




































































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)








































































































































































































































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)




























































































![Severance-inspired keyboard could cost up to $699 – have your say [Video]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/05/Severance-inspired-keyboard-could-cost-up-to-699-%E2%80%93-have-your-say-Video.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)




![Google Home app fixes bug that repeatedly asked to ‘Set up Nest Cam features’ for Nest Hub Max [U]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2022/08/youtube-premium-music-nest-hub-max.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)










































































































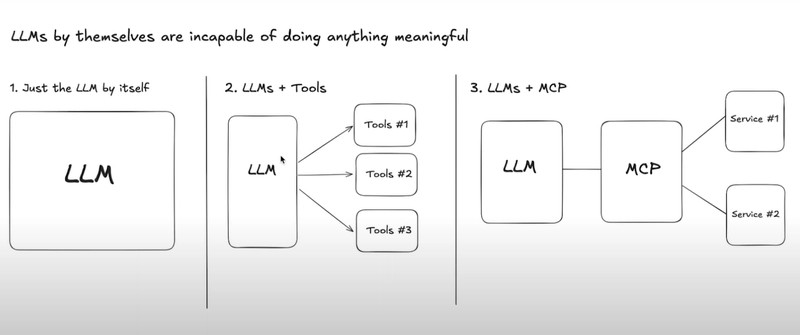
Build Real-Time Knowledge Graph For Documents with LLM
CocoIndex makes it easy to build and maintain knowledge graphs with continuous source updates. In this blog, we will process a list of documents (using CocoIndex documentation as an example). We will use LLM to extract relationships between the concepts in each document. We will generate two kinds of relationships: Relationships between subjects and objects. E.g., "CocoIndex supports Incremental Processing" Mentions of entities in a document. E.g., "core/basics.mdx" mentions CocoIndex and Incremental Processing. We are constantly improving, and more features and examples are coming soon. Stay tuned and follow our progress by starring our GitHub repo. Prerequisites Install PostgreSQL. CocoIndex uses PostgreSQL internally for incremental processing. Install Neo4j, a graph database. Configure your OpenAI API key. Alternatively, you can switch to Ollama, which runs LLM models locally - guide. Documentation You can read the official CocoIndex Documentation for Property Graph Targets here. Data flow to build knowledge graph Add documents as source We will process CocoIndex documentation markdown files (.md, .mdx) from the docs/core directory (markdown files, deployed docs). @cocoindex.flow_def(name="DocsToKG") def docs_to_kg_flow(flow_builder: cocoindex.FlowBuilder, data_scope: cocoindex.DataScope): data_scope["documents"] = flow_builder.add_source( cocoindex.sources.LocalFile(path="../../docs/docs/core", included_patterns=["*.md", "*.mdx"])) Here flow_builder.add_source creates a KTable. filename is the key of the KTable. Add data collectors Add collectors at the root scope: document_node = data_scope.add_collector() entity_relationship = data_scope.add_collector() entity_mention = data_scope.add_collector() document_node collects documents. E.g., core/basics.mdx is a document. entity_relationship collects relationships. E.g., "CocoIndex supports Incremental Processing" indicates a relationship between CocoIndex and Incremental Processing. entity_mention collects mentions of entities in a document. E.g., core/basics.mdx mentions CocoIndex and Incremental Processing. Process each document and extract summary Define a DocumentSummary data class to extract the summary of a document. @dataclasses.dataclass class DocumentSummary: title: str summary: str Within the flow, use cocoindex.functions.ExtractByLlm for structured output. with data_scope["documents"].row() as doc: doc["summary"] = doc["content"].transform( cocoindex.functions.ExtractByLlm( llm_spec=cocoindex.LlmSpec( api_type=cocoindex.LlmApiType.OPENAI, model="gpt-4o"), output_type=DocumentSummary, instruction="Please summarize the content of the document.")) document_node.collect( filename=doc["filename"], title=doc["summary"]["title"], summary=doc["summary"]["summary"]) doc["summary"] adds a new column to the KTable data_scope["documents"]. Extract relationships from the document using LLM Define a data class to represent relationship for the LLM extraction. @dataclasses.dataclass class Relationship: """ Describe a relationship between two entities. Subject and object should be Core CocoIndex concepts only, should be nouns. For example, `CocoIndex`, `Incremental Processing`, `ETL`, `Data` etc. """ subject: str predicate: str object: str The Data class defines a knowledge graph relationship. We recommend putting detailed instructions in the class-level docstring to help the LLM extract relationships correctly. subject: Represents the entity the statement is about (e.g., 'CocoIndex'). predicate: Describes the type of relationship or property connecting the subject and object (e.g., 'supports'). object: Represents the entity or value that the subject is related to via the predicate (e.g., 'Incremental Processing'). This structure represents facts like "CocoIndex supports Incremental Processing". Its graph representation is: Next, we will use cocoindex.functions.ExtractByLlm to extract the relationships from the document. doc["relationships"] = doc["content"].transform( cocoindex.functions.ExtractByLlm( llm_spec=cocoindex.LlmSpec( api_type=cocoindex.LlmApiType.OPENAI, model="gpt-4o" ), output_type=list[Relationship], instruction=( "Please extract relationships from CocoIndex documents. " "Focus on concepts and ignore examples and code. " ) ) ) doc["relationships"] adds a new field relationships to each document. output_type=list[Relationship] specifies that the output of the transformation is a LTable. Collect relationships with doc["relationships"].row() as relationship: # relationship betwe

