![[The AI Show Episode 155]: The New Jobs AI Will Create, Amazon CEO: AI Will Cut Jobs, Your Brain on ChatGPT, Possible OpenAI-Microsoft Breakup & Veo 3 IP Issues](https://www.marketingaiinstitute.com/hubfs/ep%20155%20cover.png)
































































































































































































![GrandChase tier list of the best characters available [June 2025]](https://media.pocketgamer.com/artwork/na-33057-1637756796/grandchase-ios-android-3rd-anniversary.jpg?#)

































































_peter_kovac_alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)











































































































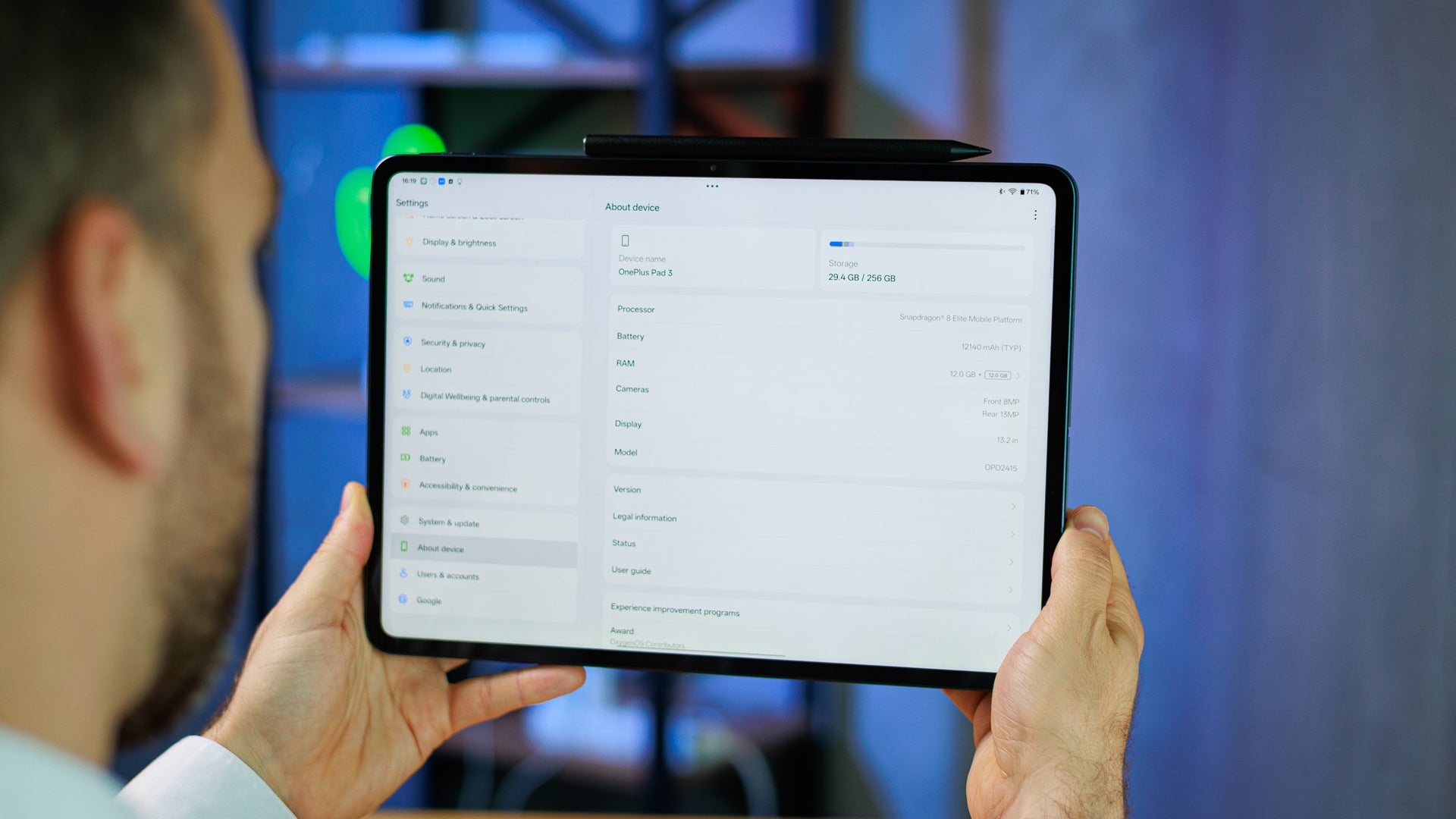
![Apple Considers LX Semicon and LG Innotek Components for iPad OLED Displays [Report]](https://www.iclarified.com/images/news/97699/97699/97699-640.jpg)


![Apple Releases New Beta Firmware for AirPods Pro 2 and AirPods 4 [8A293c]](https://www.iclarified.com/images/news/97704/97704/97704-640.jpg)





















































Big Data Fundamentals: big data tutorial
Mastering Data Skew: A Deep Dive into Partitioning and Rebalancing in Big Data Systems Introduction The relentless growth of data presents a constant engineering challenge: maintaining query performance and pipeline throughput as datasets scale. A common bottleneck isn’t raw compute power, but data skew – uneven distribution of data across partitions. This manifests as some tasks taking orders of magnitude longer than others, crippling parallelism and driving up costs. This post dives deep into understanding, diagnosing, and mitigating data skew, a critical skill for any engineer building production Big Data systems. We’ll focus on techniques applicable across common frameworks like Spark, Flink, and Presto, within modern data lake architectures leveraging formats like Parquet and Iceberg. We’ll assume a context of datasets ranging from terabytes to petabytes, with requirements for sub-second query latency for interactive analytics and high-throughput for streaming ETL. What is Data Skew in Big Data Systems? Data skew occurs when partitioning keys result in an imbalanced distribution of data. Instead of evenly distributing records across all available executors/tasks, a disproportionate number of records land in a small subset. This isn’t simply about uneven file sizes; it’s about the workload being unevenly distributed. At a protocol level, this translates to some tasks needing to process significantly more data, leading to longer execution times and resource contention. The impact is amplified in shuffle-intensive operations like joins, aggregations, and windowing. Effective partitioning is therefore not about minimizing storage costs, but maximizing parallel processing efficiency. Real-World Use Cases Clickstream Analytics: Analyzing user behavior often involves partitioning by user_id. Popular users (celebrities, influencers) will generate significantly more events, creating skew. Financial Transaction Processing: Partitioning by transaction_date can lead to skew during peak trading hours or around major events. IoT Sensor Data: Sensors in critical locations or experiencing