%20Abstract%20Background%20102024%20SOURCE%20Amazon.jpg)






















































































































![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)








































































































































































































































































_Alexey_Kotelnikov_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_Brian_Jackson_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)




























































































![Roku clarifies how ‘Pause Ads’ work amid issues with some HDR content [U]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/05/roku-pause-ad-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)














![Apple Seeds visionOS 2.5 RC to Developers [Download]](https://www.iclarified.com/images/news/97240/97240/97240-640.jpg)
![Apple Seeds tvOS 18.5 RC to Developers [Download]](https://www.iclarified.com/images/news/97243/97243/97243-640.jpg)



















































































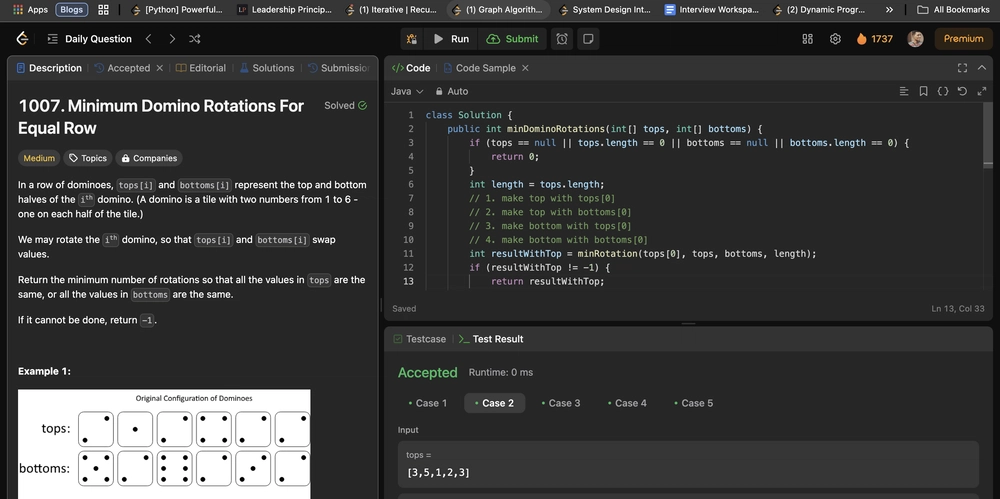
Mastering Go Concurrency Patterns: Pipelines, Broadcasting, and Cancellation
Go's concurrency primitives are one of its most powerful features, allowing developers to build efficient, scalable systems. The article from go.dev blog ("Go Concurrency Patterns: Pipelines and cancellation") provides excellent foundations, but I'd like to expand on these concepts with practical patterns for more complex real-world scenarios. Understanding Pipelines in Go A pipeline in Go is essentially a series of stages connected by channels, where each stage performs some processing on the data it receives and sends results to the next stage. The Go blog article describes this elegantly: Informally, a pipeline is a series of stages connected by channels, where each stage is a group of goroutines running the same function. Let's examine the key components of a pipeline: Stages: Each stage processes data and passes it downstream Channels: Connect stages, allowing data to flow through the pipeline Goroutines: Run the processing functions in each stage Basic Pipeline Pattern Here's a simple three-stage pipeline from the Go blog article: func gen(nums ...int)

