








































































































































































![[The AI Show Episode 147]: OpenAI Abandons For-Profit Plan, AI College Cheating Epidemic, Apple Says AI Will Replace Search Engines & HubSpot’s AI-First Scorecard](https://www.marketingaiinstitute.com/hubfs/ep%20147%20cover.png)
























![How to Enable Remote Access on Windows 10 [Allow RDP]](https://bigdataanalyticsnews.com/wp-content/uploads/2025/05/remote-access-windows.jpg)


































































































































































![Legends Reborn tier list of best heroes for each class [May 2025]](https://media.pocketgamer.com/artwork/na-33360-1656320479/pg-magnum-quest-fi-1.jpeg?#)
























































![SoundCloud latest company to hit trouble with AI clause in T&Cs [U]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/05/SoundCloud-latest-company-to-hit-trouble-with-AI-clause-in-TCs.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)









_KristofferTripplaar_Alamy_.jpg?width=1280&auto=webp&quality=80&disable=upscale#)

















































































-xl.jpg)
























![Vision Pro May Soon Let You Scroll With Your Eyes [Report]](https://www.iclarified.com/images/news/97324/97324/97324-640.jpg)
![Apple's 20th Anniversary iPhone May Feature Bezel-Free Display, AI Memory, Silicon Anode Battery [Report]](https://www.iclarified.com/images/news/97323/97323/97323-640.jpg)


































































































