![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)







































































































































































































































.png?#)







































.webp?#)























































































![[Fixed] Gemini app is failing to generate Audio Overviews](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/03/Gemini-Audio-Overview-cover.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)

![What’s new in Android’s April 2025 Google System Updates [U: 4/14]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-3.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)














![Apple Seeds tvOS 18.5 Beta 2 to Developers [Download]](https://www.iclarified.com/images/news/97011/97011/97011-640.jpg)
![Apple Releases macOS Sequoia 15.5 Beta 2 to Developers [Download]](https://www.iclarified.com/images/news/97014/97014/97014-640.jpg)


















































































































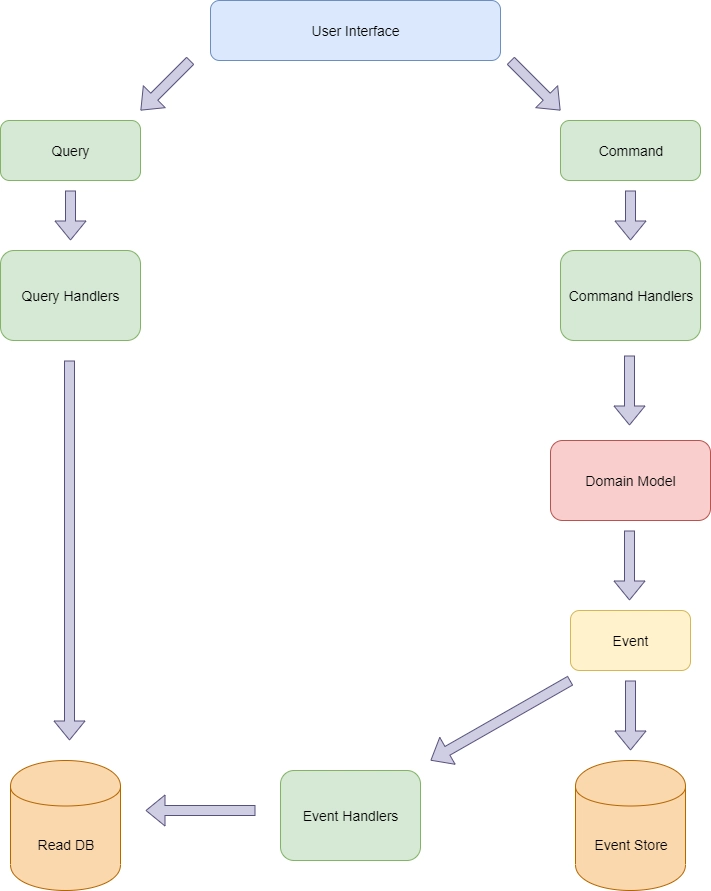
Docker Model Runner: Running AI Models Locally
Docker has released an interesting new feature in beta that should interest anyone working with generative AI. Docker Model Runner allows you to load, run, and manage AI models directly on your local computer without the need to configure complex infrastructure. What is Docker Model Runner and why do you need it? Docker Model Runner is a plugin for Docker Desktop that significantly simplifies working with AI models. The feature is currently in beta testing, available in Docker Desktop version 4.40 and above, and is currently only supported on Macs with Apple Silicon processors. The plugin allows you to: Download models from Docker Hub (from the 'ai' namespace) Run AI models directly from the command line Manage local models (add, view, remove) Interact with models through specified prompts or in chat mode One of the key advantages of Docker Model Runner is the optimization of resource usage. Models are downloaded from Docker Hub only on first use and stored locally. They are loaded into memory only during query execution and unloaded when not in use. Since modern AI models can be quite large, the initial download may take some time, but they are then cached locally for quick access. Another important advantage is the support for OpenAI-compatible APIs, which significantly simplifies integration with existing applications. Basic Docker Model Runner Commands Checking status $ docker model status Docker Model Runner is running Viewing available commands $ docker model help Usage: docker model