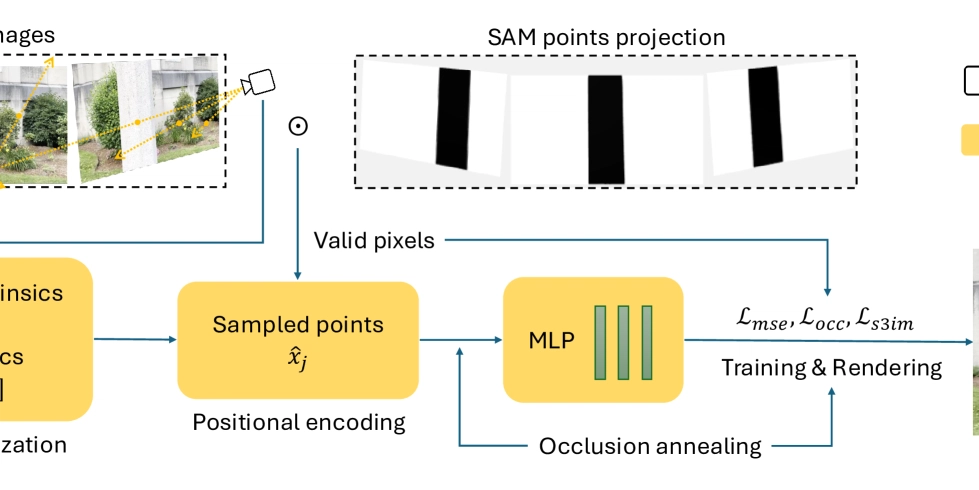
![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)











































































































































































































































































_Aleksey_Funtap_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_Sergey_Tarasov_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)








































































































![Apple Foldable iPhone to Feature New Display Tech, 19% Thinner Panel [Rumor]](https://www.iclarified.com/images/news/97271/97271/97271-640.jpg)
![Apple Developing New Chips for Smart Glasses, Macs, AI Servers [Report]](https://www.iclarified.com/images/news/97269/97269/97269-640.jpg)
![Apple Shares New Mother's Day Ad: 'A Gift for Mom' [Video]](https://www.iclarified.com/images/news/97267/97267/97267-640.jpg)
![Apple Shares Official Trailer for 'Stick' Starring Owen Wilson [Video]](https://www.iclarified.com/images/news/97264/97264/97264-640.jpg)































































































Amazon S3: Your Ultimate Guide to Infinite, Secure, and Cost-Effective Cloud Object Storage
Intro: The Never-Ending Quest for "More Space!" Remember that old external hard drive you bought, thinking, "This will last me forever!"? Or the frantic "disk space low" warnings that send you scrambling to delete precious files? We've all been there. In the digital age, data is exploding – from your cat photos and application logs to massive datasets for machine learning and critical business backups. The traditional ways of storing this data just don't scale efficiently or cost-effectively. What if you had a storage solution that was virtually infinite, incredibly durable, accessible from anywhere, and could adapt its cost based on how you use your data? That's the promise of cloud object storage, and Amazon S3 is the undisputed king of this domain. Why It Matters: The Backbone of the Modern Cloud Amazon S3 isn't just "storage"; it's a foundational building block for a vast array of modern applications and cloud architectures. Scalability: Need to store petabytes? S3 handles it without you even blinking. Durability: S3 is designed for 99.999999999% (eleven 9s!) of durability, meaning your data is incredibly safe from loss. Availability: It boasts high availability, ensuring your data is accessible when you need it. Cost-Effectiveness: Pay only for what you use, with various storage tiers to optimize costs. Integration: It seamlessly integrates with almost every other AWS service and a massive ecosystem of third-party tools. From hosting static websites and backing up databases to powering big data analytics and serving content for global applications, S3 is the silent workhorse making it all possible. Understanding S3 is fundamental to building robust, scalable, and cost-efficient solutions on AWS. The Concept in Simple Terms: S3 as Your Universal Digital Locker System Imagine a global network of super-secure, infinitely expandable locker rooms. Buckets: Each "locker room" is an S3 Bucket. You give it a unique name (globally unique, like a website domain). This is your top-level container. Objects: Inside your bucket, you store your files, which S3 calls Objects. An object isn't just the file data itself; it also includes metadata (data about your data, like last modified date, content type, etc.) and a unique Key (its name or path within the bucket, like images/landscapes/my-vacation.jpg). Infinite Space & Keys: You can have virtually unlimited objects in a bucket, and each object can be up to 5 Terabytes in size. You get an unlimited number of "keys" to access your specific objects. Accessibility: You can access your "lockers" from anywhere with an internet connection, provided you have the right permissions (your "locker key"). This "digital locker system" is designed to be incredibly resilient. AWS replicates your data across multiple physical facilities within a region, so even if one facility has an issue, your data remains safe and accessible. Deeper Dive: Unpacking S3's Power Features Alright, let's open up this digital locker and see what makes S3 so powerful. 