








































































































































































![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)














































































































































































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)
























































































_Alexey_Kotelnikov_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_Brian_Jackson_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)



 Stolen 884,000 Credit Card Details on 13 Million Clicks from Users Worldwide.webp?#)




















































































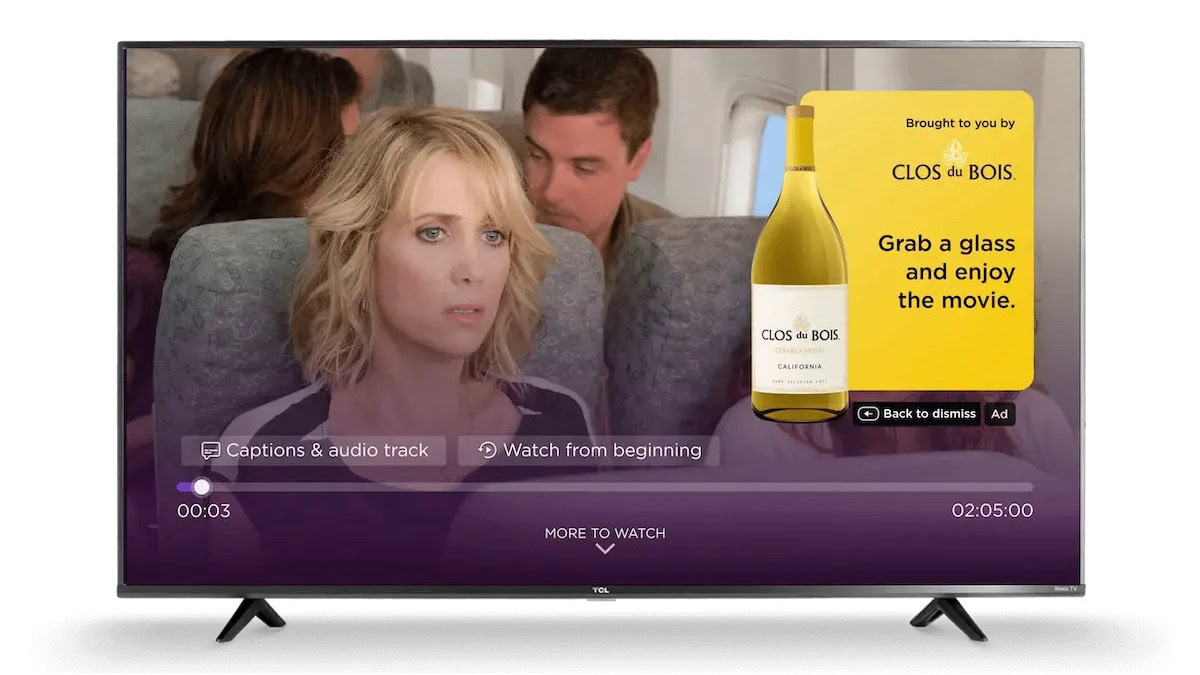
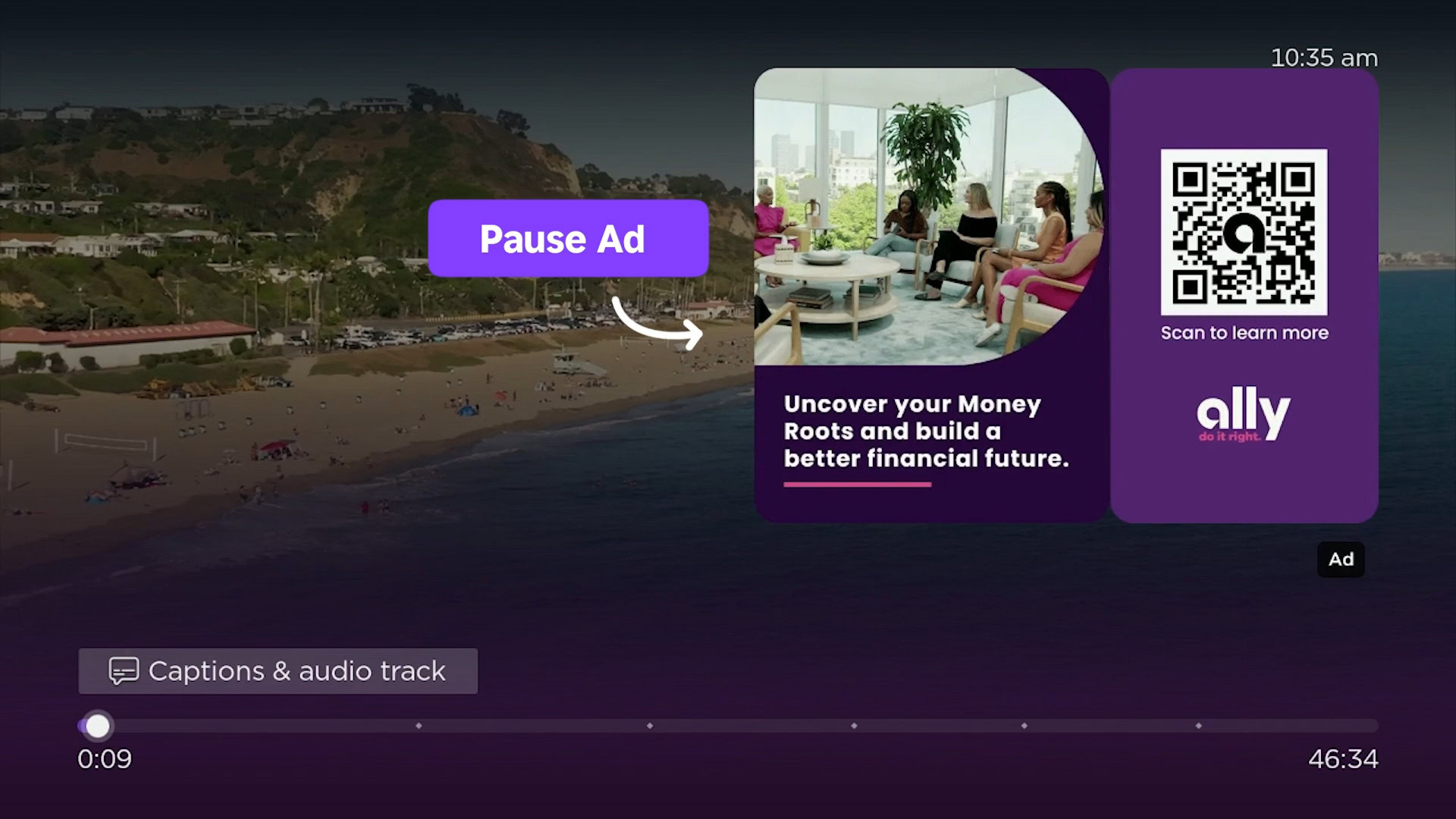




