![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)












































































































































































































































































_Aleksey_Funtap_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_Sergey_Tarasov_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)









































































































![Apple Foldable iPhone to Feature New Display Tech, 19% Thinner Panel [Rumor]](https://www.iclarified.com/images/news/97271/97271/97271-640.jpg)
![Apple Developing New Chips for Smart Glasses, Macs, AI Servers [Report]](https://www.iclarified.com/images/news/97269/97269/97269-640.jpg)
![Apple Shares New Mother's Day Ad: 'A Gift for Mom' [Video]](https://www.iclarified.com/images/news/97267/97267/97267-640.jpg)
![Apple Shares Official Trailer for 'Stick' Starring Owen Wilson [Video]](https://www.iclarified.com/images/news/97264/97264/97264-640.jpg)
































































































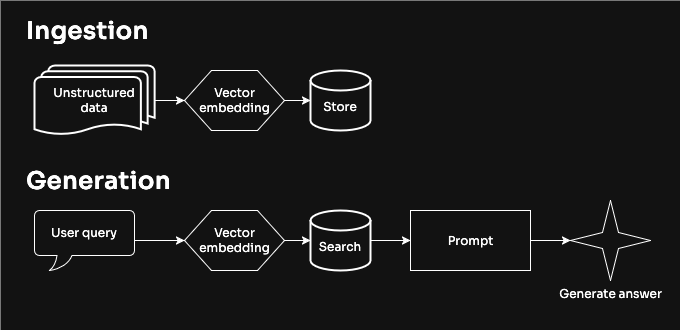
End-to-End Distributed Tracing: Integrating Linkerd with Splunk Observability Cloud
Observability is critical at multiple layers of an organization. For IT operations teams, whose primary focus is maintaining system uptime and reliability, it provides real-time visibility into system performance, sends alerts when anomalies occur, and offers critical data to quickly diagnose issues. Meanwhile, at the executive level, observability supports strategic decision-making by visualizing KPIs related to customer journeys via a user friendly dashboards. For example, a retail company might track the cost of abandoned shopping carts or the average customer spend. According to a 2024 Dynatrace survey, 77% of technology leaders report that more non-IT teams are now involved in decisions driven by observability insights. Data is at the core of observability and monitoring, typically originating from logs, metrics, and traces. As applications add new functionality and user numbers grow, the data volume can skyrocket, making analysis increasingly complex. The challenge becomes even more pronounced when organizations shift from monolithic architectures to microservices-based systems, where an application is composed of numerous loosely coupled services where a single user request may trigger a series of calls across multiple back-end services, each contributing to overall performance and reliability. In fact, 79% of technology leaders report that cloud-native technology stacks generate so much data that it exceeds human capacity to manage. Additionally, microservices often communicate via asynchronous or synchronous calls that happen concurrently and independently, complicating troubleshooting efforts. Without distributed tracing, pinpointing delays or failures in this parallel ecosystem would be a daunting task. Distributed Tracing and Observability Tools To reduce complexity and avoid manually piecing together data from different monitoring systems, many organizations turn to integrated observability platforms. Vendors such as Dynatrace, Cisco, Datadog, and New Relic have developed or acquired solutions that bring logs, metrics, traces, and infrastructure data under one roof. On the open-source side, tools like Zipkin and Jaeger offer user-friendly interfaces for visualizing distributed traces. How Distributed Tracing Works Distributed tracing typically starts by updating the application code so that each incoming request can be tracked as it travels through multiple services. Many implementations use the OpenTracing API, which supports popular languages like Go, Java, Python, JavaScript, Ruby, and PHP. This automatically creates “spans” whenever a request enters a service, eliminating the need for custom tracing logic. For example: { "traceid": "123abc4d5678ef91g234h", "spanID": "a12cde34f5gh67", "parentSpanID": "a1b2345678c91", "operationName": "/API", "serviceName": "API", "startTime": 1608239395286533, "duration": 1000000, "logs": [], "tags": [ { "http.method": "GET", "http.path": "/api" } ] } Spans are then linked through unique trace and span IDs to form a single trace for each request, revealing the end-to-end path across all involved services. If the services communicate via HTTP, the trace information can be passed through HTTP headers, using open-source standards such as B3. B3 uses headers like X-B3-TraceId, X-B3-SpanId, and X-B3-ParentSpanId to carry identifiers from one service to the next. Spans are sent to the collector, which validates them, applies any necessary transformations, and stores them in back-end storage before rendering them in a UI. Distributed Tracing and Linkerd Linkerd supports distributed tracing by emitting trace spans directly from its data-plane proxies, using either OpenCensus or OpenTelemetry. When the Linkerd proxy detects a tracing header in an incoming HTTP request, it automatically creates a span to capture metrics such as the time spent inside the proxy and other relevant metadata. Integrating Linkerd with Splunk In this tutorial, you’ll learn how to integrate Linkerd with Splunk, one of the major observability platforms in the Gartner Magic Quadrant. We’ll start by creating a local Kubernetes environment, installing Linkerd, deploying a sample application, and then configuring everything to send traces to Splunk. We’ll use k3d to create a local Kubernetes cluster: k3d cluster create training \ --agents 0 \ --servers 1 \ --image rancher/k3s:v1.30.8-k3s1 \ --network playground \ --port 8080:80@loadbalancer Next, install Linkerd using Helm and generate your own mTLS certificates with step: helm repo add linkerd-buoyant https://helm.buoyant.cloud helm repo update helm install linkerd-crds \ --create-namespace \ --namespace linkerd \ linkerd-buoyant/linkerd-enterprise-crds step certificate create root.linkerd.cluster.local ca.crt ca.key \ --profile root-ca \ --no-password \ --insecure step certificate create identity.linkerd.cluste

