodHead, url, nil)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
res, err := client.Do(req)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
defer res.Body.Close()
if res.StatusCode != http.StatusOK {
var b bytes.Buffer
_, err := io.Copy(&b, res.Body)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
http.Error(w, b.String(), http.StatusInternalServerError)
return
}
totalSize := res.ContentLength
if fileSize >= totalSize {
w.Write([]byte("File already downloaded"))
return
}
Now, we also want to stream the chunks to the file. We will use a 64kb buffer to do this. 64kb is a small price to pay for the chance to reduce our syscalls for writing to the file by half. We have to benchmark this to know but for now I am using my intuition and I also asked our AI overlords to confirm my bias [systematic error as the late Daniel Kahnemann calls it]. This is also where we add resumability. We are going to seek to the last place the file was written to.
// set file offset to last offset we wrote to, this is where
// we do resumability
_, err = file.Seek(fileSize, io.SeekStart)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
// create a 64kb buffer to stream the response to the file
// why? we want to minimize the amount of system calls we make
// we want to hit the sweet spot between memory consumption
// and cpu usage.
writer := bufio.NewWriterSize(file, bufferSize)
defer writer.Flush()
Finally, we request those chunks in multiple GET requests.
// we make http requests to get each chunk of data
for start := fileSize; start < totalSize; start += chunkSize {
end := start + chunkSize - 1
if end > totalSize {
end = totalSize - 1
}
statusCode, err := downloadChunk(r.Context(), client, writer, url, start, end)
if err != nil {
http.Error(w, err.Error(), statusCode)
return
}
}
There was a temptation to parallelize this with SectionReaders but I decided against it because I can, the complexity tradeoff wasn't worth it for me, and getting it to work with resumability is beyond my skillset- so yeah me, me, me.
Alternative Approaches
- gRPC streaming
- Message queues with chunked messages
- S3/blob storage as intermediary
- Dedicated file transfer protocols
Why the HTTP approach was chosen
My skill issues.
Thanks for reading. Comments and opinions [that argue in my favour] appreciated.



