![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)




































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)
















































































































(1).jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)






























_NicoElNino_Alamy.png?#)
.webp?#)
.webp?#)







































































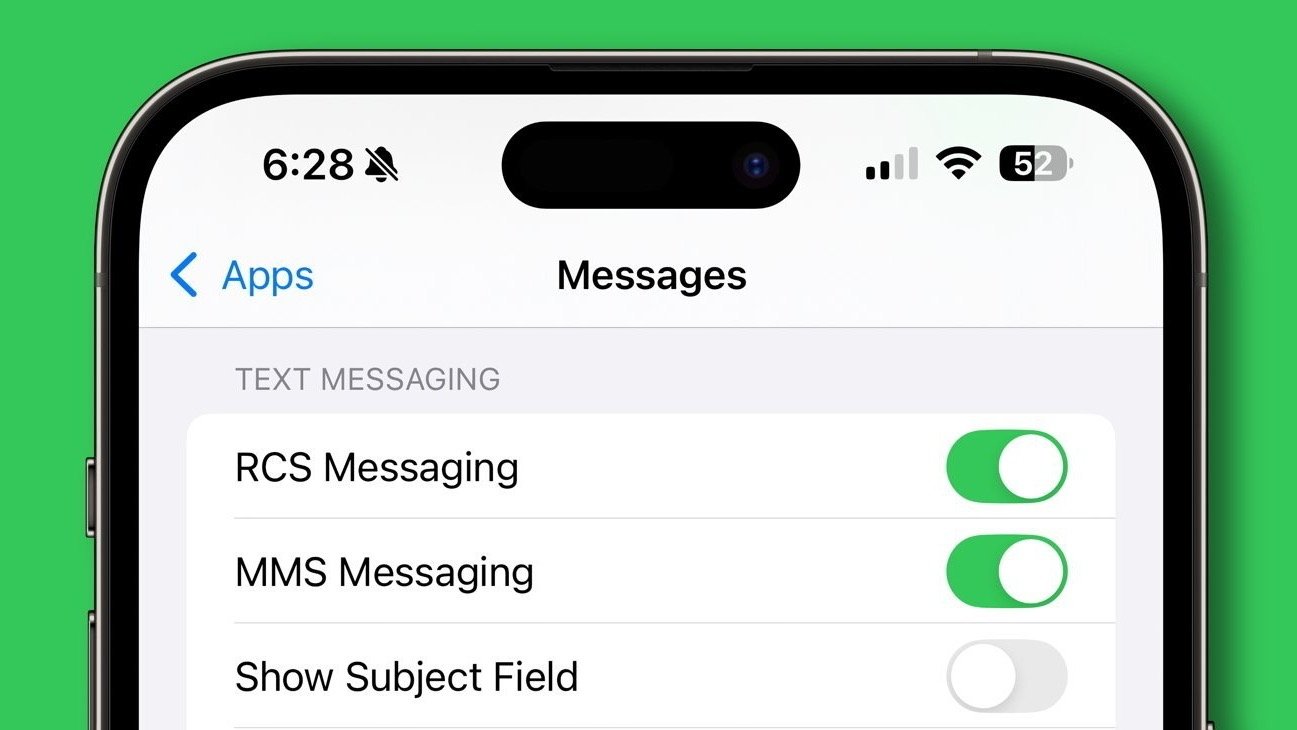

























![New iOS 19 Leak Allegedly Reveals Updated Icons, Floating Tab Bar, More [Video]](https://www.iclarified.com/images/news/96958/96958/96958-640.jpg)

![Apple to Source More iPhones From India to Offset China Tariff Costs [Report]](https://www.iclarified.com/images/news/96954/96954/96954-640.jpg)
![Blackmagic Design Unveils DaVinci Resolve 20 With Over 100 New Features and AI Tools [Video]](https://www.iclarified.com/images/news/96951/96951/96951-640.jpg)
























































































































