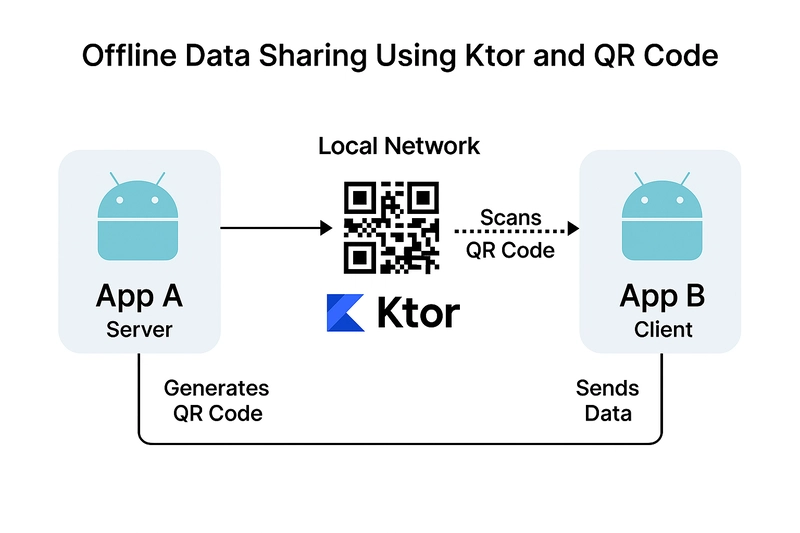














































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)










































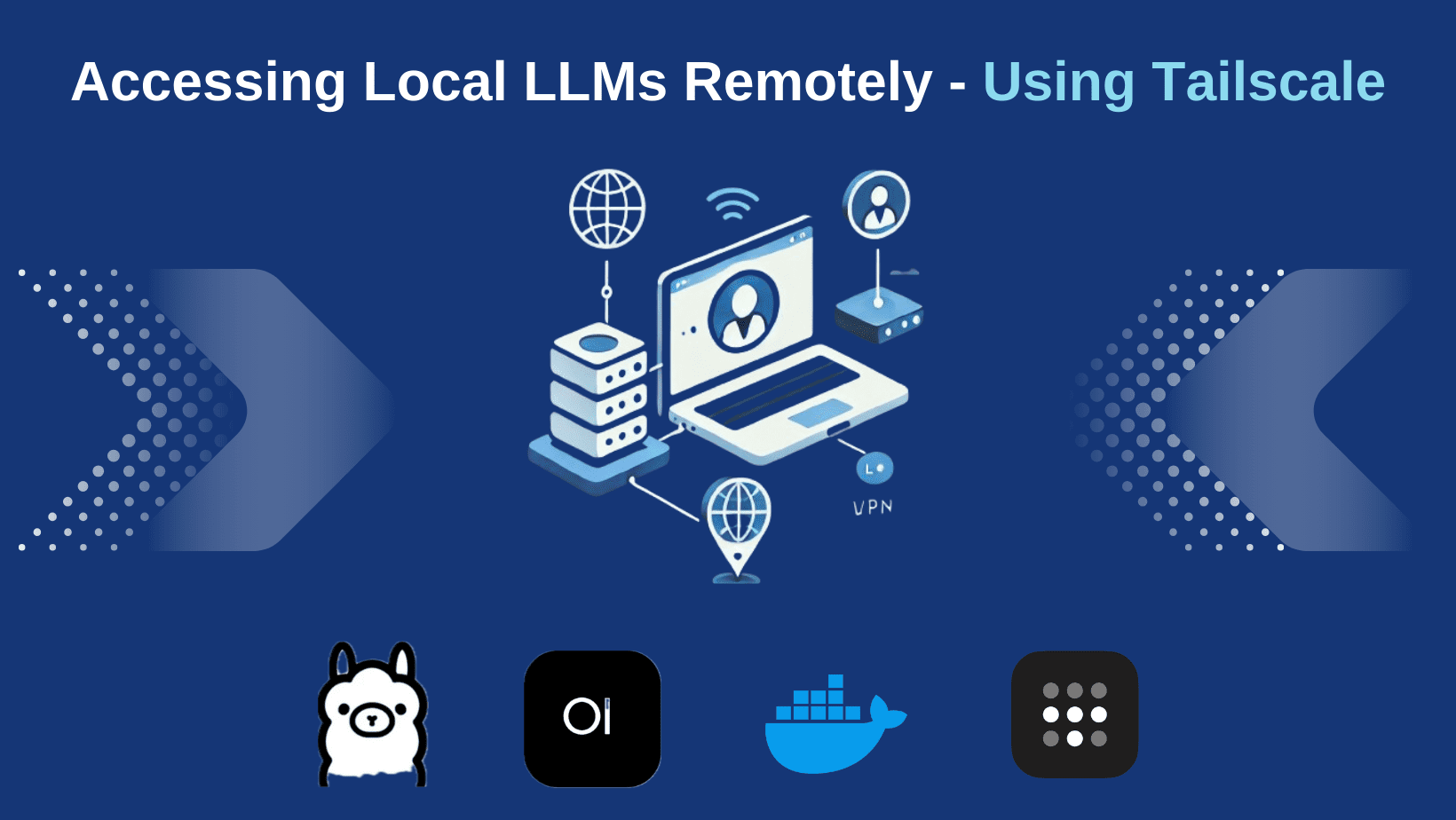





































































































































































































































.png?#)


















































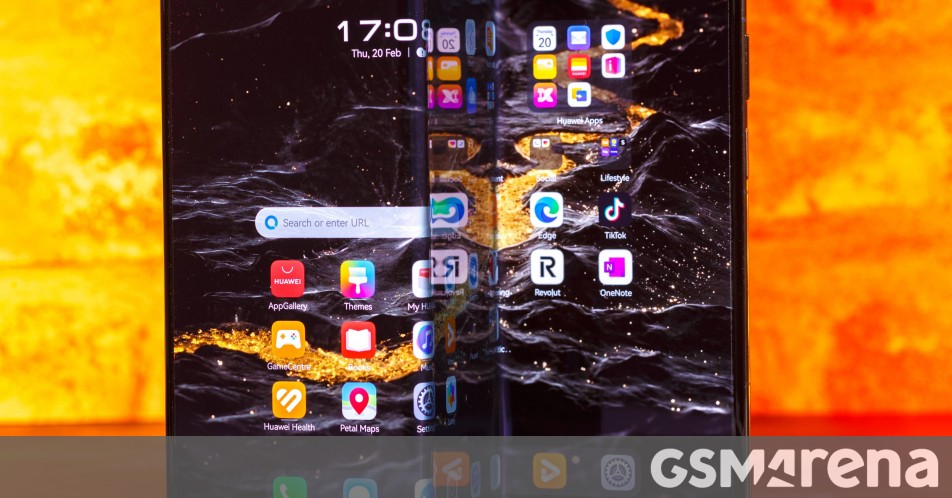
















































![Beats Studio Buds + On Sale for $99.95 [Lowest Price Ever]](https://www.iclarified.com/images/news/96983/96983/96983-640.jpg)
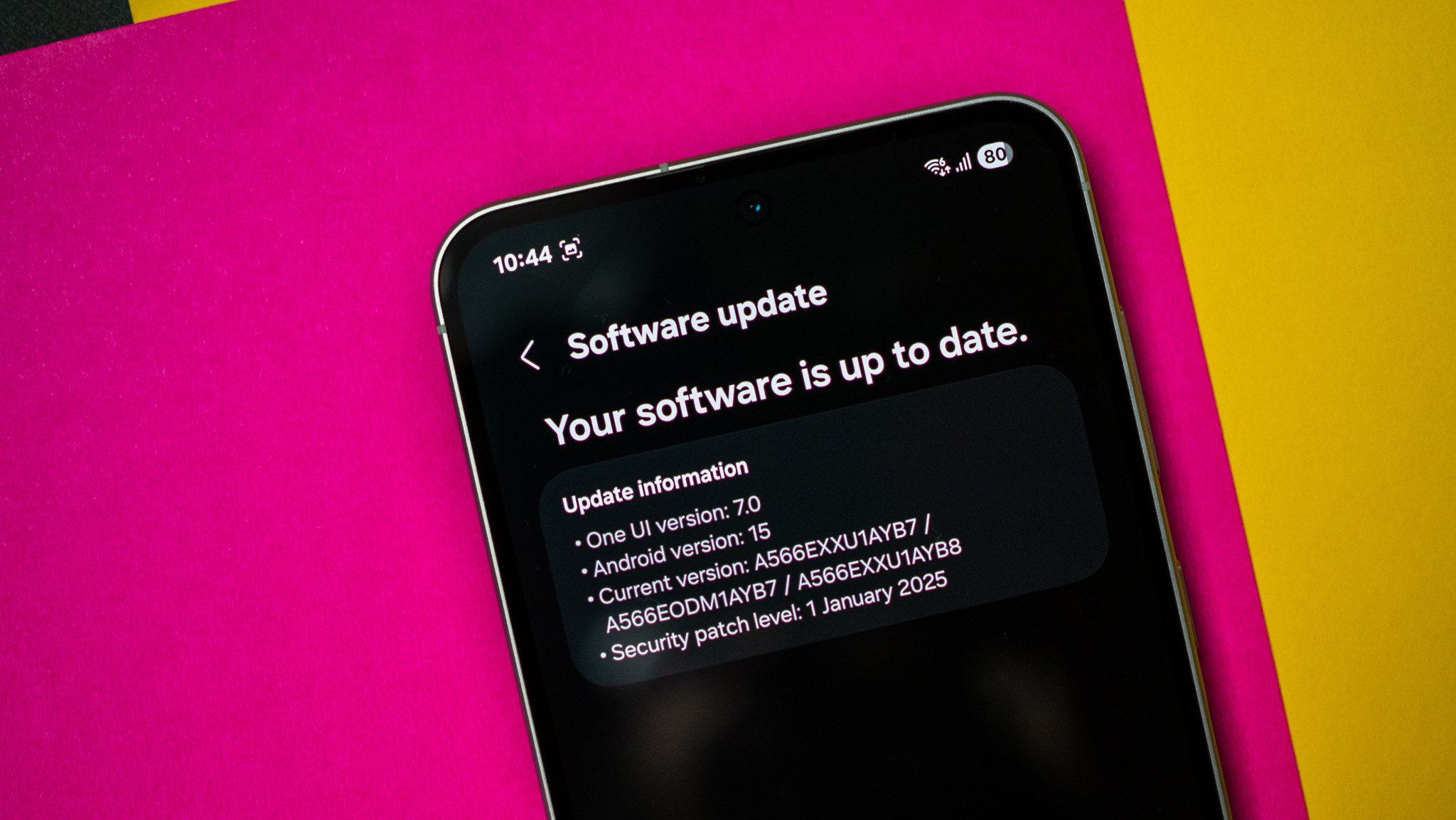
![Apple Watch to Get visionOS Inspired Refresh, Apple Intelligence Support [Rumor]](https://www.iclarified.com/images/news/96976/96976/96976-640.jpg)
























































































































Optimizing Your Web Crawling and Web Scraping Strategy
The internet is a goldmine of data, but getting to it requires the right tools and techniques. Enter web crawling and web scraping. Though they may sound similar, these two methods serve distinct purposes and require different approaches. Getting a solid grasp on their differences can make all the difference in how you collect and use data. Let’s dive into the key contrasts between these techniques, and see how they can work for you. What Are Web Crawling and Web Scraping Web Crawling: Think of a web crawler (or spider) as a digital explorer. It scours the internet, following links to discover and index web pages. This process is what powers search engines, helping them catalog the web’s massive content. Web Scraping: In contrast, web scraping is laser-focused. It pulls specific data from known pages. Whether it’s product details, pricing, or contact info, scraping extracts structured data from websites with precision. The Core Difference: Crawling is about finding and indexing, while scraping is about digging deep into specific data. Scope and Approach Web Crawling: Crawlers start with a seed URL and follow links from one page to the next, systematically mapping