1. S3 Use Cases: More Than Just File Storage The versatility of S3 is astounding. Here are just a few common ways it's used: Backup and Restore: A primary target for database dumps, application backups, and disaster recovery. Archive: Long-term, low-cost storage for data that isn't frequently accessed but must be retained (e.g., compliance records). Static Website Hosting: Host entire HTML, CSS, JavaScript, and image-based websites directly from an S3 bucket. Super cheap, super scalable! Data Lakes: Store massive amounts of raw data in various formats for big data analytics, machine learning, and AI. Content Storage and Delivery: Serve images, videos, and other assets for web and mobile applications, often paired with Amazon CloudFront (a CDN) for global low-latency access. Application Data: Store user-generated content, application logs, and other dynamic data. Software Delivery: Distribute software packages and updates. 2. Securing Your Treasure: IAM Policies vs. Bucket Policies Security in S3 is paramount. You control access using policies. There are two main types: IAM (Identity and Access Management) Policies: Analogy: Think of IAM policies as employee badges. They define who (users, groups, roles) can perform what actions (e.g., s3:GetObject, s3:PutObject, s3:ListBucket) on which AWS resources (including specific S3 buckets or objects). These are attached to users, groups, or roles. Focus: User-centric. "What can this user/role do across AWS?" Bucket Policies: Analogy: Think of bucket policies as rules posted on the locker room door. They define who (principals, which can be AWS accounts, users, services) has what permissions (actions) for this specific bucket and the objects within it. These are JSON documents attached directly to an S3 bucket. Focus: Resource-centric. "What can be done with

Intro: The Never-Ending Quest for "More Space!"
Remember that old external hard drive you bought, thinking, "This will last me forever!"? Or the frantic "disk space low" warnings that send you scrambling to delete precious files? We've all been there. In the digital age, data is exploding – from your cat photos and application logs to massive datasets for machine learning and critical business backups. The traditional ways of storing this data just don't scale efficiently or cost-effectively.
What if you had a storage solution that was virtually infinite, incredibly durable, accessible from anywhere, and could adapt its cost based on how you use your data? That's the promise of cloud object storage, and Amazon S3 is the undisputed king of this domain.
Why It Matters: The Backbone of the Modern Cloud
Amazon S3 isn't just "storage"; it's a foundational building block for a vast array of modern applications and cloud architectures.
- Scalability: Need to store petabytes? S3 handles it without you even blinking.
- Durability: S3 is designed for 99.999999999% (eleven 9s!) of durability, meaning your data is incredibly safe from loss.
- Availability: It boasts high availability, ensuring your data is accessible when you need it.
- Cost-Effectiveness: Pay only for what you use, with various storage tiers to optimize costs.
- Integration: It seamlessly integrates with almost every other AWS service and a massive ecosystem of third-party tools.
From hosting static websites and backing up databases to powering big data analytics and serving content for global applications, S3 is the silent workhorse making it all possible. Understanding S3 is fundamental to building robust, scalable, and cost-efficient solutions on AWS.
