












































































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)







































































































































































































































.png?#)









.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)




























.webp?#)

















































































![Leaker vaguely comments on under-screen camera in iPhone Fold [U]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/04/iPhone-Fold-will-have-Face-ID-embedded-in-the-display-%E2%80%93-leaker.webp?resize=1200%2C628&quality=82&strip=all&ssl=1)




![[Fixed] Gemini app is failing to generate Audio Overviews](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/03/Gemini-Audio-Overview-cover.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)














![Apple Seeds tvOS 18.5 Beta 2 to Developers [Download]](https://www.iclarified.com/images/news/97011/97011/97011-640.jpg)
![Apple Releases macOS Sequoia 15.5 Beta 2 to Developers [Download]](https://www.iclarified.com/images/news/97014/97014/97014-640.jpg)



















































































































lições aprendidas na construção de uma sdk financeira: onde termina o backend e começa o cliente?
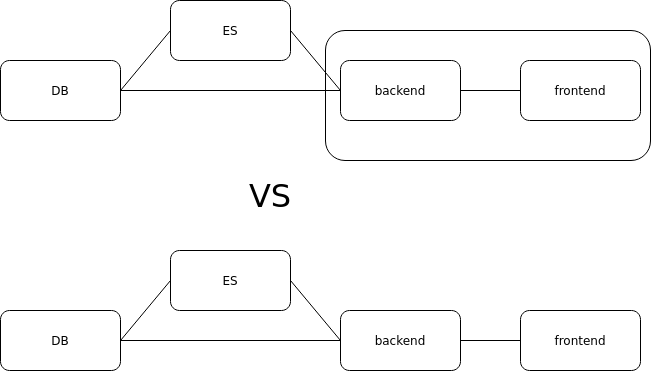
nas últimas semanas, embarcamos em um desafio por aqui: construir a primeira SDK para o Midaz, nosso ledger para core banking (disponível open-source aqui). o que parecia ser um projeto de simples -- afinal, openapi documentation e uma infinidade de ferramentas para generation --, rapidamente se transformou em um rabbit hole técnico bem profundo. colocar a primeira versão em produção trouxe à tona uma discussão fundamental: qual é a fronteira entre as responsabilidades do servidor e do cliente? fronteiras de responsabilidade quando começamos a desenvolver a SDK para o Midaz (em Go), a pergunta que constantemente nos perseguia era: até onde a API do backend deve ir e onde começa a responsabilidade de integração/implementação do cliente? ou seja, onde termina o backend e começa o colo do cliente? esta pergunta aparentemente simples esconde uma complexidade enorme. tradicionalmente, muitos desenvolvedores consideram que: Backend: responsável pela lógica de negócio, persistência, segurança, validações Cliente/SDK: responsável apenas por fazer requisições HTTP, serializar/deserializar dados mas será que essa divisão simplista funciona bem na prática? especialmente quando falamos de sistemas financeiros com requisitos rigorosos de consistência, performance e resiliência? por que uma SDK robusta importa? ou pq qualquer generation tool não funcionou conosco durante o desenvolvimento, percebemos que uma SDK financeira precisa ir muito além de simplesmente fazer o wrapping de endpoints REST. ela precisa ser uma camada que: Protege o servidor contra inputs inválidos (validação do lado cliente) Torna a integração mais resiliente (retries, rate limiting, circuit breaking) Oferece performance mesmo em condições adversas (batching, paralelismo) Simplifica operações complexas (abstraindo detalhes de implementação [que o backend precisa manter detalhado]) Proporciona uma experiência de desenvolvimento fluida (tipos fortemente definidos, erros descritivos) vamos explorar cada um desses aspectos detalhadamente, com exemplos práticos do que implementamos na nossa primeira SDK. validação no cliente: evitando