Observability is critical at multiple layers of an organization. For IT operations teams, whose primary focus is maintaining system uptime and reliability, it provides real-time visibility into system performance, sends alerts when anomalies occur, and offers critical data to quickly diagnose issues. Meanwhile, at the executive level, observability supports strategic decision-making by visualizing KPIs related to customer journeys via a user friendly dashboards. For example, a retail company might track the cost of abandoned shopping carts or the average customer spend. According to a 2024 Dynatrace survey, 77% of technology leaders report that more non-IT teams are now involved in decisions driven by observability insights.
Data is at the core of observability and monitoring, typically originating from logs, metrics, and traces. As applications add new functionality and user numbers grow, the data volume can skyrocket, making analysis increasingly complex. The challenge becomes even more pronounced when organizations shift from monolithic architectures to microservices-based systems, where an application is composed of numerous loosely coupled services where a single user request may trigger a series of calls across multiple back-end services, each contributing to overall performance and reliability. In fact, 79% of technology leaders report that cloud-native technology stacks generate so much data that it exceeds human capacity to manage.
Additionally, microservices often communicate via asynchronous or synchronous calls that happen concurrently and independently, complicating troubleshooting efforts. Without distributed tracing, pinpointing delays or failures in this parallel ecosystem would be a daunting task.
Distributed Tracing and Observability Tools
To reduce complexity and avoid manually piecing together data from different monitoring systems, many organizations turn to integrated observability platforms. Vendors such as Dynatrace, Cisco, Datadog, and New Relic have developed or acquired solutions that bring logs, metrics, traces, and infrastructure data under one roof. On the open-source side, tools like Zipkin and Jaeger offer user-friendly interfaces for visualizing distributed traces.
How Distributed Tracing Works
Distributed tracing typically starts by updating the application code so that each incoming request can be tracked as it travels through multiple services. Many implementations use the OpenTracing API, which supports popular languages like Go, Java, Python, JavaScript, Ruby, and PHP. This automatically creates “spans” whenever a request enters a service, eliminating the need for custom tracing logic. For example:
{
"traceid": "123abc4d5678ef91g234h",
"spanID": "a12cde34f5gh67",
"parentSpanID": "a1b2345678c91",
"operationName": "/API",
"serviceName": "API",
"startTime": 1608239395286533,
"duration": 1000000,
"logs": [],
"tags": [
{
"http.method": "GET",
"http.path": "/api"
}
]
}
Spans are then linked through unique trace and span IDs to form a single trace for each request, revealing the end-to-end path across all involved services. If the services communicate via HTTP, the trace information can be passed through HTTP headers, using open-source standards such as B3. B3 uses headers like X-B3-TraceId, X-B3-SpanId, and X-B3-ParentSpanId to carry identifiers from one service to the next.
Spans are sent to the collector, which validates them, applies any necessary transformations, and stores them in back-end storage before rendering them in a UI.
Distributed Tracing and Linkerd
Linkerd supports distributed tracing by emitting trace spans directly from its data-plane proxies, using either OpenCensus or OpenTelemetry. When the Linkerd proxy detects a tracing header in an incoming HTTP request, it automatically creates a span to capture metrics such as the time spent inside the proxy and other relevant metadata.
Integrating Linkerd with Splunk
In this tutorial, you’ll learn how to integrate Linkerd with Splunk, one of the major observability platforms in the Gartner Magic Quadrant. We’ll start by creating a local Kubernetes environment, installing Linkerd, deploying a sample application, and then configuring everything to send traces to Splunk.
We’ll use k3d to create a local Kubernetes cluster:
k3d cluster create training \
--agents 0 \
--servers 1 \
--image rancher/k3s:v1.30.8-k3s1 \
--network playground \
--port 8080:80@loadbalancer
Next, install Linkerd using Helm and generate your own mTLS certificates with step:
helm repo add linkerd-buoyant https://helm.buoyant.cloud