out websites. It’s a broad, sweeping approach aimed at covering as much ground as possible. Web Scraping: Scraping, however, targets specific pages or datasets. The process focuses on parsing the page’s HTML to extract relevant information, often using tools like BeautifulSoup or Scrapy. The Key Difference: Crawling is wide-reaching. Scraping is all about precision. Must-Have Tools Web Crawling: If you want to crawl a site, you’ll likely use tools like Scrapy, Apache Nutch, or Googlebot. These tools are built for large-scale data collection and site indexing. Web Scraping: For scraping, tools like BeautifulSoup or Selenium are your go-to. These are more focused on pulling structured data from specific pages. The Difference: Crawling tools are designed for discovery; scraping tools are engineered for extraction. Real-World Use Cases Web Crawling: Crawling is typically used by search engines like Google to index the web. It’s also handy for businesses that need to monitor website changes or researchers looking for large datasets. Web Scraping: Scraping shines in more specific tasks like price comparison, sentiment analysis, and lead generation. It’s perfect when you need to extract structured data for business intelligence. The Key Difference: Crawling is great for broad data collection. Scraping is ideal for focused, actionable insights. Legal and Ethical Guidelines Both techniques require a smart, responsible approach. Crawling: You’ll need to respect each site’s robots.txt file to ensure you’re not accessing restricted areas. Scraping: Scraping requires extra caution—ensure you respect copyright laws and avoid overwhelming servers with too many requests. The Difference: Crawling tends to involve publicly available data. Scraping, though, may need permissions for certain content. Key Differences at a Glance Web crawling and web scraping serve distinct purposes and operate on different scales. Web crawling is primarily used for indexing and discovering content across the web, with a broad scope that aims to index large sections of the internet. The output of web crawling typically includes sitemaps and indexes, which help in organizing and structuring the vast amount of information available online. On the other hand, web scraping