failures may generate a disproportionate amount of data, skewing partitions based on sensor_id. Log Analytics: Analyzing application logs partitioned by application_name can be skewed if one application generates significantly more logs than others. CDC (Change Data Capture) Pipelines: Updates to frequently modified tables can create skew when partitioning by primary key during incremental loads. System Design & Architecture Let's consider a typical data pipeline for clickstream analytics using Spark on AWS EMR. graph LR A[Kafka Topic: Click Events] --> B(Spark Streaming Job); B --> C{Iceberg Table: Clickstream Data}; C --> D[Presto/Trino: Interactive Queries]; C --> E[Spark Batch: Feature Engineering]; E --> F[Model Training]; The critical point is the partitioning strategy applied when writing to the Iceberg table. A naive partitioning by user_id will likely result in skew. A better approach is to combine user_id with a hash function to distribute data more evenly. Iceberg’s partition evolution capabilities allow us to change partitioning schemes without rewriting the entire table. For cloud-native deployments, consider using services like AWS Glue for schema discovery and metadata management, and AWS S3 for cost-effective storage. EMR provides the Spark execution environment. Monitoring with CloudWatch and Spark UI is crucial for identifying skew. Performance Tuning & Resource Management Mitigating skew requires a multi-pronged approach. Salting: Append a random number (the "salt") to the skewed key. This effectively creates multiple partitions for the skewed key, distributing the workload. Example (Scala): import org.apache.spark.sql.functions._ val saltCount = 10 val df = df.withColumn("salted_user_id", concat(col("user_id"), lit("_"), rand() * saltCount).cast("string")) Bucketing: Similar to salting, but uses a fixed number of buckets based on a hash of the key. This is more efficient for joins. Adaptive Query Execution (AQE) in Spark: AQE dynamically adjusts query plans based on runtime statistics, including skew detection and dynamic repartitioning. Enable with: spark.sql.adaptive.enabled=true spark.sql.adaptive.skewJoin.enabled=true Increase Parallelism: Increase spark.sql.shuffle.partitions to create more tasks, potentially reducing the impact of skew. However, excessive parallelism can lead to overhead. Start with a value 2-3x the number of cores in your cluster. File Size Compaction: Small files can exacerbate skew. Regularly compact small files into larger ones. Configuration Examples: spark.sql.shuffle.partitions=200 fs.s3a.connection.maximum=1000 (for S3 connections) spark.driver.memory=8g (adjust based on data volume) Failure Modes & Debugging Dat

Mastering Data Skew: A Deep Dive into Partitioning and Rebalancing in Big Data Systems
Introduction
The relentless growth of data presents a constant engineering challenge: maintaining query performance and pipeline throughput as datasets scale. A common bottleneck isn’t raw compute power, but data skew – uneven distribution of data across partitions. This manifests as some tasks taking orders of magnitude longer than others, crippling parallelism and driving up costs. This post dives deep into understanding, diagnosing, and mitigating data skew, a critical skill for any engineer building production Big Data systems. We’ll focus on techniques applicable across common frameworks like Spark, Flink, and Presto, within modern data lake architectures leveraging formats like Parquet and Iceberg. We’ll assume a context of datasets ranging from terabytes to petabytes, with requirements for sub-second query latency for interactive analytics and high-throughput for streaming ETL.