COMMAND Docker Model Runner Commands: inspect Display detailed information on one model list List the available models that can be run with the Docker Model Runner pull Download a model rm Remove a model downloaded from Docker Hub run Run a model with the Docker Model Runner status Check if the Docker Model Runner is running version Show the Docker Model Runner version Run 'docker model COMMAND --help' for more information on a command. Downloading a model $ docker model pull ai/smollm2 Downloaded: 0.00 MB Model ai/smollm2 pulled successfully During the download it shows the correct size, but after downloading it shows 0.00 MB, but as I mentioned above, this feature is still in beta testing. Viewing local models Example output: $ docker model list MODEL PARAMETERS QUANTIZATION ARCHITECTURE MODEL ID CREATED SIZE ai/smollm2 361.82 M IQ2_XXS/Q4_K_M llama 354bf30d0aa3 2 weeks ago 256.35 MiB Running a model With a one-time prompt: $ docker model run ai/smollm2 "Hello" In dialogue mode: $ docker model run ai/smollm2 Removing a model $ docker model rm ai/smollm2 Integrating Docker Model Runner into your applications Docker Model Runner provides OpenAI-compatible API endpoints, making it easy to integrate with existing applications. Here's an example of calling the chat/completions endpoint from a container: #!/bin/sh curl http://model-runner.docker.internal/engines/llama.cpp/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "ai/smollm2", "messages": [ { "role": "system", "content": "You are a helpful assistant." }, { "role": "user", "content": "Write 500 words about the fall of Rome." } ] }' You can also use Docker Model Runner from the host via the Docker socket: #!/bin/sh curl --unix-socket $HOME/.docker/run/docker.sock \ localhost/exp/vDD4.40/engines/llama.cpp/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "ai/smollm2", "messages": [ { "role": "system", "content": "You are a helpful assistant." }, { "role": "user", "content": "Write 500 words about the fall of Rome." } ] }' Quick start with a GenAI application example If you want to quickly try Docker Model Runner with a ready-made generative AI application, follow these steps: Clone the example repository: $ git clone https://github.com/docker/hello-genai.git In the terminal, navigate to the hello-genai directory. Run run.sh to download the selected model and launch the application. Open the application in your browser at the address specified in the repository's README. Available API endpoints After enabling Docker Model Runner, the following APIs are available: Inside containers http://model-runner.docker.internal/ # Model management POST /models/create GET /models GET /models/{namespace}/{name} DELETE /models/{namespace}/{name} # OpenAI-compatible endpoints GET /engines/llama.cpp/v1/mo