CocoIndex makes it easy to build and maintain knowledge graphs with continuous source updates. In this blog, we will process a list of documents (using CocoIndex documentation as an example). We will use LLM to extract relationships between the concepts in each document. We will generate two kinds of relationships:
- Relationships between subjects and objects. E.g., "CocoIndex supports Incremental Processing"
- Mentions of entities in a document. E.g., "core/basics.mdx" mentions
CocoIndexandIncremental Processing.
We are constantly improving, and more features and examples are coming soon.
Stay tuned and follow our progress by starring our GitHub repo.
Prerequisites
- Install PostgreSQL. CocoIndex uses PostgreSQL internally for incremental processing.
- Install Neo4j, a graph database.
- Configure your OpenAI API key. Alternatively, you can switch to Ollama, which runs LLM models locally - guide.
Documentation
You can read the official CocoIndex Documentation for Property Graph Targets here.
Data flow to build knowledge graph
Add documents as source
We will process CocoIndex documentation markdown files (.md, .mdx) from the docs/core directory (markdown files, deployed docs).
@cocoindex.flow_def(name="DocsToKG")
def docs_to_kg_flow(flow_builder: cocoindex.FlowBuilder, data_scope: cocoindex.DataScope):
data_scope["documents"] = flow_builder.add_source(
cocoindex.sources.LocalFile(path="../../docs/docs/core",
included_patterns=["*.md", "*.mdx"]))
Here flow_builder.add_source creates a KTable.
filename is the key of the KTable.

Add data collectors
Add collectors at the root scope:
document_node = data_scope.add_collector()
entity_relationship = data_scope.add_collector()
entity_mention = data_scope.add_collector()
-
document_nodecollects documents. E.g.,core/basics.mdxis a document. -
entity_relationshipcollects relationships. E.g., "CocoIndex supports Incremental Processing" indicates a relationship betweenCocoIndexandIncremental Processing. -
entity_mentioncollects mentions of entities in a document. E.g.,core/basics.mdxmentionsCocoIndexandIncremental Processing.
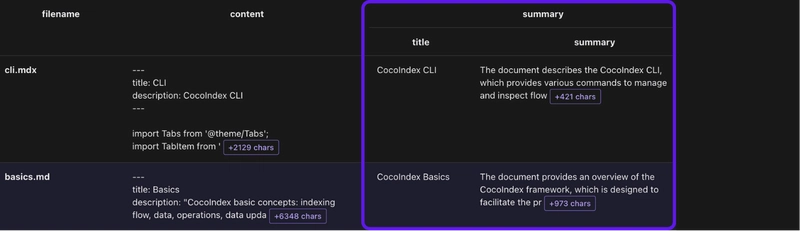
Process each document and extract summary
Define a DocumentSummary data class to extract the summary of a document.
@dataclasses.dataclass
class DocumentSummary:
title: str
summary: str
Within the flow, use cocoindex.functions.ExtractByLlm for structured output.
with data_scope["documents"].row() as doc:
doc["summary"] = doc["content"].transform(
cocoindex.functions.ExtractByLlm(
llm_spec=cocoindex.LlmSpec(
api_type=cocoindex.LlmApiType.OPENAI, model="gpt-4o"),
output_type=DocumentSummary,
instruction="Please summarize the content of the document."))
document_node.collect(
filename=doc["filename"], title=doc["summary"]["title"],
summary=doc["summary"]["summary"])
doc["summary"] adds a new column to the KTable data_scope["documents"].
Extract relationships from the document using LLM
Define a data class to represent relationship for the LLM extraction.
@dataclasses.dataclass
class Relationship:
"""
Describe a relationship between two entities.
Subject and object should be Core CocoIndex concepts only, should be nouns. For example, `CocoIndex`, `Incremental Processing`, `ETL`, `Data` etc.
"""
subject: str
predicate: str
object: str
The Data class defines a knowledge graph relationship. We recommend putting detailed instructions in the class-level docstring to help the LLM extract relationships correctly.
-
subject: Represents the entity the statement is about (e.g., 'CocoIndex'). -
predicate: Describes the type of relationship or property connecting the subject and object (e.g., 'supports'). -
object: Represents the entity or value that the subject is related to via the predicate (e.g., 'Incremental Processing').
This structure represents facts like "CocoIndex supports Incremental Processing". Its graph representation is:

Next, we will use cocoindex.functions.ExtractByLlm to extract the relationships from the document.
doc["relationships"] = doc["content"].transform(
cocoindex.functions.ExtractByLlm(
llm_spec=cocoindex.LlmSpec(
api_type=cocoindex.LlmApiType.OPENAI,
model="gpt-4o"
),
output_type=list[Relationship],
instruction=(
"Please extract relationships from CocoIndex documents. "
"Focus on concepts and ignore examples and code. "
)
)
)
doc["relationships"] adds a new field relationships to each document. output_type=list[Relationship] specifies that the output of the transformation is a LTable.