viagens desnecessárias uma das primeiras decisões que tomamos foi implementar validações robustas no lado cliente. por quê? simples: por que enviar ao servidor uma requisição que sabemos que vai falhar? // Exemplo de validação de transação financeira no lado cliente func ValidateTransactionDSL(input TransactionDSLValidator) error { if input == nil { return fmt.Errorf("transaction input cannot be nil") } // Valida código do ativo asset := input.GetAsset() if asset == "" { return fmt.Errorf("asset code is required") } if !assetCodePattern.MatchString(asset) { return fmt.Errorf("invalid asset code format: %s (must be 3-4 uppercase letters)", asset) } // Valida valor if input.GetValue()

nas últimas semanas, embarcamos em um desafio por aqui: construir a primeira SDK para o Midaz, nosso ledger para core banking (disponível open-source aqui). o que parecia ser um projeto de simples -- afinal, openapi documentation e uma infinidade de ferramentas para generation --, rapidamente se transformou em um rabbit hole técnico bem profundo. colocar a primeira versão em produção trouxe à tona uma discussão fundamental: qual é a fronteira entre as responsabilidades do servidor e do cliente?
fronteiras de responsabilidade
quando começamos a desenvolver a SDK para o Midaz (em Go), a pergunta que constantemente nos perseguia era: até onde a API do backend deve ir e onde começa a responsabilidade de integração/implementação do cliente? ou seja, onde termina o backend e começa o colo do cliente?
esta pergunta aparentemente simples esconde uma complexidade enorme. tradicionalmente, muitos desenvolvedores consideram que:
- Backend: responsável pela lógica de negócio, persistência, segurança, validações
- Cliente/SDK: responsável apenas por fazer requisições HTTP, serializar/deserializar dados
mas será que essa divisão simplista funciona bem na prática? especialmente quando falamos de sistemas financeiros com requisitos rigorosos de consistência, performance e resiliência?
por que uma SDK robusta importa? ou pq qualquer generation tool não funcionou conosco
durante o desenvolvimento, percebemos que uma SDK financeira precisa ir muito além de simplesmente fazer o wrapping de endpoints REST. ela precisa ser uma camada que:
- Protege o servidor contra inputs inválidos (validação do lado cliente)
- Torna a integração mais resiliente (retries, rate limiting, circuit breaking)
- Oferece performance mesmo em condições adversas (batching, paralelismo)
- Simplifica operações complexas (abstraindo detalhes de implementação [que o backend precisa manter detalhado])
- Proporciona uma experiência de desenvolvimento fluida (tipos fortemente definidos, erros descritivos)
vamos explorar cada um desses aspectos detalhadamente, com exemplos práticos do que implementamos na nossa primeira SDK.
validação no cliente: evitando viagens desnecessárias
uma das primeiras decisões que tomamos foi implementar validações robustas no lado cliente. por quê? simples: por que enviar ao servidor uma requisição que sabemos que vai falhar?
// Exemplo de validação de transação financeira no lado cliente
func ValidateTransactionDSL(input TransactionDSLValidator) error {
if input == nil {
return fmt.Errorf("transaction input cannot be nil")
}
// Valida código do ativo
asset := input.GetAsset()
if asset == "" {
return fmt.Errorf("asset code is required")
}
if !assetCodePattern.MatchString(asset) {
return fmt.Errorf("invalid asset code format: %s (must be 3-4 uppercase letters)", asset)
}
// Valida valor
if input.GetValue() <= 0 {
return fmt.Errorf("transaction amount must be greater than zero")
}
// Validações adicionais de contas e consistência...