Designing ETL Applications with Production and Disaster Recovery in Mind
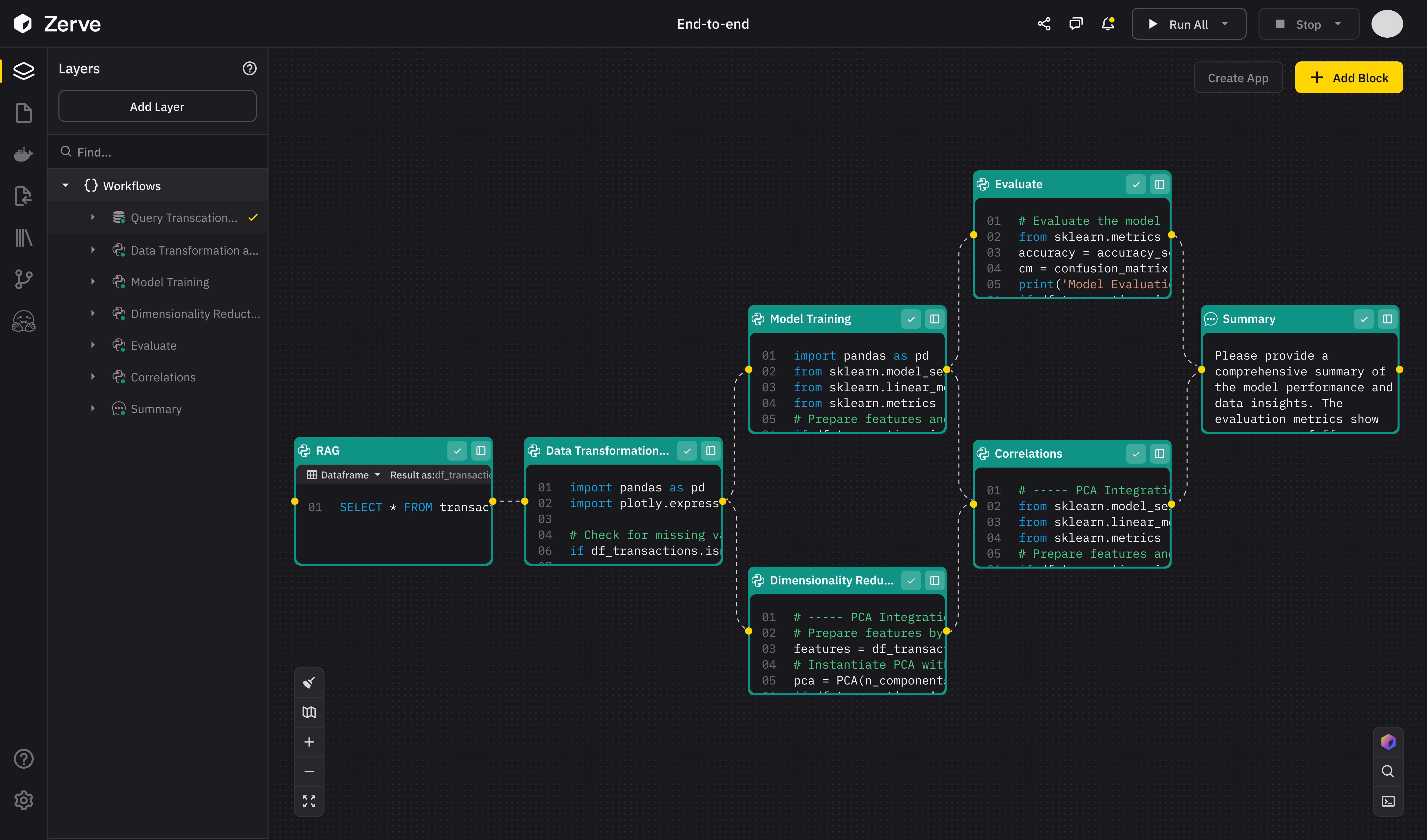
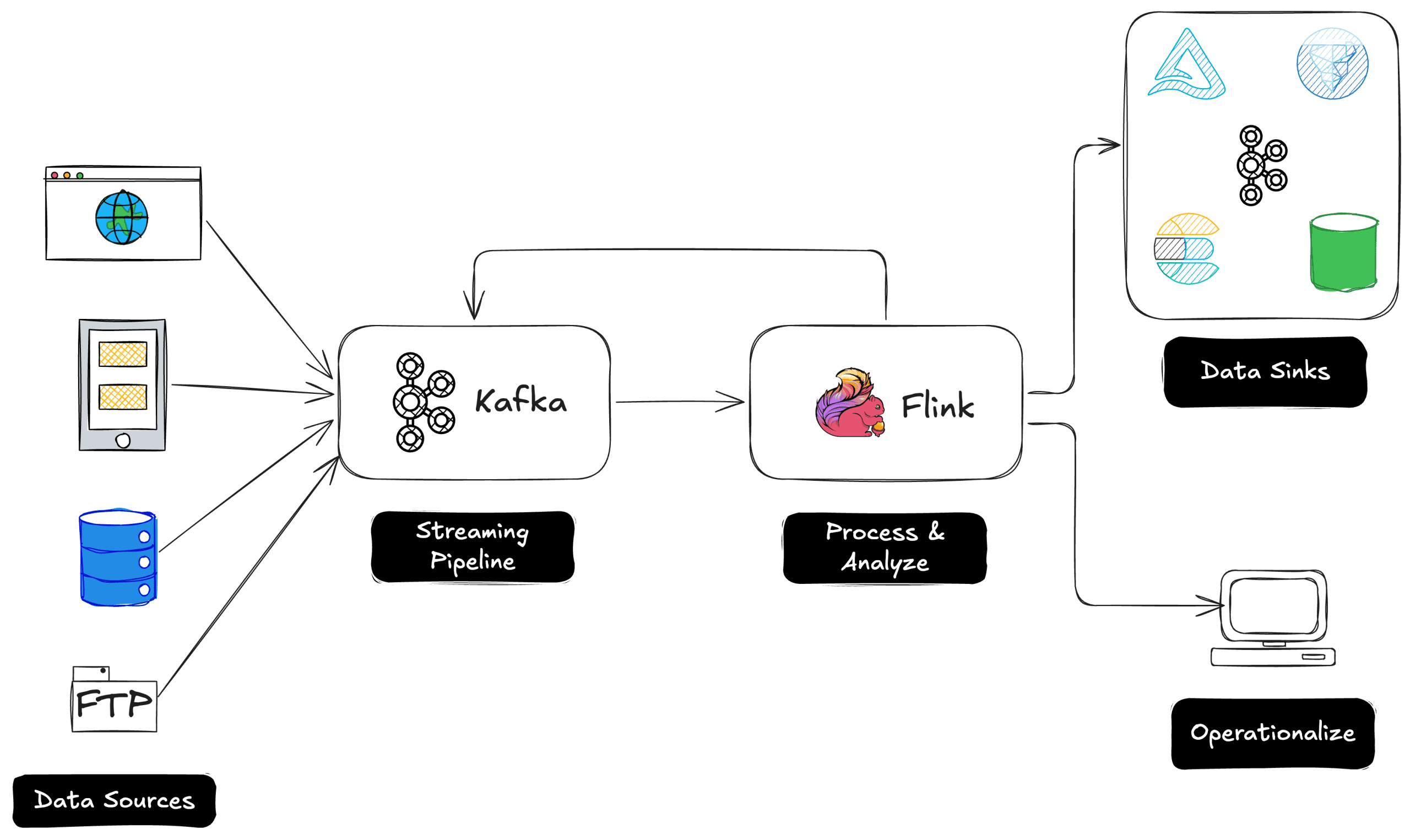
Designing ETL Applications with Production and Disaster Recovery in Mind When you're building ETL (Extract, Transform, Load) applications in a modern enterprise, you can't afford to think of downtime as "someone else's problem." Whether you're moving data between systems, transforming raw logs into useful metrics, or feeding dashboards that executives use to make decisions, your ETL pipeline is often the quiet hero that keeps everything running behind the scenes. But what happens when something goes wrong? Servers crash. Networks go down. Someone accidentally deletes a configuration file—or worse, a ransomware attack takes out half your infrastructure. That’s where a solid Production (PROD) and Disaster Recovery (DR) setup becomes crucial. It’s not about being paranoid—it’s about being prepared. Why You Need Both PROD and DR Imagine this: you’ve got a critical data pipeline running in your production environment. It extracts customer transactions, transforms them for reporting, and loads them into your data warehouse. Everything’s humming along until suddenly... nothing. A fire hits the data center, or a cloud region has a major outage. Now, not only are you losing data, but teams downstream are staring at blank dashboards. Your overnight batch jobs didn’t finish, and executives don’t have their daily KPIs. That’s not just an inconvenience—that’s a business risk. A DR environment gives you a fallback. It’s essentially a clone (or near-clone) of your production environment that can take over when things go south. The idea is to reduce downtime and minimize data loss—two goals that are measured using two key metrics: RTO and RPO. Breaking Down RTO and RPO Let’s make this simple. Recovery Time Objective (RTO) is the maximum acceptable time your system can be down. If your ETL jobs crash at 1:00 AM, and your RTO is two hours, that means the DR system needs to be up and running—picking up where things left off—by 3:00 AM at the latest. Recovery Point Objective (RPO) is about how much data you can afford to lose. Let’s say your ETL job processes data every 15 minutes. If your RPO is also 15 minutes, that means your DR setup should be replicating data at least that frequently. Anything more than 15 minutes of lost data? That’s considered unacceptable. Think of RTO as how fast you can recover, and RPO as how much you’re willing