What is Data Skew in Big Data Systems?
Data skew occurs when partitioning keys result in an imbalanced distribution of data. Instead of evenly distributing records across all available executors/tasks, a disproportionate number of records land in a small subset. This isn’t simply about uneven file sizes; it’s about the workload being unevenly distributed. At a protocol level, this translates to some tasks needing to process significantly more data, leading to longer execution times and resource contention. The impact is amplified in shuffle-intensive operations like joins, aggregations, and windowing. Effective partitioning is therefore not about minimizing storage costs, but maximizing parallel processing efficiency.
Real-World Use Cases
-
Clickstream Analytics: Analyzing user behavior often involves partitioning by
user_id. Popular users (celebrities, influencers) will generate significantly more events, creating skew. -
Financial Transaction Processing: Partitioning by
transaction_datecan lead to skew during peak trading hours or around major events. -
IoT Sensor Data: Sensors in critical locations or experiencing failures may generate a disproportionate amount of data, skewing partitions based on
sensor_id. -
Log Analytics: Analyzing application logs partitioned by
application_namecan be skewed if one application generates significantly more logs than others. - CDC (Change Data Capture) Pipelines: Updates to frequently modified tables can create skew when partitioning by primary key during incremental loads.
System Design & Architecture
Let's consider a typical data pipeline for clickstream analytics using Spark on AWS EMR.
graph LR
A[Kafka Topic: Click Events] --> B(Spark Streaming Job);
B --> C{Iceberg Table: Clickstream Data};
C --> D[Presto/Trino: Interactive Queries];
C --> E[Spark Batch: Feature Engineering];
E --> F[Model Training];
The critical point is the partitioning strategy applied when writing to the Iceberg table. A naive partitioning by user_id will likely result in skew. A better approach is to combine user_id with a hash function to distribute data more evenly. Iceberg’s partition evolution capabilities allow us to change partitioning schemes without rewriting the entire table.
For cloud-native deployments, consider using services like AWS Glue for schema discovery and metadata management, and AWS S3 for cost-effective storage. EMR provides the Spark execution environment. Monitoring with CloudWatch and Spark UI is crucial for identifying skew.
Performance Tuning & Resource Management
Mitigating skew requires a multi-pronged approach.
-
Salting: Append a random number (the "salt") to the skewed key. This effectively creates multiple partitions for the skewed key, distributing the workload. Example (Scala):
import org.apache.spark.sql.functions._ val saltCount = 10 val df = df.withColumn("salted_user_id", concat(col("user_id"), lit("_"), rand() * saltCount).cast("string")) Bucketing: Similar to salting, but uses a fixed number of buckets based on a hash of the key. This is more efficient for joins.