Collect relationships
with doc["relationships"].row() as relationship:
# relationship between two entities
entity_relationship.collect(
id=cocoindex.GeneratedField.UUID,
subject=relationship["subject"],
object=relationship["object"],
predicate=relationship["predicate"],
)
# mention of an entity in a document, for subject
entity_mention.collect(
id=cocoindex.GeneratedField.UUID, entity=relationship["subject"],
filename=doc["filename"],
)
# mention of an entity in a document, for object
entity_mention.collect(
id=cocoindex.GeneratedField.UUID, entity=relationship["object"],
filename=doc["filename"],
)
-
entity_relationshipcollects relationships between subjects and objects. -
entity_mentioncollects mentions of entities (as subjects or objects) in the document separately. For example,core/basics.mdxhas a sentenceCocoIndex supports Incremental Processing. We want to collect:-
core/basics.mdxmentionsCocoIndex. -
core/basics.mdxmentionsIncremental Processing.
-
Build knowledge graph
Basic concepts
All nodes for Neo4j need two things:
- Label: The type of the node. E.g.,
Document,Entity. - Primary key field: The field that uniquely identifies the node. E.g.,
filenameforDocumentnodes.
CocoIndex uses the primary key field to match the nodes and deduplicate them. If you have multiple nodes with the same primary key, CocoIndex keeps only one of them.

There are two ways to map nodes:
- When you have a collector just for the node, you can directly export it to Neo4j.
- When you have a collector for relationships connecting to the node, you can map nodes from selected fields in the relationship collector. You must declare a node label and primary key field.
Configure Neo4j connection:
conn_spec = cocoindex.add_auth_entry(
"Neo4jConnection",
cocoindex.storages.Neo4jConnection(
uri="bolt://localhost:7687",
user="neo4j",
password="cocoindex",
))
Export Document nodes to Neo4j

document_node.export(
"document_node",
cocoindex.storages.Neo4j(
connection=conn_spec,
mapping=cocoindex.storages.Nodes(label="Document")),
primary_key_fields=["filename"],
)
This exports Neo4j nodes with label Document from the document_node collector.
- It declares Neo4j node label
Document. It specifiesfilenameas the primary key field. - It carries all the fields from
document_nodecollector to Neo4j nodes with labelDocument.
Export RELATIONSHIP and Entity nodes to Neo4j

We don't have explicit collector for Entity nodes.
They are part of the entity_relationship collector and fields are collected during the relationship extraction.
To export them as Neo4j nodes, we need to first declare Entity nodes.
flow_builder.declare(
cocoindex.storages.Neo4jDeclaration(
connection=conn_spec,
nodes_label="Entity",
primary_key_fields=["value"],
)
)
Next, export the entity_relationship to Neo4j.
entity_relationship.export(
"entity_relationship",
cocoindex.storages.Neo4j(
connection=conn_spec,
mapping=cocoindex.storages.Relationships(
rel_type="RELATIONSHIP",
source=cocoindex.storages.NodeFromFields(
label="Entity",
fields=[
cocoindex.storages.TargetFieldMapping(
source="subject", target="value"),
]
),
target=cocoindex.storages.NodeFromFields(
label="Entity",
fields=[
cocoindex.storages.TargetFieldMapping(
source="object", target="value"),
]
),
),
),
primary_key_fields=["id"],
)
)
The cocoindex.storages.Relationships declares how to map relationships in Neo4j.
In a relationship, there's:
- A source node and a target node.
- A relationship connecting the source and target. Note that different relationships may share the same source and target nodes.
NodeFromFields takes the fields from the entity_relationship collector and creates Entity nodes.
Export the entity_mention to Neo4j.

entity_mention.export(
"entity_mention",
cocoindex.storages.Neo4j(
connection=conn_spec,
mapping=cocoindex.storages.Relationships(
rel_type="MENTION",
source=cocoindex.storages.NodesFromFields(
label="Document",
fields=[cocoindex.storages.TargetFieldMapping("filename")],
),
target=cocoindex.storages.NodesFromFields(
label="Entity",
fields=[cocoindex.storages.TargetFieldMapping(
source="entity", target="value")],
),
),
),
primary_key_fields=["id"],
)
Similarly here, we export entity_mention to Neo4j Relationships using cocoindex.storages.Relationships.
It creates relationships by:
- Creating
Documentnodes andEntitynodes from theentity_mentioncollector. - Connecting
Documentnodes andEntitynodes with relationshipMENTION.
Main function
Finally, the main function for the flow initializes the CocoIndex flow and runs it.
@cocoindex.main_fn()
def _run():
pass
if __name__ == "__main__":
load_dotenv(override=True)
_run()
Query and test your index