![Roku clarifies how ‘Pause Ads’ work amid issues with some HDR content [U]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/05/roku-pause-ad-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)










![Apple Seeds visionOS 2.5 RC to Developers [Download]](https://www.iclarified.com/images/news/97240/97240/97240-640.jpg)
![Apple Seeds tvOS 18.5 RC to Developers [Download]](https://www.iclarified.com/images/news/97243/97243/97243-640.jpg)

























































































The Rise of Mixture-of-Experts: How Sparse AI Models Are Shaping the Future of Machine Learning
Mixture-of-Experts (MoE) models are revolutionizing the way we scale AI. By activating only a subset of a model’s components at any given time, MoEs offer a novel approach to managing the trade-off between model size and computational efficiency. Unlike traditional dense models that use all parameters for every input, MoEs achieve enormous parameter counts while […] The post The Rise of Mixture-of-Experts: How Sparse AI Models Are Shaping the Future of Machine Learning appeared first on Unite.AI.


Mixture-of-Experts (MoE) models are revolutionizing the way we scale AI. By activating only a subset of a model’s components at any given time, MoEs offer a novel approach to managing the trade-off between model size and computational efficiency. Unlike traditional dense models that use all parameters for every input, MoEs achieve enormous parameter counts while keeping inference and training costs manageable. This breakthrough has fueled a wave of research and development, leading both tech giants and startups to invest heavily in MoE-based architectures.
How Mixture-of-Experts Models Work
At their core, MoE models consist of multiple specialized sub-networks called “experts,” overseen by a gating mechanism that decides which experts should handle each input. For example, a sentence passed into a language model may only engage two out of eight experts, drastically reducing the computational workload.
This concept was brought into the mainstream with Google's Switch Transformer and GLaM models, where experts replaced traditional feed-forward layers in Transformers. Switch Transformer, for instance, routes tokens to a single expert per layer, while GLaM uses top-2 routing for improved performance. These designs demonstrated that MoEs could match or outperform dense models like GPT-3 while using significantly less energy and compute.
The key innovation lies in conditional computation. Instead of firing up the entire model, MoEs activate only the most relevant parts, which means that a model with hundreds of billions or even trillions of parameters can run with the efficiency of one that is orders of magnitude smaller. This enables researchers to scale capacity without linear increases in computation, a feat unattainable with traditional scaling methods.
Real-World Applications of MoE
MoE models have already made their mark across several domains. Google’s GLaM and Switch Transformer showed state-of-the-art results in language modeling with lower training and inference costs. Microsoft’s Z-Code MoE is operational in its Translator tool, handling over 100 languages with better accuracy and efficiency than earlier models. These are not just research projects—they are powering live services.
In computer vision, Google’s V-MoE architecture has improved classification accuracy on benchmarks like ImageNet, and the LIMoE model has demonstrated strong performance in multimodal tasks involving both images and text. The ability of experts to specialize—some handling text, others images—adds a new layer of capability to AI systems.
Recommender systems and multi-task learning platforms have also benefited from MoEs. For instance, YouTube’s recommendation engine has employed a MoE-like architecture to handle objectives like watch time and click-through rate more efficiently. By assigning different experts to different tasks or user behaviors, MoEs help build more robust personalization engines.
Benefits and Challenges
The main advantage of MoEs is efficiency. They allow massive models to be trained and deployed with significantly less compute. For instance, Mistral AI’s Mixtral 8×7B model has 47B total parameters but only activates 12.9B per token, giving it the cost-efficiency of a 13B model while competing with models like GPT-3.5 in quality.
MoEs also foster specialization. Because different experts can learn distinct patterns, the overall model becomes better at handling diverse inputs. This is particularly useful in multilingual, multi-domain, or multimodal tasks where a one-size-fits-all dense model may underperform.