Small models for the win!
Agents seem to be the talk of the town in recent times, but there's a silent gem that everyone forgets. Small models! This is probably the future of AI development in general. Small models are usually distilled from much larger models, thus, they are fine-tuned for specific purposes, making them compact, fast, and fairly accurate. What is distillation anyway? A sort of "teacher-student" approach where large models essentially train smaller ones, enabling the smaller model to achieve much better performance and take up fewer resources. A smaller 1-8 billion parameter model is not going to outpace something like GPT4o, but in niche use cases, it's good enough and can actually be fine-tuned to outperform those larger models in these niche tasks. You see, large language models are fed massive sets of training data, everything and the kitchen sink. When it needs to generate a response, the model needs to sift through this massive knowledge base, thus requiring vast amounts of computing power. You can think of this process as the larger model simply summarizing just the important information and then feeding it to the smaller model, thus the model has less data to sift through. Which ultimately reduces the models size, and makes it more efficient in terms of compute resources required to run the model. Tiny models that pack a punch Here's some of the models I use in production for various use cases running on a small GeForce GTX 1080 8GB VRAM box: nemotron-mini: It's fast and works pretty well with simple RAG data. I use it for tasks like tagging and categorization. PHI-3 Mini: Slightly more resource-intensive compared to nemotron-mini, but is really good at generation-type tasks like titles, summaries, descriptions, etc... mistral-nemo: With 12B parameters, it's one of the smaller models but gives you a bit more accuracy than PHI-3 or nemotron-mini. I am using this for some advanced generation and classification tasks. One up from this is "mistral-small", but it's just too slow on my GTX 1080. granite3.1-dense: It's similar to nemotron-mini, but with a tad bit more accuracy. I use it for similar RAG tasks, often to narrow larger prompts down to something more digestible for PHI-3. There's also the PHI-4 series now, which I didn't have much time to play with yet, they seem more or less similar to PHI-3 versions. More models can be found here: https://ollama.com/search

Agents seem to be the talk of the town in recent times, but there's a silent gem that everyone forgets. Small models!
This is probably the future of AI development in general. Small models are usually distilled from much larger models, thus, they are fine-tuned for specific purposes, making them compact, fast, and fairly accurate.
What is distillation anyway?
A sort of "teacher-student" approach where large models essentially train smaller ones, enabling the smaller model to achieve much better performance and take up fewer resources.
A smaller 1-8 billion parameter model is not going to outpace something like GPT4o, but in niche use cases, it's good enough and can actually be fine-tuned to outperform those larger models in these niche tasks.
You see, large language models are fed massive sets of training data, everything and the kitchen sink. When it needs to generate a response, the model needs to sift through this massive knowledge base, thus requiring vast amounts of computing power.
You can think of this process as the larger model simply summarizing just the important information and then feeding it to the smaller model, thus the model has less data to sift through. Which ultimately reduces the models size, and makes it more efficient in terms of compute resources required to run the model.
Tiny models that pack a punch
Here's some of the models I use in production for various use cases running on a small GeForce GTX 1080 8GB VRAM box:
- nemotron-mini: It's fast and works pretty well with simple RAG data. I use it for tasks like tagging and categorization.
- PHI-3 Mini: Slightly more resource-intensive compared to nemotron-mini, but is really good at generation-type tasks like titles, summaries, descriptions, etc...
- mistral-nemo: With 12B parameters, it's one of the smaller models but gives you a bit more accuracy than PHI-3 or nemotron-mini. I am using this for some advanced generation and classification tasks. One up from this is "mistral-small", but it's just too slow on my GTX 1080.
- granite3.1-dense: It's similar to nemotron-mini, but with a tad bit more accuracy. I use it for similar RAG tasks, often to narrow larger prompts down to something more digestible for PHI-3.
There's also the PHI-4 series now, which I didn't have much time to play with yet, they seem more or less similar to PHI-3 versions.
More models can be found here: https://ollama.com/search