}
implementamos validações para:
- formatos de código de ativos (USD, BRL, BTC, Gado, Caixas de Remédio, whatever)
- montantes e escalas de transações
- estrutura de contas e operações
- metadados e payloads auxiliares
isso traz múltiplos benefícios:
- feedback instantâneo para o desenvolvedor
- redução de latência (evitando roundtrips desnecessários)
- menor carga no servidor
- mensagens de erro mais contextualizadas e úteis
a validação no cliente não substitui a validação no servidor (que continua essencial por razões de segurança), mas cria uma experiência de desenvolvimento superior e reduz o tráfego de rede.
resiliência através de retry intelligente
sistemas distribuídos falham. esta é uma realidade, não uma possibilidade. quando trabalhamos com operações financeiras, essas falhas são ainda mais críticas e podem ter consequências significativas.
por isso, implementamos mecanismos sofisticados de retry com exponential backoff:
// Configuração de retry com backoff exponencial
client, err := client.New(
client.WithAuthToken("your-auth-token"),
client.WithTimeout(30 * time.Second),
client.WithRetries(3, 100*time.Millisecond, 1*time.Second),
client.UseAllAPIs(), // by the way, isso é um caso a parte aqui: pra que expor o que não precisa ser exposto?
)
nosso sistema de retry:
- utiliza backoff exponencial para evitar sobrecarregar servidores em problemas
- adiciona jitter (variação aleatória) para prevenir thundering herd e, sinceramente se eu fingir normalidade escrevendo isso aqui, é mentira. aqui foi um rabbit hole a parte, e estudamos bastante para entender o conceito que era aplicado em outras enterprise-grade APIs
- categoriza erros entre "retryable" e "non-retryable"
- respeita limites de timeout especificados pelo usuário
- permite personalização completa de estratégias
este código parece simples na interface, mas por trás dele há uma implementação robusta que considera diversos cenários de falha:
// Trecho da implementação de retry com backoff
func doWithOptions(ctx context.Context, fn func() error, options *Options) error {
var err error
for attempt := 0; attempt <= options.MaxRetries; attempt++ {
// Check if context is done before executing
if ctx.Err() != nil {
return fmt.Errorf("operation cancelled: %w", ctx.Err())
}
// Execute the function
err = fn()
if err == nil {
// Success, return immediately
return nil
}
// Check if this is the last attempt
if attempt == options.MaxRetries {
break
}
// Check if the error is retryable
if !IsRetryableError(err, options) {
return err
}
// Calculate delay with jitter
delay := calculateBackoff(attempt, options)
delayWithJitter := addJitter(delay, options.JitterFactor)
// Wait for the calculated delay or until context is done
timer := time.NewTimer(delayWithJitter)
select {
case <-ctx.Done():
timer.Stop()
return fmt.Errorf("operation cancelled during retry: %w", ctx.Err())
case <-timer.C:
// Continue to next retry attempt
}
}
return fmt.Errorf("operation failed after %d retries: %w", options.MaxRetries, err)
}
um dos aprendizados mais interessantes foi identificar quais erros deveriam ser tentados novamente e quais não. por exemplo, erros de validação nunca devem ter retry, enquanto problemas de rede temporários são candidatos ideais. esse modelo de listing by exception é um conceito que foi estudado bastante, e foi aplicado em outras enterprise-grade APIs (exemplo interessante é a da AWS).
// Definição de erros retryable padrão
var DefaultRetryableErrors = []string{
"connection reset by peer",
"connection refused",
"timeout",
"deadline exceeded",
"too many requests",
"rate limit",
"service unavailable",
}
// Códigos HTTP que merecem retry
var DefaultRetryableHTTPCodes = []int{
http.StatusRequestTimeout, // 408
http.StatusTooManyRequests, // 429
http.StatusInternalServerError, // 500
http.StatusBadGateway, // 502
http.StatusServiceUnavailable, // 503
http.StatusGatewayTimeout, // 504
}
gerenciamento avançado de configurações
a modularidade da configuração foi um ponto crítico do design. utilizamos o padrão de opções funcionais (não são 100% fluentes como pede o figurin) para permitir uma configuração limpa e extensível:
// Padrão de options funcionais para configuração flexível
client, err := client.New(
// Configurações básicas
client.WithAuthToken("your-auth-token"),
client.WithEnvironment(config.EnvironmentProduction),
// Opções avançadas de performance
client.WithTimeout(30 * time.Second),
client.WithRetries(3, 200*time.Millisecond, 2*time.Second),
// Observabilidade
client.WithObservability(true, true, true),
// Quais APIs utilizar
client.UseAllAPIs(),
)
este padrão permite:
- configuração incremental com defaults sensatos
- melhor legibilidade e manutenção
- extensibilidade futura sem quebrar compatibilidade
- configurações específicas por domínio
além disso, implementamos suporte para configuração via variáveis de ambiente:
// Variáveis de ambiente que o cliente reconhece
MIDAZ_AUTH_TOKEN=seu-token // implementaremos a sdk de access management lançada ontem logo logo
MIDAZ_ENVIRONMENT=production
MIDAZ_ONBOARDING_URL=https://api.exemplo.com/v1
MIDAZ_TRANSACTION_URL=https://transactions.exemplo.com/v1
MIDAZ_DEBUG=true
MIDAZ_MAX_RETRIES=5
isto permite uma integração mais suave com diferentes ambientes de deploy, especialmente em contextos de containers e kubernetes.