to lose. These two will shape the rest of your architecture. Two Approaches: Active-Active vs. Active-Passive Now that we’ve covered why DR is important and how RTO and RPO fit into the picture, the next question is how you structure your DR setup. The two most common models are: Active-Active: Always On, Always Ready In an Active-Active setup, both environments (PROD and DR) are running all the time. They’re usually in different geographic locations, and they’re both actively handling traffic, load, or job execution. If one goes down, the other just keeps going without skipping a beat. This setup is ideal for businesses that can’t afford any downtime—real-time ETL, fraud detection pipelines, and anything customer-facing. Failover is seamless. There’s no waiting around for the DR environment to "spin up." It's already up. This also means that your RTO is nearly zero and your RPO can be, too. But there’s a cost. You’re paying to keep two environments fully operational. You also need strong data consistency practices—replication, conflict resolution, and monitoring—to keep everything in sync. Active-Passive: Pay Less, Wait a Bit Active-Passive is more budget-friendly. In this model, your PROD environment does all the work while your DR setup sits quietly in the background, waiting to jump in if needed. The DR environment has all the tools, configurations, and scripts needed to take over, but it's not processing live jobs. Instead, it stays synchronized with production—usually via replication tools or backups—and is activated only if something goes wrong. This setup works well for nightly batch jobs or internal analytics processes where a little downtime is acceptable. You might have an RTO of a few hours, and an RPO of 30 minutes. That might be totally fine for your business—and it’s a lot cheaper than running two active environments around the clock. So Which One Should You Use? It depends on your business needs. If your ETL pipeline is mission-critical—feeding customer data into live dashboards or financial systems—you probably need Active-Active. But if your ETL jobs run once a day and aren’t directly tied to real-time operations, Active-Passive might be more than enough. The important thing is to plan for failure. It’s not a matter of if something will go wrong—it’s when. The more thought you put into your PROD and DR setup now, the less stress you’ll have when that moment comes. Closing Thoughts At the end of the day, building a resilient ETL application is about mor