focuses on extracting specific data from websites, working within a narrower scope. It generates structured data, often in formats like CSV or JSON, for more precise use cases. Both methods may use similar tools, such as Scrapy, but web crawling commonly relies on tools like Googlebot, while web scraping makes use of libraries like BeautifulSoup for more targeted data extraction. Conclusion Ultimately, the choice between web crawling and web scraping depends on your goals. Crawling is for broad indexing; scraping is for precise data extraction.
The internet is a goldmine of data, but getting to it requires the right tools and techniques. Enter web crawling and web scraping. Though they may sound similar, these two methods serve distinct purposes and require different approaches. Getting a solid grasp on their differences can make all the difference in how you collect and use data.
Let’s dive into the key contrasts between these techniques, and see how they can work for you.
What Are Web Crawling and Web Scraping
Web Crawling:
Think of a web crawler (or spider) as a digital explorer. It scours the internet, following links to discover and index web pages. This process is what powers search engines, helping them catalog the web’s massive content.
Web Scraping:
In contrast, web scraping is laser-focused. It pulls specific data from known pages. Whether it’s product details, pricing, or contact info, scraping extracts structured data from websites with precision.
The Core Difference:
Crawling is about finding and indexing, while scraping is about digging deep into specific data.
Scope and Approach
Web Crawling:
Crawlers start with a seed URL and follow links from one page to the next, systematically mapping out websites. It’s a broad, sweeping approach aimed at covering as much ground as possible.
Web Scraping:
Scraping, however, targets specific pages or datasets. The process focuses on parsing the page’s HTML to extract relevant information, often using tools like BeautifulSoup or Scrapy.
The Key Difference:
Crawling is wide-reaching. Scraping is all about precision.
Must-Have Tools
Web Crawling:
If you want to crawl a site, you’ll likely use tools like Scrapy, Apache Nutch, or Googlebot. These tools are built for large-scale data collection and site indexing.