performance otimizada para JSON
em sistemas financeiros, performance não é luxo, é requisito. um dos pontos de maior otimização foi o processamento JSON, que pode rapidamente se tornar um gargalo:
// Exemplo de nossa implementação de pooling de buffers para JSON
type JSONPerformance struct {
encoderPool sync.Pool
decoderPool sync.Pool
bufferPool sync.Pool
}
func NewJSONPerformance() *JSONPerformance {
return &JSONPerformance{
encoderPool: sync.Pool{
New: func() interface{} {
return json.NewEncoder(io.Discard)
},
},
decoderPool: sync.Pool{
New: func() interface{} {
return json.NewDecoder(strings.NewReader(""))
},
},
bufferPool: sync.Pool{
New: func() interface{} {
return new(bytes.Buffer)
},
},
}
}
func (jp *JSONPerformance) Marshal(v interface{}) ([]byte, error) {
buf := jp.bufferPool.Get().(*bytes.Buffer)
buf.Reset()
defer jp.bufferPool.Put(buf)
enc := jp.encoderPool.Get().(*json.Encoder)
enc.SetEscapeHTML(false)
oldWriter := enc.Linter
enc.SetWriter(buf)
defer func() {
enc.SetWriter(oldWriter)
jp.encoderPool.Put(enc)
}()
if err := enc.Encode(v); err != nil {
return nil, err
}
// Copy to avoid returning a reference to the pooled buffer
result := make([]byte, buf.Len())
copy(result, buf.Bytes())
return result, nil
}
esta abordagem reduziu alocações de memória em nossos benchmarks, principalmente quando fazíamos em conjunto com o pooling de buffers, o que é crucial para sistemas financeiros de alto volume que processam milhões de transações.
paginação inteligente e universal
lidar com grandes conjuntos de dados é um desafio comum em operações financeiras. por isso, desenvolvemos um sistema de paginação universal que funciona com diferentes endpoints e paradigmas:
// Interface genérica para qualquer tipo de paginador
type Paginator[T any] interface {
HasNext() bool
Next() (*ListResponse[T], error)
Reset()
}
// Exemplo de uso para listar transações com paginação automática
paginator := client.Entity.Transactions.GetTransactionPaginator(
ctx, "org-id", "ledger-id", &models.ListOptions{Limit: 100},
)
totalTransactions := 0
for paginator.HasNext() {
page, err := paginator.Next()
if err != nil {
return err
}
for _, tx := range page.Items {
// Processar cada transação
processTransaction(tx)
totalTransactions++
}
}
fmt.Printf("Processadas %d transações no total\n", totalTransactions)
nossa implementação suporta:
- paginação por offset/limit (mais comum)
- paginação por cursor (mais eficiente para grandes datasets)
- prefetching para melhor performance
- preservação de filtros e ordenação entre páginas
- adaptação automática ao tipo de paginação do endpoint
concorrência controlada para alto volume
para lidar com os requisitos de alta performance, investimos pesadamente em modelos de concorrência bem controlados:
// Worker pool genérico com controle fino de concorrência
func WorkerPool[T, R any](
ctx context.Context,
items []T,
workFn func(context.Context, T) (R, error),
opts ...PoolOption,
) []Result[T, R] {
// Config default
options := defaultPoolOptions()
for _, opt := range opts {
opt(options)
}
resultCh := make(chan Result[T, R], len(items))
var wg sync.WaitGroup
// Semáforo para controlar concorrência
sem := make(chan struct{}, options.workers)
// Rate limiter se especificado
var limiter <-chan time.Time
if options.rateLimit > 0 {
ticker := time.NewTicker(time.Second / time.Duration(options.rateLimit))
defer ticker.Stop()
limiter = ticker.C
}
for i, item := range items {
// Respeita cancelamento pelo context
if ctx.Err() != nil {
break
}
// Rate limiting se ativo
if limiter != nil {
select {
case <-ctx.Done():
break
case <-limiter:
// Continue quando o rate limiter permitir
}
}
// Adquire slot no semáforo
sem <- struct{}{}
wg.Add(1)
go func(idx int, item T) {
defer wg.Done()
defer func() { <-sem }() // Libera o semáforo ao final
// Cria um timeout interno se necessário
execCtx := ctx
if options.timeout > 0 {