The Concept in Simple Terms: S3 as Your Universal Digital Locker System
Imagine a global network of super-secure, infinitely expandable locker rooms.
- Buckets: Each "locker room" is an S3 Bucket. You give it a unique name (globally unique, like a website domain). This is your top-level container.
- Objects: Inside your bucket, you store your files, which S3 calls Objects. An object isn't just the file data itself; it also includes metadata (data about your data, like last modified date, content type, etc.) and a unique Key (its name or path within the bucket, like
images/landscapes/my-vacation.jpg). - Infinite Space & Keys: You can have virtually unlimited objects in a bucket, and each object can be up to 5 Terabytes in size. You get an unlimited number of "keys" to access your specific objects.
- Accessibility: You can access your "lockers" from anywhere with an internet connection, provided you have the right permissions (your "locker key").
This "digital locker system" is designed to be incredibly resilient. AWS replicates your data across multiple physical facilities within a region, so even if one facility has an issue, your data remains safe and accessible.

Deeper Dive: Unpacking S3's Power Features
Alright, let's open up this digital locker and see what makes S3 so powerful.
1. S3 Use Cases: More Than Just File Storage
The versatility of S3 is astounding. Here are just a few common ways it's used:
- Backup and Restore: A primary target for database dumps, application backups, and disaster recovery.
- Archive: Long-term, low-cost storage for data that isn't frequently accessed but must be retained (e.g., compliance records).
- Static Website Hosting: Host entire HTML, CSS, JavaScript, and image-based websites directly from an S3 bucket. Super cheap, super scalable!
- Data Lakes: Store massive amounts of raw data in various formats for big data analytics, machine learning, and AI.
- Content Storage and Delivery: Serve images, videos, and other assets for web and mobile applications, often paired with Amazon CloudFront (a CDN) for global low-latency access.
- Application Data: Store user-generated content, application logs, and other dynamic data.
- Software Delivery: Distribute software packages and updates.
2. Securing Your Treasure: IAM Policies vs. Bucket Policies
Security in S3 is paramount. You control access using policies. There are two main types:
-
IAM (Identity and Access Management) Policies:
- Analogy: Think of IAM policies as employee badges. They define who (users, groups, roles) can perform what actions (e.g.,
s3:GetObject,s3:PutObject,s3:ListBucket) on which AWS resources (including specific S3 buckets or objects). - These are attached to users, groups, or roles.
- Focus: User-centric. "What can this user/role do across AWS?"
- Analogy: Think of IAM policies as employee badges. They define who (users, groups, roles) can perform what actions (e.g.,
-
Bucket Policies:
- Analogy: Think of bucket policies as rules posted on the locker room door. They define who (principals, which can be AWS accounts, users, services) has what permissions (actions) for this specific bucket and the objects within it.
- These are JSON documents attached directly to an S3 bucket.
- Focus: Resource-centric. "What can be done with this bucket?"
Key Takeaway: Both IAM and bucket policies can grant or deny access. AWS evaluates all applicable policies. An explicit Deny always overrides an Allow. It's common to use both: IAM policies for general permissions for your users/roles, and bucket policies for specific cross-account access or to set broad rules for a bucket (like making objects publicly readable for a website).
Example Sketch (Conceptual - not runnable without context):
A simple bucket policy snippet to make all objects in a bucket publicly readable (use with extreme caution!):
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "PublicReadGetObject",
"Effect": "Allow",
"Principal": "*", // Everyone
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::YOUR-BUCKET-NAME/*" // All objects in bucket
}
]
}
Remember: Since April 2023, new S3 buckets have "Block Public Access" enabled by default, which is a great security posture. You'd need to disable specific BPA settings to make a bucket policy like the one above effective.
3. S3 Encryption: Keeping Your Data Private
S3 offers multiple ways to encrypt your data, both in transit (as it travels to/from S3) and at rest (while stored in S3).
- Encryption in Transit: Achieved using HTTPS (SSL/TLS) for all S3 API endpoints. Always use
https://! - Encryption at Rest:
- SSE-S3 (Server-Side Encryption with Amazon S3-Managed Keys):
- S3 encrypts your objects using AES-256 before saving them and decrypts them when you download them.
- Amazon manages the encryption keys.
- Simplest option: just tell S3 to encrypt.
- SSE-KMS (Server-Side Encryption with AWS Key Management Service):
- Similar to SSE-S3, but you use keys managed in AWS KMS.
- This gives you more control:
- Create and manage customer master keys (CMKs).
- Define usage policies for the keys.
- Audit key usage via CloudTrail.
- Often required for compliance or stricter security controls.