Go's concurrency primitives are one of its most powerful features, allowing developers to build efficient, scalable systems. The article from go.dev blog ("Go Concurrency Patterns: Pipelines and cancellation") provides excellent foundations, but I'd like to expand on these concepts with practical patterns for more complex real-world scenarios.
Understanding Pipelines in Go
A pipeline in Go is essentially a series of stages connected by channels, where each stage performs some processing on the data it receives and sends results to the next stage. The Go blog article describes this elegantly:
Informally, a pipeline is a series of stages connected by channels, where each stage is a group of goroutines running the same function.
Let's examine the key components of a pipeline:
- Stages: Each stage processes data and passes it downstream
- Channels: Connect stages, allowing data to flow through the pipeline
- Goroutines: Run the processing functions in each stage
Basic Pipeline Pattern
Here's a simple three-stage pipeline from the Go blog article:
func gen(nums ...int) <-chan int {
out := make(chan int)
go func() {
for _, n := range nums {
out <- n
}
close(out)
}()
return out
}
func sq(in <-chan int) <-chan int {
out := make(chan int)
go func() {
for n := range in {
out <- n * n
}
close(out)
}()
return out
}
func main() {
// Set up the pipeline: gen -> sq -> sq
for n := range sq(sq(gen(2, 3))) {
fmt.Println(n) // 16 then 81
}
}
This showcases the basic pattern: each stage takes an input channel, processes the data, and returns an output channel.
Fan-Out, Fan-In Pattern
For more complex scenarios where we need to parallelize work across multiple goroutines, we can use the fan-out, fan-in pattern:
func merge(done <-chan struct{}, cs ...<-chan int) <-chan int {
var wg sync.WaitGroup
out := make(chan int)
// Function to copy values from one channel to another
output := func(c <-chan int) {
defer wg.Done()
for n := range c {
select {
case out <- n:
case <-done:
return
}
}
}
wg.Add(len(cs))
for _, c := range cs {
go output(c)
}
// Close the output channel when all input channels are done
go func() {
wg.Wait()
close(out)
}()
return out
}
func main() {
done := make(chan struct{})
defer close(done)
in := gen(done, 2, 3)
// Fan out work to two instances of sq
c1 := sq(done, in)
c2 := sq(done, in)
// Fan in the results
for n := range merge(done, c1, c2) {
fmt.Println(n)
}
}
This pattern allows us to distribute work across multiple goroutines (fan-out) and then combine their results into a single channel (fan-in).
Explicit Cancellation with Context
The context package provides a more sophisticated way to handle cancellation. It allows for cancellation signals to propagate throughout a call graph, ensuring all goroutines can clean up and exit when their work is no longer needed.
Here's how we could adapt our pipeline to use context:
func processRequest(ctx context.Context, request string) (string, error) {
// Create a stage that processes the request
processCh := make(chan string, 1)
go func() {
// Simulate processing time
time.Sleep(200 * time.Millisecond)
select {
case processCh <- "Processed: " + request:
case <-ctx.Done():
return
}
}()
// Wait for either processing to complete or context to be canceled
select {
case result := <-processCh:
return result, nil
case <-ctx.Done():
return "", ctx.Err()
}
}
func main() {
// Create a context with a timeout
ctx, cancel := context.WithTimeout(context.Background(), 300*time.Millisecond)
defer cancel()
result, err := processRequest(ctx, "important data")
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Println("Result:", result)
}
Bounded Parallelism with Worker Pools
In real-world applications, we often need to limit the number of goroutines running simultaneously to avoid exhausting system resources. The "bounded.go" example from the Go blog demonstrates this pattern beautifully:
// Start a fixed number of workers
const numWorkers = 20
// Process files with bounded parallelism
func processFiles(ctx context.Context, files []string) (map[string]Result, error) {
// Channel for file paths
paths := make(chan string)
// Channel for results
results := make(chan Result)
// Start file producer
go func() {
defer close(paths)
for _, file := range files {
select {
case paths <- file:
case <-ctx.Done():
return
}
}
}()
// Start worker pool
var wg sync.WaitGroup
wg.Add(numWorkers)
for i := 0; i < numWorkers; i++ {
go func() {
defer wg.Done()
for path := range paths {
result, err := processFile(ctx, path)
if err != nil {
select {
case results <- Result{path: path, err: err}:
case <-ctx.Done():
return
}
continue
}
select {
case results <- Result{path: path, data: result}:
case <-ctx.Done():
return
}
}
}()
}
// Close results channel when all workers are done
go func() {
wg.Wait()
close(results)