var cancel context.CancelFunc
execCtx, cancel = context.WithTimeout(ctx, options.timeout)
defer cancel()
}
// Executa a função de trabalho
result, err := workFn(execCtx, item)
// Envia o resultado
resultCh <- Result[T, R]{
Index: idx,
Item: item,
Value: result,
Error: err,
}
}(i, item)
}
// Fecha o canal de resultados quando todo trabalho estiver concluído
go func() {
wg.Wait()
close(resultCh)
}()
// Coleta resultados
var results []Result[T, R]
for result := range resultCh {
results = append(results, result)
}
// Ordena resultados se necessário
if options.ordered {
sort.Slice(results, func(i, j int) bool {
return results[i].Index < results[j].Index
})
}
return results
}
esta implementação permite:
- controle preciso de concorrência para evitar sobrecarregar a API
- rate limiting para respeitar limites da API
- ordenação opcional de resultados
- cancelamento gracioso de operações em andamento
- timeouts individuais para tarefas
tratamento avançado de erros financeiros
em um sistema financeiro, os erros são parte crítica da experiência do desenvolvedor. investimos em um sistema sofisticado de tratamento de erros:
// Exemplo de uso de erros especializados
switch {
case errors.IsValidationError(err):
// Trata erro de validação
fmt.Println("Erro de validação:", err)
// Extrai erros por campo
fieldErrors := errors.GetFieldErrors(err)
for _, fieldErr := range fieldErrors {
fmt.Printf("Campo %s: %s\n", fieldErr.Field, fieldErr.Message)
}
case errors.IsInsufficientBalanceError(err):
// Trata erro específico financeiro
fmt.Println("Saldo insuficiente:", err)
case errors.IsRateLimitExceededError(err):
// Implementa backoff e retry
fmt.Println("Limite de requisições excedido, aguardando:", err)
time.Sleep(exponentialBackoff(attempt))
case errors.IsAuthenticationError(err):
// Problema com autenticação
fmt.Println("Erro de autenticação, renovando token:", err)
renewToken()
}
adicionalmente, nossos erros incluem:
- categorização clara (validação, autenticação, rede, etc)
- detalhes específicos por domínio financeiro (saldo insuficiente, limites, etc)
- códigos de erro e status HTTP associados
- sugestões de correção para o desenvolvedor
- integração com observabilidade (geração de span de erro)
testes de stress e verificação de escalabilidade
uma característica distintiva da nossa SDK foi o desenvolvimento de uma suite robusta de testes de stress:
// Trecho do código da suite de stress testing
func (st *StressTest) Run(ctx context.Context) error {
logger := st.observability.GetLogger()
logger.Info("Iniciando teste de stress", "workers", st.config.ConcurrentWorkers)
// Preparar ambiente de teste
if err := st.SetupTestEnvironment(ctx); err != nil {
return fmt.Errorf("falha ao configurar ambiente: %w", err)
}
// Executar até interrupção ou duração configurada
var wg sync.WaitGroup
ctx, cancel := context.WithCancel(ctx)
defer cancel()
// Inicia monitoramento de métricas
st.metrics = NewMetricsCollector(st.observability)
go st.metrics.Start(ctx)
// Inicia workers para gerar carga
for i := 0; i < st.config.ConcurrentWorkers; i++ {
wg.Add(1)
go func(workerID int) {
defer wg.Done()
st.runWorker(ctx, workerID)
}(i)
}
// Aguarda conclusão
wg.Wait()
logger.Info("Teste de stress concluído", "transações", st.metrics.TotalTransactions())
return nil
}
esta suite nos permitiu:
- validar o comportamento sob carga extrema (50.000+ tx/s ou modelos de 1:1 em conta com 10000+ tx/s)
- identificar e corrigir bottlenecks antes do lançamento
- verificar o comportamento de mecanismos de retry e resiliência
- testar a degradação graceful sob falhas parciais
- validar limites de recursos (memória, CPU, conexões, e o próprio sistema distribuído)
no ponto específico de validar limites de recursos e do sistema distribuído, utilizamos o pumba para simular cenários de caos (em docker), e isso nos ajudou a identificar pontos interessantes na implementação do próprio backend.
