
















































































































































































![How to Use AI as a Productivity Tool with Mike Kaput [MAICON 2025 Speaker Series]](https://www.marketingaiinstitute.com/hubfs/v2MAICON-Speaker_Series.png)
![[The AI Show Episode 152]: ChatGPT Connectors, AI-Human Relationships, New AI Job Data, OpenAI Court-Ordered to Keep ChatGPT Logs & WPP’s Large Marketing Model](https://www.marketingaiinstitute.com/hubfs/ep%20152%20cover.png)








































































































![Designing a Robust Modular Hardware-Oriented Application in C++ [closed]](https://i.sstatic.net/f2sQd76t.webp)






























































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)






















































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)

_designer491_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)





























































































![Google Play Store not showing Android system app updates [U]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2021/08/google-play-store-material-you.jpeg?resize=1200%2C628&quality=82&strip=all&ssl=1)











































































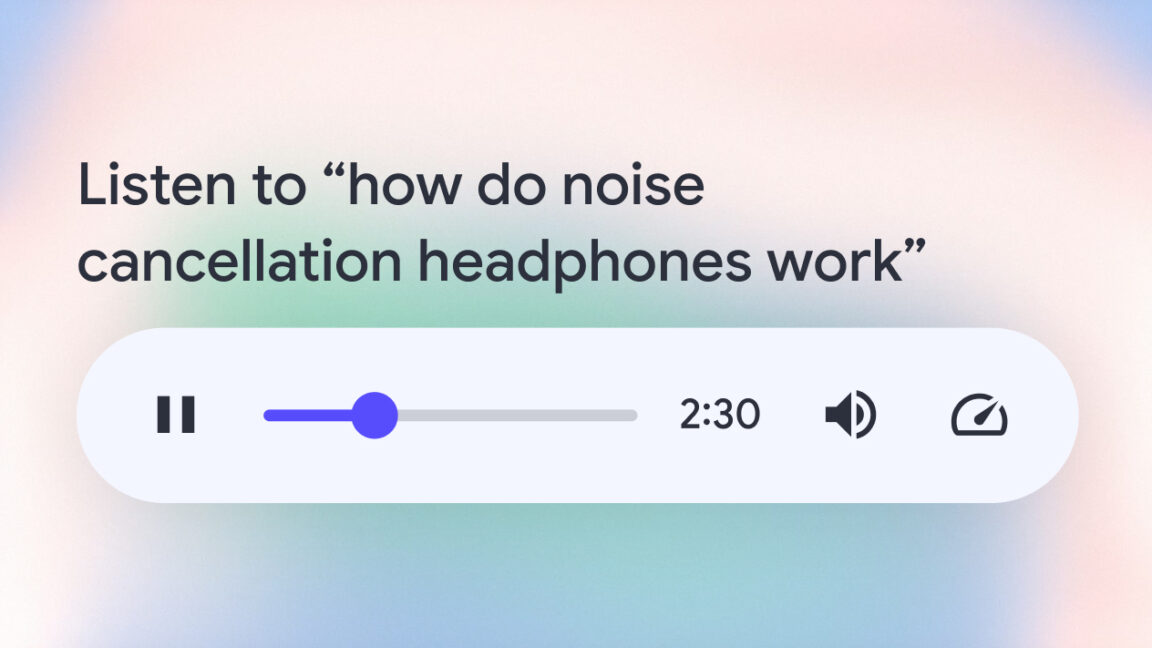
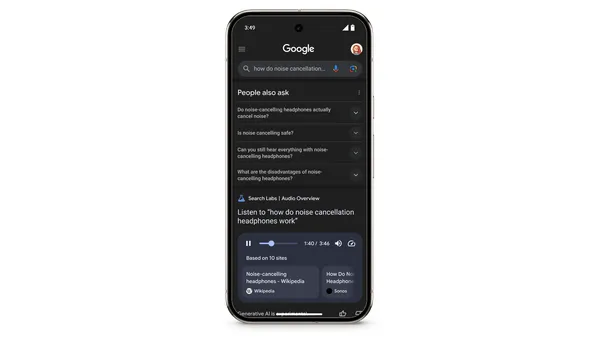
In an Oxford study, LLMs correctly identified medical conditions 94.9% of the time when given test scenarios directly, vs. 34.5% when prompted by human subjects (Nick Mokey/VentureBeat)
Nick Mokey / VentureBeat: In an Oxford study, LLMs correctly identified medical conditions 94.9% of the time when given test scenarios directly, vs. 34.5% when prompted by human subjects — Headlines have been blaring it for years: Large language models (LLMs) can not only pass medical licensing exams but also outperform humans.

![]() Nick Mokey / VentureBeat:
Nick Mokey / VentureBeat:
In an Oxford study, LLMs correctly identified medical conditions 94.9% of the time when given test scenarios directly, vs. 34.5% when prompted by human subjects — Headlines have been blaring it for years: Large language models (LLMs) can not only pass medical licensing exams but also outperform humans.