}()
// Collect results
output := make(map[string]Result)
for r := range results {
output[r.path] = r
}
// Check for context cancellation
if ctx.Err() != nil {
return nil, ctx.Err()
}
return output, nil
}
This pattern is particularly useful in scenarios like:
- Processing large batches of data
- Handling many concurrent network requests
- Performing file operations with controlled parallelism
Combining with errgroup for Error Handling
The errgroup package (from golang.org/x/sync/errgroup) provides a clean way to handle errors from multiple goroutines. It's perfect for pipelines where we want to propagate errors properly:
func fetchAndProcess(urls []string) ([]Result, error) {
g, ctx := errgroup.WithContext(context.Background())
// Create a channel for the fetched data
fetchedData := make(chan Data, len(urls))
// Stage 1: Fetch data from URLs
for _, url := range urls {
url := url // Capture for closure
g.Go(func() error {
data, err := fetch(ctx, url)
if err != nil {
return err
}
select {
case fetchedData <- data:
return nil
case <-ctx.Done():
return ctx.Err()
}
})
}
// Close fetchedData when all fetches are done
go func() {
g.Wait()
close(fetchedData)
}()
// Stage 2: Process the fetched data
processedData := make(chan Result, len(urls))
g.Go(func() error {
for data := range fetchedData {
select {
case <-ctx.Done():
return ctx.Err()
default:
result, err := process(ctx, data)
if err != nil {
return err
}
select {
case processedData <- result:
case <-ctx.Done():
return ctx.Err()
}
}
}
close(processedData)
return nil
})
// Collect results
var results []Result
for result := range processedData {
results = append(results, result)
}
// Wait for all goroutines to complete and check for errors
if err := g.Wait(); err != nil {
return nil, err
}
return results, nil
}
Beyond Simple Pipelines: Building Broadcast Systems
For more complex applications, we might need to implement broadcasting mechanisms where one goroutine needs to notify multiple goroutines about an event. We can use the close channel idiom for this:
func broadcaster(messages <-chan string) (chan<- struct{}, <-chan string) {
// Subscribers will receive on copies of the broadcast channel
broadcast := make(chan string)
// Done channel for signaling shutdown
done := make(chan struct{})
go func() {
defer close(broadcast)
// Keep track of subscribers
subscribers := make(map[chan<- string]bool)
// Helper to send to all subscribers
sendToAll := func(msg string) {
for sub := range subscribers {
select {
case sub <- msg:
case <-done:
return
}
}
}
// Channel for adding new subscribers
newSubscribers := make(chan chan<- string)
// Handle subscription requests in a separate goroutine
go func() {
for {
select {
case sub := <-newSubscribers:
subscribers[sub] = true
case <-done:
return
}
}
}()
// Main loop
for {
select {
case msg, ok := <-messages:
if !ok {
return
}
sendToAll(msg)
case <-done:
return
}
}
}()
return done, broadcast
}
Avoiding Memory Leaks with goleak
When working with goroutines and channels, it's easy to introduce memory leaks by forgetting to properly clean up goroutines. The goleak package from Uber can help detect these issues:
func TestPipeline(t *testing.T) {
defer goleak.VerifyNone(t)
// Test your pipeline here...
}
This ensures all goroutines are properly terminated after the test, helping catch potential memory leaks early.
Best Practices for Go Concurrency Patterns
Based on these examples and the Go blog articles, here are some best practices:
Always use cancellation mechanisms - Every goroutine should have a way to be notified when its work is no longer needed.
Close channels from the sender side - The sender knows when all data has been sent, so it should be responsible for closing the channel.
Use buffered channels when appropriate - Buffered channels can help avoid blocking in specific scenarios, but use them judiciously.
Bound your concurrency - Limit the number of concurrent goroutines to avoid resource exhaustion.
Propagate errors properly - Use patterns like
errgroupto handle errors from multiple goroutines.Test for goroutine leaks - Use tools like
goleakto ensure all goroutines are properly terminated.Use context for cancellation - The
contextpackage provides a standardized way to handle cancellation across API boundaries.
Conclusion
Go's concurrency primitives are simple but powerful building blocks that can be composed to create elegant solutions to complex problems. By understanding patterns like pipelines, fan-out/fan-in, context cancellation, and bounded parallelism, you can write Go code that is both efficient and maintainable.
Remember that concurrency is a tool to solve specific problems, not a goal in itself. Always start simple and add concurrency only where it provides clear benefits in terms of performance or code organization.