- SSE-C (Server-Side Encryption with Customer-Provided Keys):
- You manage the encryption keys. When you upload an object, you provide S3 with your encryption key. S3 uses it to encrypt the object and then discards the key.
- When you download the object, you must provide the same key.
- Responsibility for key management (and risk of loss) is entirely yours.
- Client-Side Encryption:
- You encrypt your data before sending it to S3.
- You manage the encryption process and the keys entirely.
- S3 stores the data as an encrypted blob, unaware of its contents.
- Maximum control, but also maximum responsibility.
- SSE-S3 (Server-Side Encryption with Amazon S3-Managed Keys):
Pro Tip: For most use cases, SSE-S3 is a great default. If you need auditable key usage or centralized key management, SSE-KMS is the way to go.
4. Versioning: Your "Oops!" Button
Ever accidentally overwritten or deleted a critical file? S3 Versioning is your savior!
- When enabled on a bucket, S3 keeps multiple versions of an object every time you overwrite or delete it.
- Overwriting an object: Creates a new version, the old one becomes a non-current version.
- Deleting an object: Doesn't actually delete it (initially). Instead, S3 inserts a "delete marker" for that object, which becomes the current version. The previous actual versions are still there as non-current versions.
- You can retrieve, restore, or permanently delete any previous version.
- Lifecycle: A crucial companion to Versioning, as old versions still incur storage costs. Lifecycle policies can be set to expire or transition non-current versions to cheaper storage.
Why enable it? Protects against accidental deletions and overwrites, allows for easy rollback. Highly recommended for most buckets.

5. S3 Storage Classes: Matching Cost to Access Patterns
Not all data is created equal. Some data you access constantly ("hot"), some rarely ("cold"). S3 offers a range of storage classes to help you optimize costs based on these access patterns:
- S3 Standard:
- Analogy: Your primary, easy-to-reach filing cabinet.
- For frequently accessed data.
- Low latency and high throughput.
- Highest storage cost, lowest access cost (among frequent access tiers).
- Default storage class.
- S3 Intelligent-Tiering:
- Analogy: A smart filing cabinet that automatically moves files between a frequently accessed shelf and a less-frequently accessed (cheaper) shelf without you doing anything.
- Automatically moves data to the most cost-effective access tier based on changing access patterns.
- No retrieval fees, no operational overhead.
- Ideal for data with unknown or changing access patterns. Small monthly object monitoring and automation fee.
- S3 Standard-Infrequent Access (S3 Standard-IA):
- Analogy: Your secondary filing cabinet for important documents you don't need daily, but must be quickly accessible when needed.
- For data accessed less frequently, but requires rapid access when needed.
- Lower storage cost than S3 Standard, but charges a per-GB retrieval fee.
- Minimum storage duration and object size charges apply.
- S3 One Zone-Infrequent Access (S3 One Zone-IA):
- Analogy: Similar to Standard-IA, but stored in a single Availability Zone (AZ).
- Even lower storage cost than S3 Standard-IA.
- Data is not resilient to the physical loss of an AZ.
- Good for easily reproducible data or data that's also stored elsewhere.
- S3 Glacier Instant Retrieval:
- Analogy: Your archive box that's still in the office, quickly retrievable in minutes.
- For long-lived archive data that needs immediate (millisecond) access, like medical images or news media assets.
- Storage cost comparable to S3 Glacier Flexible Retrieval, but with much faster access. Higher retrieval cost than Flexible Retrieval.
- S3 Glacier Flexible Retrieval (formerly S3 Glacier):
- Analogy: Your off-site archive storage. Retrievals take time (minutes to hours).
- For long-term archival where retrieval times of minutes or hours are acceptable.
- Very low storage cost.
- Offers expedited (1-5 mins), standard (3-5 hrs), and bulk (5-12 hrs) retrieval options, with varying costs.
- S3 Glacier Deep Archive:
- Analogy: Your super-deep, ultra-secure vault for data you almost never expect to access.
- AWS's lowest-cost storage.
- For long-term retention (7-10+ years) of data that is rarely accessed.
- Retrieval time within 12 hours (standard) or 48 hours (bulk).
Key Takeaway: Choosing the right storage class is critical for cost optimization. Don't pay S3 Standard prices for data you touch once a year!
