


































































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)









































































































































































































































































































































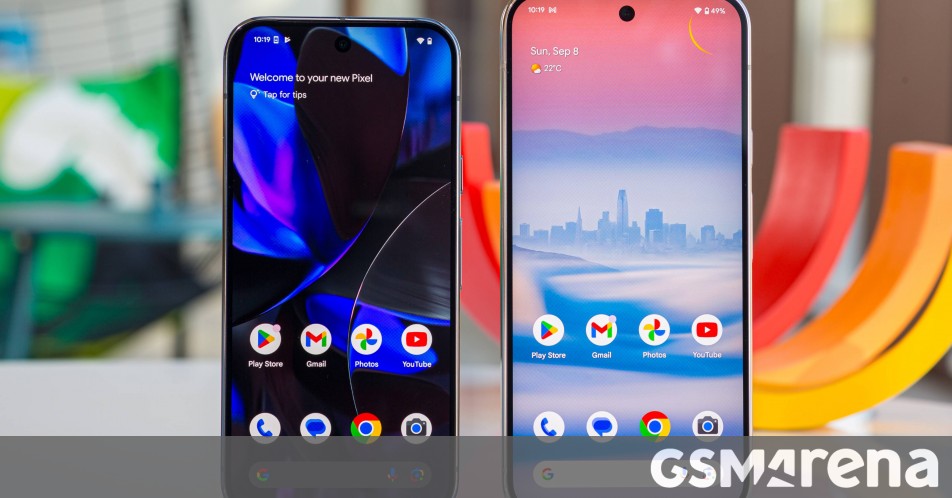

































![Google Home app fixes bug that repeatedly asked to ‘Set up Nest Cam features’ for Nest Hub Max [U]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2022/08/youtube-premium-music-nest-hub-max.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)


















































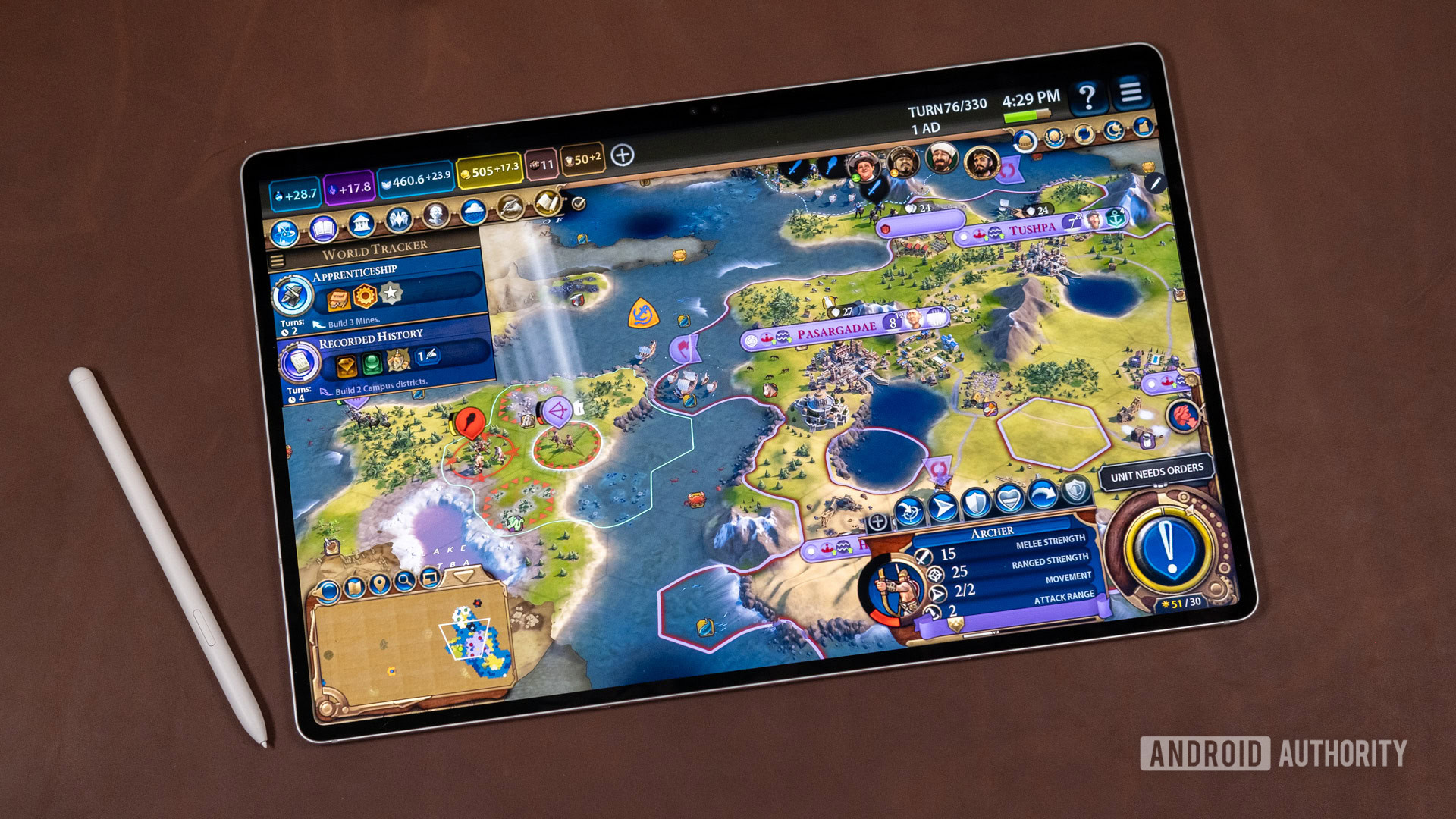
![Epic Games Wins Major Victory as Apple is Ordered to Comply With App Store Anti-Steering Injunction [Updated]](https://images.macrumors.com/t/Z4nU2dRocDnr4NPvf-sGNedmPGA=/2250x/article-new/2022/01/iOS-App-Store-General-Feature-JoeBlue.jpg)






















