-
Adaptive Query Execution (AQE) in Spark: AQE dynamically adjusts query plans based on runtime statistics, including skew detection and dynamic repartitioning. Enable with:
spark.sql.adaptive.enabled=true spark.sql.adaptive.skewJoin.enabled=true Increase Parallelism: Increase
spark.sql.shuffle.partitionsto create more tasks, potentially reducing the impact of skew. However, excessive parallelism can lead to overhead. Start with a value 2-3x the number of cores in your cluster.File Size Compaction: Small files can exacerbate skew. Regularly compact small files into larger ones.
-
Configuration Examples:
-
spark.sql.shuffle.partitions=200 -
fs.s3a.connection.maximum=1000(for S3 connections) -
spark.driver.memory=8g(adjust based on data volume)
-
Failure Modes & Debugging
- Data Skew: Tasks take significantly longer than others. Spark UI shows uneven task durations.
- Out-of-Memory Errors: Tasks processing skewed partitions may run out of memory. Increase executor memory or use AQE to repartition.
- Job Retries: Tasks failing due to OOM errors trigger retries, increasing job duration.
- DAG Crashes: Severe skew can lead to cascading failures and DAG crashes.
Debugging Tools:
- Spark UI: Examine task durations, input sizes, and shuffle read/write sizes.
- Flink Dashboard: Monitor task execution times and resource utilization.
- Datadog/Prometheus: Set up alerts for long-running tasks or high memory usage.
- Query Plans: Analyze query plans to identify potential skew points. Use
EXPLAINin Spark SQL or Presto.
Example Log Snippet (Spark):
23/10/27 10:00:00 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 123)
23/10/27 10:00:05 INFO TaskSetManager: Finished task 1.0 in stage 1.0 (TID 124) - 5 seconds
23/10/27 10:00:10 INFO TaskSetManager: Finished task 2.0 in stage 1.0 (TID 125) - 10 seconds
The significant difference in task completion times indicates skew.
Data Governance & Schema Management
Schema evolution is crucial. If the skewed key changes, you need to adapt your partitioning strategy. Iceberg and Delta Lake provide schema evolution capabilities, but consider the impact on existing data. Metadata catalogs like Hive Metastore or AWS Glue Data Catalog store partitioning information. Schema registries like Confluent Schema Registry ensure data consistency. Data quality checks should validate partition key distributions.
Security and Access Control
Data skew doesn’t directly impact security, but access control policies should be applied consistently across all partitions. Tools like Apache Ranger or AWS Lake Formation can enforce fine-grained access control.
Testing & CI/CD Integration
- Great Expectations: Validate partition key distributions.
- DBT Tests: Test data quality and schema consistency.
- Spark Unit Tests: Test data transformation logic.
- Pipeline Linting: Validate pipeline configurations.
- Staging Environments: Test changes in a staging environment before deploying to production.
- Automated Regression Tests: Run regression tests after each deployment.
Common Pitfalls & Operational Misconceptions
- Ignoring Skew: Assuming parallelism will automatically solve performance issues.
- Over-Partitioning: Creating too many partitions, leading to overhead.
- Static Partitioning: Using a fixed partitioning scheme that doesn’t adapt to changing data distributions.
- Insufficient Executor Memory: Tasks running out of memory due to skewed partitions.
- Lack of Monitoring: Not monitoring task durations and resource utilization.
Example Config Diff (Spark):
Before (no AQE): spark.sql.adaptive.enabled=false
After (AQE enabled): spark.sql.adaptive.enabled=true
Enterprise Patterns & Best Practices
- Data Lakehouse: Combine the benefits of data lakes and data warehouses.
- Batch vs. Streaming: Choose the appropriate processing paradigm based on latency requirements.
- File Format: Parquet and ORC are column-oriented formats optimized for analytical queries.
- Storage Tiering: Use different storage tiers (e.g., S3 Standard, S3 Glacier) based on data access frequency.
- Workflow Orchestration: Use Airflow or Dagster to manage complex data pipelines.
Conclusion
Addressing data skew is paramount for building reliable, scalable Big Data infrastructure. Understanding the root causes, employing appropriate mitigation techniques, and implementing robust monitoring are essential. Next steps include benchmarking different partitioning strategies, introducing schema enforcement, and migrating to more efficient file formats like Apache Iceberg. Continuous monitoring and adaptation are key to maintaining optimal performance as data volumes and distributions evolve.