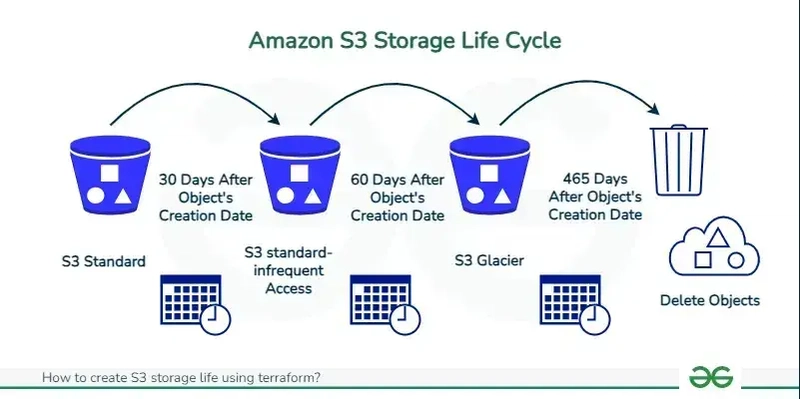
6. Automate Tier Transition with Object Lifecycle Management
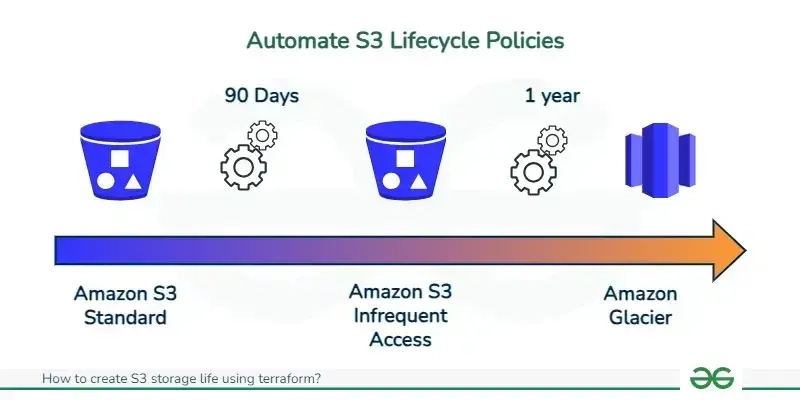
Manually moving objects between storage classes would be a nightmare. That's where S3 Lifecycle Policies come in.
- You define rules that automate the transition of objects to different storage classes or their expiration/deletion.
- Rules can be based on:
- Object age (e.g., move objects older than 30 days from Standard to Standard-IA).
- Object prefix (e.g., apply rules only to objects in the
logs/folder). - Object tags.
- Number of newer versions (for versioned buckets).
- Common Lifecycle Strategy:
- Upload: to S3 Standard (or Intelligent-Tiering).
- After 30-90 days: Transition to S3 Standard-IA (if access becomes infrequent).
- After 180 days - 1 year: Transition to S3 Glacier Flexible Retrieval (for long-term archive).
- After 7-10 years (or compliance period): Transition to S3 Glacier Deep Archive or Expire (delete).
- For versioned buckets, you can also set rules to transition or expire non-current (old) versions.
Example Lifecycle Rule (Conceptual JSON):
{
"Rules": [
{
"ID": "MoveOldLogsToGlacier",
"Status": "Enabled",
"Filter": {
"Prefix": "logs/"
},
"Transitions": [
{
"Days": 90,
"StorageClass": "GLACIER" // Could be GLACIER_IR, STANDARD_IA etc.
}
],
"Expiration": {
"Days": 3650 // Delete after 10 years
},
"NoncurrentVersionTransitions": [
{
"NoncurrentDays": 30,
"StorageClass": "STANDARD_IA"
}
],
"NoncurrentVersionExpiration": {
"NoncurrentDays": 60
}
}
]
}
Lifecycle management is a powerful tool for balancing performance, accessibility, and cost.
Practical Example: Hosting a Simple Static Website
Let's say you're a developer and want to quickly host a portfolio website (HTML, CSS, JS, images).
-
Create a Bucket:
-
Go to the S3 console or use the AWS CLI:
aws s3 mb s3://your-unique-portfolio-site-name --region your-aws-region # Example: aws s3 mb s3://my-awesome-portfolio-2024 --region us-east-1
-
* **Important:** For website hosting, your bucket name often needs to match your domain name (e.g., `www.example.com`).
-
Upload Your Website Files:
-
You can drag-and-drop in the console or use the CLI:
aws s3 sync . s3://your-unique-portfolio-site-name --delete # The '.' means current directory. '--delete' removes files from S3 # that are no longer in your local directory.
-
-
Enable Static Website Hosting:
- In the bucket properties in the S3 console, find "Static website hosting."
- Enable it, and specify your
index.html(entry point) and optionally anerror.htmldocument. - Note the Endpoint URL S3 provides. This is your website's URL.