Looking for a somewhat efficient algorithm for (<= 100 nodes; <= 16 degree on each node) for solving the DAG canonicalization problem, networkx ok
I'm working with DAG's in my application. These DAGs form a visual language, so anything more complicated than a 10x10 = 100 grid of nodes and degree > 16 is going to be incomprehensible to the human mind as a visual mnemonic i.e. useless. Therefore, I'm on the search for a bounded-degree DAG canonicalization algorithm, where the output is not a graph, but a string (hashable). In addition, the algorithm needs to take into account that I have strings such as A⋉B in my graph, and those can get canonicalized via A->0, B->1 for example. So that if the user passes in another DAG of the exact same form (all operators in strings are the same), up to variable-substitution (A,B are variables), the canonical string hash will map to precisely the first one. In this way I can have a hash table of applicable diagram transformation rules. The alternative is really stupid: foreach rule in my set, check if the user's input matches that rule's input with a graph isomorphism check (and up to variable substitution). Any help appreciated. I'm not liking Nauty as it's not very well documented, and last time I tried canonicalizing with it, the output was not a canonical form! So networkx library can be used (this is in Python). Also, this has to work with multigraphs. Nauty only supports multigraphs if you encode the count of the edges as an integer on a single edge. Networkx has to_nested_tuple, but it does not record anything about the labels, it's literally a tree of nested ()'s, with no other data in the tuple except other eventually empty tuples. So that's a no go. If someone has a networkx-based library out there for canonicalization of a DAG to a string, that would be useful. Here is my attempt: First work with the DAG as an unlabeled graph, forgetting about the labels for a second. Define an adjacency matrix as Aij = k (a non-negative integer) if there are exactly k multigraph edges i->j, where i,j are any of the total of |V| vertices; i,j = 1...|V|. Sort the vertices i by the key deg(i) = sum(k=1..|V|, A_ik + A_ki), i.e. their total in+out degree. Let the sorted vertex list be L = [v(1), .., v(g1),v(g1+1), ..,v(g1+g2), v(g1+g2+1),..,v(g1+g2+g3),....,v(g1+g2+...+gN)] where there are g1 vertices of deg(g1), g2 of deg(g1+g2), .. gN of deg(g1+g2+..+gN). Within each of the like-degree groupings, sort based upon something else... and that's where I'm lost. After the vertices are sorted, somehow sort the edges (which should be easier). Finally put in the canonicalized vertex / edge labels somewhere.

I'm working with DAG's in my application. These DAGs form a visual language, so anything more complicated than a 10x10 = 100 grid of nodes and degree > 16 is going to be incomprehensible to the human mind as a visual mnemonic i.e. useless. Therefore, I'm on the search for a bounded-degree DAG canonicalization algorithm, where the output is not a graph, but a string (hashable).
In addition, the algorithm needs to take into account that I have strings such as A⋉B in my graph, and those can get canonicalized via A->0, B->1 for example. So that if the user passes in another DAG of the exact same form (all operators in strings are the same), up to variable-substitution (A,B are variables), the canonical string hash will map to precisely the first one. In this way I can have a hash table of applicable diagram transformation rules. The alternative is really stupid: foreach rule in my set, check if the user's input matches that rule's input with a graph isomorphism check (and up to variable substitution).
Any help appreciated. I'm not liking Nauty as it's not very well documented, and last time I tried canonicalizing with it, the output was not a canonical form! So networkx library can be used (this is in Python). Also, this has to work with multigraphs. Nauty only supports multigraphs if you encode the count of the edges as an integer on a single edge.
Networkx has to_nested_tuple, but it does not record anything about the labels, it's literally a tree of nested ()'s, with no other data in the tuple except other eventually empty tuples. So that's a no go.
If someone has a networkx-based library out there for canonicalization of a DAG to a string, that would be useful.
Here is my attempt:
- First work with the DAG as an unlabeled graph, forgetting about the labels for a second.
- Define an adjacency matrix as Aij = k (a non-negative integer) if there are exactly k multigraph edges i->j, where i,j are any of the total of |V| vertices; i,j = 1...|V|.
- Sort the vertices i by the key deg(i) = sum(k=1..|V|, A_ik + A_ki), i.e. their total in+out degree.
- Let the sorted vertex list be L = [v(1), .., v(g1),v(g1+1), ..,v(g1+g2), v(g1+g2+1),..,v(g1+g2+g3),....,v(g1+g2+...+gN)]
where there are g1 vertices of deg(g1), g2 of deg(g1+g2), .. gN of deg(g1+g2+..+gN).
Within each of the like-degree groupings, sort based upon something else... and that's where I'm lost.
After the vertices are sorted, somehow sort the edges (which should be easier).
Finally put in the canonicalized vertex / edge labels somewhere.