helm repo update
helm install linkerd-crds \
--create-namespace \
--namespace linkerd \
linkerd-buoyant/linkerd-enterprise-crds
step certificate create root.linkerd.cluster.local ca.crt ca.key \
--profile root-ca \
--no-password \
--insecure
step certificate create identity.linkerd.cluster.local issuer.crt issuer.key \
--profile intermediate-ca \
--not-after 8760h \
--no-password \
--insecure \
--ca ca.crt \
--ca-key ca.key
helm install linkerd-control-plane \
--namespace linkerd \
--set license=$BUOYANT_LICENSE \
--set-file identityTrustAnchorsPEM=ca.crt \
--set-file identity.issuer.tls.crtPEM=issuer.crt \
--set-file identity.issuer.tls.keyPEM=issuer.key \
linkerd-buoyant/linkerd-enterprise-control-plane
We’ll use the Emojivoto demo application. The source code uses the contrib.go.opencensus.io/exporter/ocagentlibrary to send OpenCensus traces over gRPC to an agent configured via the OC_AGENT_HOST environment variable.
kubectl apply -f https://run.linkerd.io/emojivoto.yml
Finally, let’s enable automatic sidecar injection for the Emojivoto namespace and restart the deployments, so that the pods are going to be injected with the Linkerd proxy.
kubectl annotate ns emojivoto linkerd.io/inject=enabled
kubectl rollout restart deploy -n emojivoto
Linkerd Jaeger configuration
For this demo, we’ll send proxy metrics to the collector over OpenTelemetry and the application traces over OpenCensus. This setup highlights Linkerd’s flexibility in handling different telemetry protocols.
Linkerd Jaeger Extension has three different components:
- Jaeger (optional): UI for rendering traces collected by the linkerd-jaeger collector.
-
Injector: Injects Linkerd proxies with the environment variables that define the protocol and endpoint for sending traces. For instance,
webhook.collectorSvcAddrsetsLINKERD2_PROXY_TRACE_COLLECTOR_SVC_NAME(the collector endpoint) andwebhook.collectorTraceProtocolspecifies which tracing protocol (OpenCensus or OpenTelemetry) to use. - Collector (optional): Receives traces from the proxies. Its configuration (in the collector-config ConfigMap) includes the list of exporters, endpoints, protocols, and other attributes/metadata.
By default, Linkerd Jaeger configures the proxy to send metrics via OpenTelemetry on port 55678 and enables only that exporter. Since we want both OpenTelemetry and OpenCensus, we need to customize these settings. Below is an example value.yaml snippet showing how to enable multiple exporters:
jaeger:
enabled: false
collector:
config:
receivers:
otlp:
protocols:
grpc: {}
http: {}
opencensus: {}
zipkin: {}
jaeger:
protocols:
grpc: {}
thrift_http: {}
thrift_compact: {}
thrift_binary: {}
processors:
batch: {}
extensions:
health_check: {}
exporters:
jaeger:
endpoint: collector.linkerd-jaeger.svc.cluster.local:14250
tls:
insecure: true
otlp:
endpoint: collector.linkerd-jaeger.svc.cluster.local:4317
tls:
insecure: true
service:
extensions: [health_check]
pipelines:
traces:
receivers: [otlp, opencensus, zipkin, jaeger]
processors: [batch]
exporters: [otlp, jaeger]
Here, we’ve disabled the Jaeger UI because we plan to visualize data in Splunk. Install and configure Linkerd Jaeger via Helm:
helm repo add linkerd-edge https://helm.linkerd.io/edge
helm install linkerd-jaeger \
--create-namespace \
--namespace linkerd-jaeger \
--file value.yaml \
linkerd-edge/linkerd-jaeger
To send application-level (not proxy) traces via OpenCensus, we will need to set the OC_AGENT_HOST environment variable to the Jaeger collector endpoint:
kubectl -n emojivoto set env --all deploy OC_AGENT_HOST=collector.linkerd-jaeger:55678
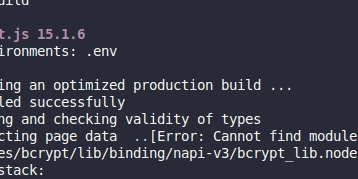
If we check the pods we will be able to confirm that the Linkerd injector has updated environment variables for tracing:
kubectl describe pod -n emojivoto deploy/emoji
...
Containers:
linkerd-proxy:
Environment:
LINKERD2_PROXY_TRACE_ATTRIBUTES_PATH: /var/run/linkerd/podinfo/labels
LINKERD2_PROXY_TRACE_COLLECTOR_SVC_ADDR: collector.linkerd-jaeger:55678
LINKERD2_PROXY_TRACE_PROTOCOL: opentelemetry
LINKERD2_PROXY_TRACE_SERVICE_NAME: linkerd-proxy
LINKERD2_PROXY_TRACE_COLLECTOR_SVC_NAME: collector.linkerd-jaeger.serviceaccount.identity.linkerd.cluster.local
LINKERD2_PROXY_TRACE_EXTRA_ATTRIBUTES: k8s.pod.uid=$(_pod_uid)
k8s.container.name=$(_pod_containerName)
Distributed Tracing with Linkerd and Splunk Observability Cloud
Before being able to send the traces to Splunk we will need to install the OpenTelemetry collector and Splunk agent. To do so:
- Log in to Splunk Observability Cloud.
- Go to Data Management, then select Add Integration.