Web Scraping:
For scraping, tools like BeautifulSoup or Selenium are your go-to. These are more focused on pulling structured data from specific pages.
The Difference:
Crawling tools are designed for discovery; scraping tools are engineered for extraction.
Real-World Use Cases
Web Crawling:
Crawling is typically used by search engines like Google to index the web. It’s also handy for businesses that need to monitor website changes or researchers looking for large datasets.
Web Scraping:
Scraping shines in more specific tasks like price comparison, sentiment analysis, and lead generation. It’s perfect when you need to extract structured data for business intelligence.
The Key Difference:
Crawling is great for broad data collection. Scraping is ideal for focused, actionable insights.
Legal and Ethical Guidelines
Both techniques require a smart, responsible approach.
Crawling:
You’ll need to respect each site’s robots.txt file to ensure you’re not accessing restricted areas.
Scraping:
Scraping requires extra caution—ensure you respect copyright laws and avoid overwhelming servers with too many requests.
The Difference:
Crawling tends to involve publicly available data. Scraping, though, may need permissions for certain content.
Key Differences at a Glance
Web crawling and web scraping serve distinct purposes and operate on different scales. Web crawling is primarily used for indexing and discovering content across the web, with a broad scope that aims to index large sections of the internet. The output of web crawling typically includes sitemaps and indexes, which help in organizing and structuring the vast amount of information available online.
On the other hand, web scraping focuses on extracting specific data from websites, working within a narrower scope. It generates structured data, often in formats like CSV or JSON, for more precise use cases. Both methods may use similar tools, such as Scrapy, but web crawling commonly relies on tools like Googlebot, while web scraping makes use of libraries like BeautifulSoup for more targeted data extraction.
Conclusion
Ultimately, the choice between web crawling and web scraping depends on your goals. Crawling is for broad indexing; scraping is for precise data extraction.