Designing ETL Applications with Production and Disaster Recovery in Mind
When you're building ETL (Extract, Transform, Load) applications in a modern enterprise, you can't afford to think of downtime as "someone else's problem." Whether you're moving data between systems, transforming raw logs into useful metrics, or feeding dashboards that executives use to make decisions, your ETL pipeline is often the quiet hero that keeps everything running behind the scenes.
But what happens when something goes wrong?
Servers crash. Networks go down. Someone accidentally deletes a configuration file—or worse, a ransomware attack takes out half your infrastructure. That’s where a solid Production (PROD) and Disaster Recovery (DR) setup becomes crucial. It’s not about being paranoid—it’s about being prepared.
Why You Need Both PROD and DR
Imagine this: you’ve got a critical data pipeline running in your production environment. It extracts customer transactions, transforms them for reporting, and loads them into your data warehouse. Everything’s humming along until suddenly... nothing. A fire hits the data center, or a cloud region has a major outage. Now, not only are you losing data, but teams downstream are staring at blank dashboards. Your overnight batch jobs didn’t finish, and executives don’t have their daily KPIs.
That’s not just an inconvenience—that’s a business risk.
A DR environment gives you a fallback. It’s essentially a clone (or near-clone) of your production environment that can take over when things go south. The idea is to reduce downtime and minimize data loss—two goals that are measured using two key metrics: RTO and RPO.
Breaking Down RTO and RPO
Let’s make this simple.
Recovery Time Objective (RTO) is the maximum acceptable time your system can be down. If your ETL jobs crash at 1:00 AM, and your RTO is two hours, that means the DR system needs to be up and running—picking up where things left off—by 3:00 AM at the latest.
Recovery Point Objective (RPO) is about how much data you can afford to lose. Let’s say your ETL job processes data every 15 minutes. If your RPO is also 15 minutes, that means your DR setup should be replicating data at least that frequently. Anything more than 15 minutes of lost data? That’s considered unacceptable.
Think of RTO as how fast you can recover, and RPO as how much you’re willing to lose. These two will shape the rest of your architecture.
Two Approaches: Active-Active vs. Active-Passive
Now that we’ve covered why DR is important and how RTO and RPO fit into the picture, the next question is how you structure your DR setup. The two most common models are:
Active-Active: Always On, Always Ready
In an Active-Active setup, both environments (PROD and DR) are running all the time. They’re usually in different geographic locations, and they’re both actively handling traffic, load, or job execution. If one goes down, the other just keeps going without skipping a beat.
This setup is ideal for businesses that can’t afford any downtime—real-time ETL, fraud detection pipelines, and anything customer-facing. Failover is seamless. There’s no waiting around for the DR environment to "spin up." It's already up. This also means that your RTO is nearly zero and your RPO can be, too.
But there’s a cost. You’re paying to keep two environments fully operational. You also need strong data consistency practices—replication, conflict resolution, and monitoring—to keep everything in sync.
Active-Passive: Pay Less, Wait a Bit
Active-Passive is more budget-friendly. In this model, your PROD environment does all the work while your DR setup sits quietly in the background, waiting to jump in if needed.
The DR environment has all the tools, configurations, and scripts needed to take over, but it's not processing live jobs. Instead, it stays synchronized with production—usually via replication tools or backups—and is activated only if something goes wrong.
This setup works well for nightly batch jobs or internal analytics processes where a little downtime is acceptable. You might have an RTO of a few hours, and an RPO of 30 minutes. That might be totally fine for your business—and it’s a lot cheaper than running two active environments around the clock.
So Which One Should You Use?
It depends on your business needs.
If your ETL pipeline is mission-critical—feeding customer data into live dashboards or financial systems—you probably need Active-Active. But if your ETL jobs run once a day and aren’t directly tied to real-time operations, Active-Passive might be more than enough.
The important thing is to plan for failure. It’s not a matter of if something will go wrong—it’s when. The more thought you put into your PROD and DR setup now, the less stress you’ll have when that moment comes.
Closing Thoughts
At the end of the day, building a resilient ETL application is about more than just moving data from point A to point B. It's about trust—ensuring that your systems can keep running, even when the unexpected happens.
Whether you go with Active-Active or Active-Passive, whether your RTO is five minutes or five hours, the key is having a plan and testing it regularly. Your business stakeholders will thank you—not just for building something that works, but for building something that endures.