documentação dirigida por exemplos
percebemos que bons exemplos são mais valiosos que documentação abstrata. por isso, demos ênfase especial a exemplos práticos:
// Exemplo completo de transferência entre contas
func ExampleTransferBetweenAccounts() {
// Inicializar cliente
c, err := client.New(
client.WithAuthToken(os.Getenv("MIDAZ_TOKEN")),
client.UseAllAPIs(),
)
if err != nil {
log.Fatalf("Erro inicializando cliente: %v", err)
}
// Definir detalhes da transação
input := &models.TransactionDSLInput{
Description: "Transferência para pagamento de aluguel",
Send: &models.DSLSend{
Asset: "BRL",
Value: 150000, // R$ 1.500,00
Scale: 2,
Source: &models.DSLSource{
From: []models.DSLFromTo{
{
Account: "conta-origem-123",
Amount: &models.DSLAmount{
Asset: "BRL",
Value: 150000,
Scale: 2,
},
},
},
},
Distribute: &models.DSLDistribute{
To: []models.DSLFromTo{
{
Account: "conta-destino-456",
Amount: &models.DSLAmount{
Asset: "BRL",
Value: 150000,
Scale: 2,
},
},
},
},
},
Metadata: map[string]any{
"referencia": "aluguel-julho-2025",
"categoria": "moradia",
},
}
// Executar a transação
tx, err := c.Entity.Transactions.CreateTransactionWithDSL(
context.Background(),
"org-exemplo",
"ledger-principal",
input,
)
if err != nil {
log.Fatalf("Erro na transferência: %v", err)
}
fmt.Printf("Transferência realizada com sucesso! ID: %s\n", tx.ID)
}
cada exemplo está acompanhado de comentários detalhados e cobrimos todos os cenários principais:
- criação de entidades (organizações, contas, etc)
- operações financeiras (transferências, depósitos, saques)
- consultas e relatórios (balanços, extratos, histórico)
- workflows completos (onboarding, transações)
a vantagem da unificação de interface
falando um pouco sobre a vantagem de unificar múltiplas APIs de backend sob uma interface coerente: no mundo financeiro, frequentemente temos APIs separadas para diferentes domínios:
- API de onboarding (organizações, contas)
- API de transactions (transferências, saldos)
- API de compliance (KYC, AML)
- API de reporting (relatórios, extratos)
- etc etc etc
cada uma com suas peculiaridades e convenções. nossa SDK unifica todas sob uma única interface consistente:
// Mesmo padrão para todas as APIs, independente do backend
// API de onboarding
organization, err := client.Entity.Organizations.CreateOrganization(ctx, input)
// API de transactions
transaction, err := client.Entity.Transactions.CreateTransaction(ctx, orgID, ledgerID, input)
// API de balanços
balance, err := client.Entity.Accounts.GetBalance(ctx, orgID, ledgerID, accountID)
esta unificação traz benefícios significativos para o desenvolvedor em si:
- reduz a curva de aprendizado para novos desenvolvedores
- abstrai as diferenças de implementação entre serviços
- permite evolução independente do backend e frontend
- facilita migração entre diferentes versões de APIs
a discussão sobre fronteiras: o que aprendemos
voltando à questão inicial sobre as fronteiras de responsabilidade entre servidor e cliente, concluímos que a resposta não é binária. em vez disso, é um espectro que depende do contexto:
- Validação: tanto cliente quanto servidor devem validar - cliente para UX e DevEx, servidor para segurança
- Resiliência: principalmente responsabilidade do cliente, com suporte do servidor (idempotência, o que nossa API também trata com uma option específica de WithIdempotency())
- Performance: responsabilidade compartilhada, com otimizações específicas em cada lado
- Domínio: o servidor define o modelo, mas o cliente pode enriquecê-lo com abstrações úteis
o que ficou claro é que SDKs não são meros wrappers de API - elas são produtos completos que precisam considerar toda a experiência do desenvolvedor e os requisitos específicos do domínio.
trade-offs e desafios de design importantes
durante o desenvolvimento da SDK, nos confrontamos com vários trade-offs importantes que impactam diretamente desenvolvedores e usuários:
validação no cliente vs. sincronização com o servidor
a implementação de validações robustas no cliente traz benefícios claros de performance e experiência do desenvolvedor, mas também introduz um desafio:
// Se estas regras de validação mudam no servidor...
if !assetCodePattern.MatchString(asset) {
return fmt.Errorf("invalid asset code format: %s (must be 3-4 uppercase letters)", asset)
}
// ...e o cliente não atualiza a SDK, teremos inconsistências
este é um trade-off significativo:
- Vantagem: redução de latência e feedback instantâneo
- Desvantagem: potencial divergência entre regras cliente/servidor se os clientes não atualizarem a SDK
nossa solução foi documentar claramente a necessidade de atualizações regulares e fornecer testes que ajudam a detectar divergências de validação, além de fazer um robusto linking entre models do cliente e do servidor.