-
Set Public Access (Bucket Policy):
- Since April 2023, new buckets have "Block Public Access" (BPA) settings enabled by default. For a public website, you'll need to:
- Edit BPA settings for the bucket and uncheck "Block all public access" and specifically ensure "Block public access to buckets and objects granted through new public bucket or access point policies" and "Block public and cross-account access to buckets and objects through any public bucket or access point policies" are unchecked if you're applying a public bucket policy. Careful here, understand the implications!
-
Add a bucket policy to allow public read access to objects:
{ "Version": "2012-10-17", "Statement": [ { "Sid": "PublicReadGetObject", "Effect": "Allow", "Principal": "*", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::your-unique-portfolio-site-name/*" } ] }
- Since April 2023, new buckets have "Block Public Access" (BPA) settings enabled by default. For a public website, you'll need to:
Test: Access the Endpoint URL in your browser. Voila! Your static site is live.
(Optional but Recommended): Use Amazon CloudFront in front of your S3 website for HTTPS, custom domain, and global caching/performance.
Common Mistakes or Misunderstandings
- Accidentally Public Buckets: Historically, a major source of data breaches. AWS has significantly improved defaults (Block Public Access), but misconfigurations are still possible. Always double-check your bucket policies and BPA settings.
- Not Enabling Versioning: Losing data due to accidental overwrite/delete. Enable versioning on important buckets.
- Choosing the Wrong Storage Class: Using S3 Standard for archive data (expensive) or Glacier for frequently accessed data (slow/costly retrieval). Analyze access patterns!
- Forgetting Lifecycle Policies for Versioned Buckets: Old versions accumulate and cost money. Configure lifecycle rules to manage non-current versions.
- IAM vs. Bucket Policy Confusion: Understanding when to use which, and how they interact, is key to proper S3 security.
- Hotspotting / Performance Limits: While S3 scales massively, extremely high request rates to a single prefix (folder path) could theoretically hit limits. S3 has gotten much better at auto-partitioning. For most, this isn't an issue. If you anticipate extreme loads on specific prefixes, consult AWS best practices on prefix naming for performance.
- Case Sensitivity of Object Keys:
MyFile.jpgandmyfile.jpgare different objects in S3. This can trip up people used to case-insensitive file systems.
Pro Tips & Hidden Features
- S3 Select & Glacier Select: Query data within an object (CSV, JSON, Parquet) using SQL-like statements without downloading the entire file. Incredibly useful for filtering large datasets.
- Cross-Region Replication (CRR) & Same-Region Replication (SRR): Automatically replicate objects to another bucket in a different AWS Region (CRR for disaster recovery, geographic proximity) or the same Region (SRR for log aggregation, production/test account sync).
- Requester Pays Buckets: The requester (downloader) pays for data transfer costs, not the bucket owner. Useful for sharing large datasets publicly without incurring massive egress fees.
- S3 Inventory: Get a scheduled CSV, ORC, or Parquet file listing all your objects and their metadata. Great for auditing, analysis, and feeding into other data processing workflows.
- S3 Object Lock: Implement Write-Once-Read-Many (WORM) storage. Objects can be locked for a specified retention period (Governance mode or Compliance mode) to prevent deletion or modification, helping meet regulatory requirements.
- S3 Batch Operations: Perform large-scale batch operations on S3 objects, like copying objects, invoking Lambda functions, or restoring from Glacier, with a single request.
- S3 Storage Lens: Get organization-wide visibility into your object storage usage and activity trends. Helps identify cost-saving opportunities and data protection best practices.
- AWS CLI S3 High-Level Commands (
aws s3 ...vsaws s3api ...):- The
aws s3commands (likesync,cp,mv,rm) are high-level, user-friendly, and performant (often using multipart uploads automatically). - The
aws s3apicommands map directly to the S3 REST API, giving you granular control over every parameter. Use these for more advanced or specific operations not covered by the high-level commands.
- The
Final Thoughts + Call to Action
Amazon S3 is far more than just a place to dump files. It's a sophisticated, secure, and incredibly versatile service that forms the storage foundation for countless applications worldwide. By understanding its core concepts, security mechanisms, storage classes, and lifecycle management, you can build more resilient, scalable, and cost-effective solutions.
The best way to learn is by doing!
- Create a free AWS account if you don't have one.
- Try creating a bucket and uploading a few files.
- Experiment with static website hosting.
- Set up a simple lifecycle policy to move test files to Standard-IA after a day.
- Explore the S3 console – it's quite intuitive for many basic operations.
What are your favorite S3 use cases or pro tips? Did this guide help clarify anything for you? Share your thoughts and questions in the comments below!