However, MoEs come with engineering challenges. Training them requires careful balancing to ensure that all experts are used effectively. Memory overhead is another concern—while only a fraction of parameters are active per inference, all must be loaded into memory. Efficiently distributing computation across GPUs or TPUs is non-trivial and has led to the development of specialized frameworks like Microsoft’s DeepSpeed and Google’s GShard.
Despite these hurdles, the performance and cost benefits are substantial enough that MoEs are now seen as a critical component of large-scale AI design. As more tools and infrastructure mature, these challenges are gradually being overcome.
How MoE Compares to Other Scaling Methods
Traditional dense scaling increases model size and compute proportionally. MoEs break this linearity by increasing total parameters without increasing compute per input. This enables models with trillions of parameters to be trained on the same hardware previously limited to tens of billions.
Compared to model ensembling, which also introduces specialization but requires multiple full forward passes, MoEs are far more efficient. Instead of running several models in parallel, MoEs run just one—but with the benefit of multiple expert pathways.
MoEs also complement strategies like scaling training data (e.g., the Chinchilla method). While Chinchilla emphasizes using more data with smaller models, MoEs expand model capacity while keeping compute stable, making them ideal for cases where compute is the bottleneck.
Finally, while techniques like pruning and quantization shrink models post-training, MoEs increase model capacity during training. They are not a replacement for compression but an orthogonal tool for efficient growth.
The Companies Leading the MoE Revolution
Tech Giants
Google pioneered much of today’s MoE research. Their Switch Transformer and GLaM models scaled to 1.6T and 1.2T parameters respectively. GLaM matched GPT-3 performance while using just a third of the energy. Google has also applied MoEs to vision (V-MoE) and multimodal tasks (LIMoE), aligning with their broader Pathways vision for universal AI models.
Microsoft has integrated MoE into production through its Z-Code model in Microsoft Translator. It also developed DeepSpeed-MoE, enabling fast training and low-latency inference for trillion-parameter models. Their contributions include routing algorithms and the Tutel library for efficient MoE computation.
Meta explored MoEs in large-scale language models and recommender systems. Their 1.1T MoE model showed that it could match dense model quality using 4× less compute. While LLaMA models are dense, Meta’s research into MoE continues to inform the broader community.
Amazon supports MoEs through its SageMaker platform and internal efforts. They facilitated the training of Mistral’s Mixtral model and are rumored to be using MoEs in services like Alexa AI. AWS documentation actively promotes MoEs for large-scale model training.
Huawei and BAAI in China have also developed record-breaking MoE models like PanGu-Σ (1.085T params). This showcases MoE's potential in language and multimodal tasks and highlights its global appeal.
Startups and Challengers
Mistral AI is the poster child for MoE innovation in open-source. Their Mixtral 8×7B and 8×22B models have proven that MoEs can outperform dense models like LLaMA-2 70B while running at a fraction of the cost. With over €600M in funding, Mistral is betting big on sparse architectures.
xAI, founded by Elon Musk, is reportedly exploring MoEs in their Grok model. While details are limited, MoEs offer a way for startups like xAI to compete with larger players without needing massive compute.
Databricks, via its MosaicML acquisition, has released DBRX, an open MoE model designed for efficiency. They also provide infrastructure and recipes for MoE training, lowering the barrier for adoption.
Other players like Hugging Face have integrated MoE support into their libraries, making it easier for developers to build on these models. Even if not building MoEs themselves, platforms that enable them are crucial to the ecosystem.
Conclusion
Mixture-of-Experts models are not just a trend—they represent a fundamental shift in how AI systems are built and scaled. By selectively activating only parts of a network, MoEs offer the power of massive models without their prohibitive cost. As software infrastructure catches up and routing algorithms improve, MoEs are poised to become the default architecture for multi-domain, multilingual, and multimodal AI.
Whether you’re a researcher, engineer, or investor, MoEs offer a glimpse into a future where AI is more powerful, efficient, and adaptable than ever before.
The post The Rise of Mixture-of-Experts: How Sparse AI Models Are Shaping the Future of Machine Learning appeared first on Unite.AI.

