














































































































































































![[The AI Show Episode 148]: Microsoft’s Quiet AI Layoffs, US Copyright Office’s Bombshell AI Guidance, 2025 State of Marketing AI Report, and OpenAI Codex](https://www.marketingaiinstitute.com/hubfs/ep%20148%20cover%20%281%29.png)


![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)






























































































































































































































![Borderlands 4 Boss Says 'A Real Fan' Will Pay $80 For Games [Update]](https://i.kinja-img.com/image/upload/c_fill,h_675,pg_1,q_80,w_1200/086e4654c281e40d12b833591d2c6fdc.jpg)










































_Olekcii_Mach_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)




























































































![Nomad levels up its best-selling charger with new 100W slim adapter [Hands-on]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/05/100w-FI.jpg.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)



![Google just showed off Android Auto’s upcoming light theme [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/05/android-auto-light-theme-documentation-2.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)











![Apple Accelerates Smart Glasses for 2026, Cancels Watch With Camera [Report]](https://www.iclarified.com/images/news/97408/97408/97408-640.jpg)
![Jony Ive and OpenAI Working on AI Device With No Screen [Kuo]](https://www.iclarified.com/images/news/97401/97401/97401-640.jpg)

![Anthropic Unveils Claude 4 Models That Could Power Apple Xcode AI Assistant [Video]](https://www.iclarified.com/images/news/97407/97407/97407-640.jpg)






































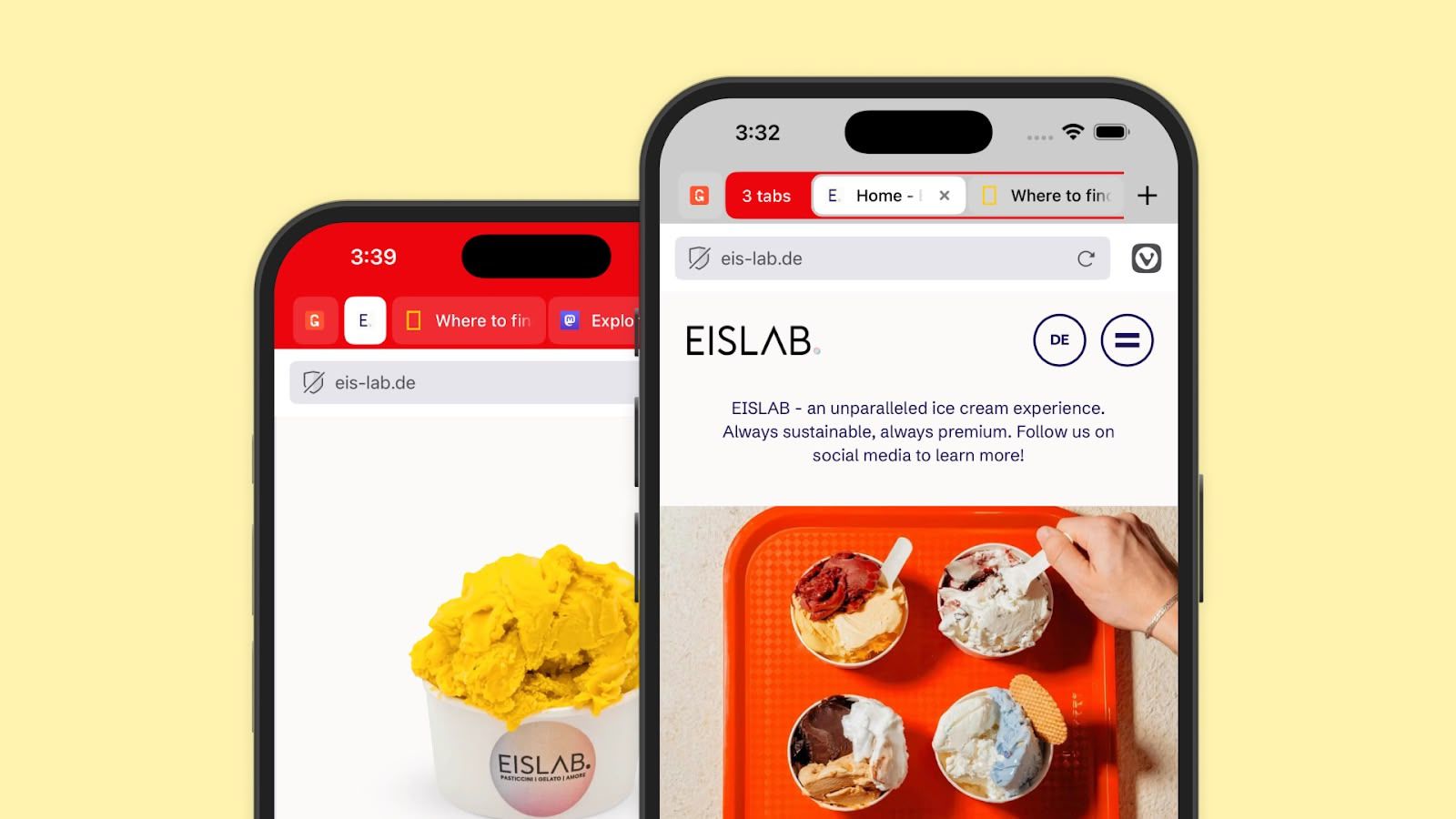




















After GPT-4o backlash, researchers benchmark models on moral endorsement—Find sycophancy persists across the board
A new benchmark can test how much LLMs become sycophants, and found that GPT-4o was the most sycophantic of the models tested.


A new benchmark can test how much LLMs become sycophants, and found that GPT-4o was the most sycophantic of the models tested.Read More