Docker has released an interesting new feature in beta that should interest anyone working with generative AI. Docker Model Runner allows you to load, run, and manage AI models directly on your local computer without the need to configure complex infrastructure.
What is Docker Model Runner and why do you need it?
Docker Model Runner is a plugin for Docker Desktop that significantly simplifies working with AI models.
The feature is currently in beta testing, available in Docker Desktop version 4.40 and above, and is currently only supported on Macs with Apple Silicon processors.
The plugin allows you to:
- Download models from Docker Hub (from the 'ai' namespace)
- Run AI models directly from the command line
- Manage local models (add, view, remove)
- Interact with models through specified prompts or in chat mode
One of the key advantages of Docker Model Runner is the optimization of resource usage. Models are downloaded from Docker Hub only on first use and stored locally. They are loaded into memory only during query execution and unloaded when not in use. Since modern AI models can be quite large, the initial download may take some time, but they are then cached locally for quick access.
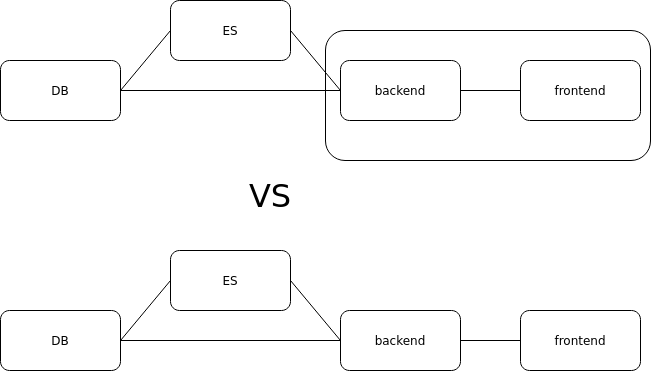
Another important advantage is the support for OpenAI-compatible APIs, which significantly simplifies integration with existing applications.
Basic Docker Model Runner Commands
Checking status
$ docker model status
Docker Model Runner is running
Viewing available commands
$ docker model help
Usage: docker model COMMAND
Docker Model Runner
Commands:
inspect Display detailed information on one model
list List the available models that can be run with the Docker Model Runner
pull Download a model
rm Remove a model downloaded from Docker Hub
run Run a model with the Docker Model Runner
status Check if the Docker Model Runner is running
version Show the Docker Model Runner version
Run 'docker model COMMAND --help' for more information on a command.
Downloading a model
$ docker model pull ai/smollm2
Downloaded: 0.00 MB
Model ai/smollm2 pulled successfully
During the download it shows the correct size, but after downloading it shows 0.00 MB, but as I mentioned above, this feature is still in beta testing.
Viewing local models
Example output:
$ docker model list
MODEL PARAMETERS QUANTIZATION ARCHITECTURE MODEL ID CREATED SIZE
ai/smollm2 361.82 M IQ2_XXS/Q4_K_M llama 354bf30d0aa3 2 weeks ago 256.35 MiB
Running a model
With a one-time prompt:
$ docker model run ai/smollm2 "Hello"
In dialogue mode:
$ docker model run ai/smollm2
Removing a model
$ docker model rm ai/smollm2
Integrating Docker Model Runner into your applications
Docker Model Runner provides OpenAI-compatible API endpoints, making it easy to integrate with existing applications. Here's an example of calling the chat/completions endpoint from a container:
#!/bin/sh
curl http://model-runner.docker.internal/engines/llama.cpp/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ai/smollm2",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Write 500 words about the fall of Rome."
}
]
}'
You can also use Docker Model Runner from the host via the Docker socket:
#!/bin/sh
curl --unix-socket $HOME/.docker/run/docker.sock \
localhost/exp/vDD4.40/engines/llama.cpp/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ai/smollm2",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Write 500 words about the fall of Rome."
}
]
}'
Quick start with a GenAI application example
If you want to quickly try Docker Model Runner with a ready-made generative AI application, follow these steps:
- Clone the example repository:
$ git clone https://github.com/docker/hello-genai.git
In the terminal, navigate to the hello-genai directory.
Run run.sh to download the selected model and launch the application.
Open the application in your browser at the address specified in the repository's README.
Available API endpoints
After enabling Docker Model Runner, the following APIs are available:
Inside containers
http://model-runner.docker.internal/
# Model management
POST /models/create
GET /models
GET /models/{namespace}/{name}
DELETE /models/{namespace}/{name}
# OpenAI-compatible endpoints
GET /engines/llama.cpp/v1/models
GET /engines/llama.cpp/v1/models/{namespace}/{name}
POST /engines/llama.cpp/v1/chat/completions
POST /engines/llama.cpp/v1/completions
POST /engines/llama.cpp/v1/embeddings
Note: You can also omit llama.cpp.
For example, POST /engines/v1/chat/completions.
Inside or outside containers (on the host)
The same endpoints on /var/run/docker.sock
# While the feature is in beta
With the prefix /exp/vDD4.40
Known issues
The docker model command is not recognized
If you get the error:
docker: 'model' is not a docker command
This means that Docker cannot find the plugin. Solution:
$ ln -s /Applications/Docker.app/Contents/Resources/cli-plugins/docker-model ~/.docker/cli-plugins/docker-model
No protection against running excessively large models
Currently, Docker Model Runner does not include protection against running models that exceed available system resources. Attempting to run a model that is too large can lead to serious slowdowns or temporary system inoperability.
Errors with failed downloads
If the model download fails, the docker model run command may still launch the chat interface, although the model is actually unavailable. In this case, it is recommended to manually repeat the docker model pull command.
How to enable or disable the feature
Docker Model Runner is enabled by default in Docker Desktop. If you want to disable this feature:
- Open Docker Desktop settings
- Go to the Beta tab in the Features in development section
- Uncheck Enable Docker Model Runner
- Click Apply & restart
If you don't see the Enable Docker Model Runner checkbox, then enable experimental features.
Conclusion
Docker Model Runner provides a convenient way to work with AI models locally, which is especially useful for developers who want to experiment with generative AI without the need to connect to cloud APIs or configure complex infrastructure.
The feature is in beta, so some issues may arise, but Docker is actively working on fixing them and accepts feedback through the Give feedback link next to the Enable Docker Model Runner setting.
If you're working with generative AI or just want to try local models without unnecessary complications, Docker Model Runner is a great tool worth adding to your arsenal.