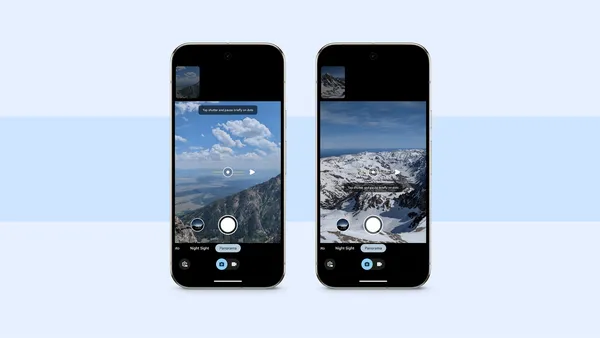
![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)








































































































































































































































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)




































































































![Apple Ships 55 Million iPhones, Claims Second Place in Q1 2025 Smartphone Market [Report]](https://www.iclarified.com/images/news/97185/97185/97185-640.jpg)


































































































How to determine which service keeps the relation to the other?
Suppose I have 3 (example) services (eg seperate microservices in my Docker cluster): Reseller Service - Our code is turned into whitelabel software. This is the service that owns the Reseller related data, like its ID, name, main brand, active modules etc. Creation and updating can only be done via the API to this service Distributor - This owns the data for distributors, like the name and logo Insurance - This owns the data for insurances, like the name and max amount We've now came across the following issue: Not every Reseller has all Distributors or Insurances. We need to config what distributors are active for a Reseller and what Insurances are active for a Reseller. This presents us (afaik) two routes we can take: Reseller Service with a Reseller table and pivot table reseller_distributor with an r_id and d_id. Distributor Service with a Distributor table and pivot table distributor_reseller with an d_id and r_id. There are good arguments to be made for both, how do we make a choice? Pro Distributor at Reseller: You config a Reseller, which is an important object, and you can do that in one location. Con: Now the Reseller service needs to know about all Things (at least their IDs). Con: If you want additional info from the pivot (like active_from) you now need to change the Reseller Service Pro Distributor at Reseller: The Reseller needs to know about a Distributor, Insurance, Example only once, in the pivot column. We're coming up with good arguments for both routes and we dont really think there is a bad solution*, but still we like to apply good practices :) * Apart from the ChatGPT solution: Create a new Microservice which only responsibility would be to store the relations between everything.

Suppose I have 3 (example) services (eg seperate microservices in my Docker cluster):
- Reseller Service - Our code is turned into whitelabel software. This is the service that owns the Reseller related data, like its ID, name, main brand, active modules etc. Creation and updating can only be done via the API to this service
- Distributor - This owns the data for distributors, like the name and logo
- Insurance - This owns the data for insurances, like the name and max amount
We've now came across the following issue: Not every Reseller has all Distributors or Insurances. We need to config what distributors are active for a Reseller and what Insurances are active for a Reseller.
This presents us (afaik) two routes we can take:
- Reseller Service with a
Resellertable and pivot tablereseller_distributorwith anr_idandd_id. - Distributor Service with a
Distributortable and pivot tabledistributor_resellerwith and_idandr_id.
There are good arguments to be made for both, how do we make a choice?
Pro Distributor at Reseller: You config a Reseller, which is an important object, and you can do that in one location.
Con: Now the Reseller service needs to know about all Things (at least their IDs).
Con: If you want additional info from the pivot (like active_from) you now need to change the Reseller Service
Pro Distributor at Reseller: The Reseller needs to know about a Distributor, Insurance, Example only once, in the pivot column.
We're coming up with good arguments for both routes and we dont really think there is a bad solution*, but still we like to apply good practices :)
* Apart from the ChatGPT solution: Create a new Microservice which only responsibility would be to store the relations between everything.