- Since our cluster is not running in any Cloud Service Provider, choose Deploy Splunk OpenTelemetry Collector for other environments.

- Configure the collector for your setup, and click Next.

- Splunk will generate the deployment commands, including an access token and other parameters.

Execute the instructions listed in the platform. This will typically create a DaemonSet to run the Splunk OpenTelemetry Collector on each node:
kubectl get ds
NAMESPACE NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
...
default splunk-otel-collector-agent 1 1 0 1 0 kubernetes.io/os=linux 47s
The OpenTelemetry opeator and k8s Cluster Receiver deployments:
kubectl get deploy -A
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE
...
default splunk-otel-collector-k8s-cluster-receiver 1/1 1 1 74s
default splunk-otel-collector-operator 0/1 1 0 74s
And a ConfigMap containing the Splunk OpenTelemetry Collector configuration.
kubectl get cm -A
NAMESPACE NAME DATA AGE
default kube-root-ca.crt 1 16m
default splunk-otel-collector-otel-agent 2 2m33s
default splunk-otel-collector-otel-k8s-cluster-receiver 1 2m33s
The agent will now send information about the cluster health directly to splunk.

By default, Linkerd Jaeger will export traces to its own Jaeger or OpenTelemetry endpoint. To forward these traces to Splunk, update the exporters in your value.yaml (or another Helm values file) to point to the Splunk OpenTelemetry Collector service:
jaeger:
enabled: false
collector:
config:
receivers:
otlp:
protocols:
grpc: {}
http: {}
opencensus: {}
zipkin: {}
jaeger:
protocols:
grpc: {}
thrift_http: {}
thrift_compact: {}
thrift_binary: {}
processors:
batch: {}
extensions:
health_check: {}
exporters:
jaeger:
endpoint: splunk-otel-collector-agent.default.svc.cluster.local:14250
tls:
insecure: true
otlp:
endpoint: splunk-otel-collector-agent.default.svc.cluster.local:4317
tls:
insecure: true
service:
extensions: [health_check]
pipelines:
traces:
receivers: [otlp, opencensus, zipkin, jaeger]
processors: [batch]
exporters: [otlp, jaeger]
After updating the Jaeger collector configuration, restart your pods so they pick up the new telemetry settings. Once everything is running, you should see distributed traces from both the Linkerd proxies and the Emojivoto application in Splunk Observability Cloud.


References:
- Linkerd Jaeger Helm Chart: https://artifacthub.io/packages/helm/linkerd2-edge/linkerd-jaeger
- Linkerd Official Documentation: https://linkerd.io/2.17/tasks/distributed-tracing