filosofia de tratamento de erros: o que tratar automaticamente?
uma decisão crítica foi determinar quais erros a SDK deveria tratar automaticamente versus quais deveriam ser expostos para o backend:
// Erros tratados automaticamente pela SDK
if errors.IsTemporaryNetworkError(err) || errors.IsRateLimitExceeded(err) {
// Aplicar retry automaticamente
return retry.Do(ctx, operation)
}
// Erros que são propagados ao aplicativo
if errors.IsBusinessRuleViolation(err) || errors.IsValidationError(err) {
// O desenvolvedor precisa tratar estes casos explicitamente
return err
}
adotamos a filosofia de que:
- erros transientes de infraestrutura/rede são tratados pela SDK
- erros de domínio financeiro ou validação são propagados para permitir tratamento adequado pelo backend
- erros críticos (autenticação, permissões) são propagados com contexto enriquecido para facilitar diagnóstico
integração de observabilidade: o equilíbrio entre intrusão e visibilidade
a observabilidade é crítica em sistemas financeiros, mas quanto a SDK deve impor versus oferecer como opcional? aqui é um caso a parte. remodelamos toda a stack de observabilidade (usando opentelemetry) para que o desenvolvedor possa escolher o que ele quer e o que ele não quer, sem sermos "opinionated" com relação ao tema -- bem diferente do contexto do midaz open-source, que é mais "opinionated".
// Abordagem não-intrusiva que adotamos:
client, err := client.New(
// Configuração básica
client.WithAuthToken("token"),
// Observabilidade totalmente opcional
client.WithObservability(
observability.WithTracing(userDefinedTraceProvider), // opcional
observability.WithMetrics(userDefinedMeterProvider), // opcional
observability.WithLogging(userDefinedLogger), // opcional
),
)
decidimos por uma abordagem modular onde:
- a SDK funciona perfeitamente sem observabilidade configurada
- desenvolvedores podem injetar seus próprios providers de observabilidade
- fornecemos implementações default para casos simples
- instrumentamos pontos críticos nas operações financeiras para máxima visibilidade
operações assíncronas e notificações
transações financeiras frequentemente envolvem processos assíncronos. como a SDK deve lidar com isso?
// Opção 1: Polling (implementamos inicialmente)
status, err := client.Entity.Transactions.GetTransactionStatus(ctx, txID)
// Opção 2: Webhooks (planejado para futuro)
client.Entity.Transactions.RegisterWebhookHandler(webhookHandler)
// Opção 3: Response streaming (planejado para futuro)
stream, err := client.Entity.Transactions.WatchTransaction(ctx, txID)
for update := range stream.Updates() {
// Processar atualizações em tempo real
}
nossa abordagem foi evolutiva. tomamos uma decisão de implementar o básico agora, mas permitindo uma modelagem como a acima exposta:
- começamos com polling simples para compatibilidade ampla
- adicionaremos suporte a webhooks para notificações em tempo real
- e planejamos, por fim, streaming de atualizações para casos de uso mais complexos
estratégia de versionamento e compatibilidade planejado para em breve, dado que estamos na V1 do Midaz
o versionamento é um desafio significativo em APIs financeiras que evoluem constantemente:
// Suporte a múltiplas versões de API
client, err := client.New(
client.WithAPIVersion("v1"), // default
// ou
client.WithAPIVersion("v2"), // novas funcionalidades
)
// Usando feature flags para recursos em preview
client.Entity.Transactions.CreateTransaction(
ctx, orgID, ledgerID, input,
transactions.WithFeatureEnabled("instant-settlement"),
)
adotaremos uma estratégia de versionamento com múltiplas camadas:
- versionamento semântico tradicional para a SDK
- compatibilidade com múltiplas versões de API em uma única versão da SDK
- feature flags para recursos experimentais
- aliases de métodos deprecados com warnings para facilitar migrações
aprendizados para o futuro
lançar a primeira versão de uma SDK não é o fim da jornada, mas apenas o começo. já identificamos diversas áreas para evolução:
- Estratégia evolutiva: como evoluir a API sem quebrar compatibilidade? como evoluir o backend sem quebrar compatibilidade? como fazer tudo isso e mantermos o decoupling super necessário entre midaz e midaz-sdk-golang versioning
- Abstrações de domínio: quais abstrações de nível superior devemos oferecer para simplificar fluxos comuns? que tal evoluirmos para DoWithdrawal, DoDeposit, DoTransfer, etc, fazendo a abstração entre a conta @external/asset e o domínio de transações. que tal evoluirmos para sdk apis 100% fluentes?
- Balanceamento de responsabilidades: conforme o produto evolui, qual o equilíbrio ideal entre lógica no servidor e no cliente? afinal, não queremos obrigar nossos clientes a usarem a sdk, até pq não conseguiremos manter sdks em um número grande de linguagens
- Extensibilidade: como permitir que usuários estendam a SDK para seus casos específicos? o fato de sermos open-source facilita isso e chama o público para nos ajudar, mas sabemos da nossa responsabilidade como principais mantenedores do midaz e sua stack
particularmente interessante é a questão dos modelos de domínio. por exemplo, em vez de apenas oferecer a API para criar uma transação, devemos evoluir para oferecer construções de mais alto nível:
// Potencial evolução futura - Abstrações de domínio mais ricas
// Em vez de apenas criar transações
tx, err := client.Entity.Transactions.CreateTransaction(ctx, orgID, ledgerID, createTxInput)
// Oferecer fluxos de domínio completos
transferResult, err := client.Workflows.DoTransfer(ctx, transferOptions)
paymentResult, err := client.Workflows.DoPayment(ctx, paymentOptions)
fxResult, err := client.Workflows.DoForeignExchangeTransfer(ctx, fxOptions)
o padrão functional options: flexibilidade sem complexidade
um padrão de design que merece destaque especial na nossa SDK é o uso extensivo de functional options (ou a implementação parcial de fluent APIs). este padrão permite configuração flexível sem comprometer a legibilidade ou simplicidade:
// Definição básica do padrão
type ClientOption func(*Client) error
func WithTimeout(timeout time.Duration) ClientOption {
return func(c *Client) error {
if timeout <= 0 {
return errors.New("timeout must be positive")
}
c.httpClient.Timeout = timeout
return nil
}
}
// Uso elegante e extensível
client, err := client.New(
client.WithAuthToken("seu-token"),
client.WithTimeout(30 * time.Second),
client.WithRetries(3),
client.WithObservability(true),
)
este padrão oferece múltiplas vantagens:
- evita a explosão de construtores para diferentes combinações de opções
- permite adicionar novos parâmetros sem quebrar código existente
- facilita testes e configurações condicionais
- proporciona validação no momento da configuração
- permite opções compostas que aplicam múltiplas configurações
aplicamos o mesmo padrão em diversos níveis da SDK, não apenas na inicialização do cliente:
// Nível de operação - opções específicas por operação
tx, err := client.Entity.Transactions.CreateTransaction(
ctx, orgID, ledgerID, input,
transactions.WithIdempotencyKey("unique-key-123"),
transactions.WithPriority(transactions.PriorityHigh),
)
// Nível de entidade - configurações por domínio
accountSvc := client.Entity.Accounts.WithOptions(
accounts.WithCaching(true),
accounts.WithValidation(accounts.ValidationStrict),
)
conclusão
construir a SDK do Midaz foi uma jornada de aprendizado e de um estado de flow absurdo. as complexidades de sistemas distribuídos, especialmente no domínio financeiro, e as decisões que tomamos - desde validação robusta no cliente até mecanismos avançados de resiliência e performance - foram todas guiadas pela pergunta: "o que tornaria a vida do desenvolvedor mais fácil e o sistema mais confiável?"
no final, a fronteira entre cliente e servidor é mais sobre colaboração do que separação. uma boa SDK não apenas encapsula uma API, mas amplia suas capacidades e protege contra suas limitações.
a gestão cuidadosa dos trade-offs que destacamos - validação no cliente versus sincronização com o servidor, tratamento automático versus exposição de erros, modularidade de observabilidade, e estratégias para operações assíncronas - moldou uma SDK que equilibra simplicidade e poder.
se você estiver construindo uma SDK, especialmente para sistemas críticos como o financeiro, sugiro considerar cuidadosamente onde colocar essas fronteiras de responsabilidade. sua resposta pode não ser a mesma que a nossa, mas fazer a pergunta já é um excelente começo.
bora?
para quem quiser explorar mais, a Midaz SDK está disponível em nosso GitHub e inclui extensos exemplos de uso. os exemplos de código e implementações de referência fornecem insights valiosos sobre como implementar padrões robustos em SDKs financeiras.
o que você acha? onde você traçaria a linha entre responsabilidades de cliente e servidor em uma SDK? aproveita e dá uma estrelinha pra gente! o midaz está aqui, nosso frontend console está aqui, e nossa sdk está aqui.
next steps?
port para js. quite a challenge!
beijos,
fred.



