![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)

































































































































![Ditching a Microsoft Job to Enter Startup Purgatory with Lonewolf Engineer Sam Crombie [Podcast #171]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746753508177/0cd57f66-fdb0-4972-b285-1443a7db39fc.png?#)




























































































































































































































-xl.jpg)

























![Beats Studio Buds + On Sale for $99.95 [Lowest Price Ever]](https://www.iclarified.com/images/news/96983/96983/96983-640.jpg)

![New iPad 11 (A16) On Sale for Just $277.78! [Lowest Price Ever]](https://www.iclarified.com/images/news/97273/97273/97273-640.jpg)






































![Apple's 11th Gen iPad Drops to New Low Price of $277.78 on Amazon [Updated]](https://images.macrumors.com/t/yQCVe42SNCzUyF04yj1XYLHG5FM=/2500x/article-new/2025/03/11th-gen-ipad-orange.jpeg)



![[Exclusive] Infinix GT DynaVue: a Prototype that could change everything!](https://www.gizchina.com/wp-content/uploads/images/2025/05/Screen-Shot-2025-05-10-at-16.07.40-PM-copy.png)




![T-Mobile discontinues a free number feature but a paid alternative exists [UPDATED]](https://m-cdn.phonearena.com/images/article/170235-two/T-Mobile-discontinues-a-free-number-feature-but-a-paid-alternative-exists-UPDATED.jpg?#)














































A Multi-Agent Framework for Enhanced Large Language Model Safety and Governance: The LLM Council
Large Language Models (LLMs) are revolutionizing countless fields with their advanced capabilities. However, their widespread adoption brings to the forefront significant challenges related to safety, ethics, and reliability. This post outlines a conceptual framework, The LLM Council, designed to address these concerns. This framework is not derived from a single research paper but rather integrates and builds upon various research directions highlighted in studies concerning LLM bias, hallucination, toxicity, multi-agent systems, and AI governance—themes well-represented in current AI safety and ethics research. The Core Challenges LLMs Face The journey with LLMs is marked by several well-documented hurdles: Bias Propagation: LLMs are trained on vast datasets, and they can unfortunately learn and perpetuate societal biases present in this data. This is a key concern explored in research on understanding and mitigating bias in LLMs and bias inheritance. LLM Hallucinations: These models can generate information that is plausible-sounding but incorrect or nonsensical, often stated with high confidence. Research is actively exploring types, causes, and solutions for LLM hallucinations, including methods like smoothed knowledge distillation and Retrieval Augmented Generation (RAG), though RAG itself can have hallucination issues. Toxic and Harmful Content: Without robust safeguards, LLMs risk generating offensive, inappropriate, or harmful outputs. This necessitates research into evaluating toxicity and combating toxic language, including implementing LLM guardrails and safety-aware fine-tuning. Misinformation and Factuality: The ease with which LLMs generate text raises concerns about the spread of LLM-generated fake news. This has spurred research into automated fact-checking using LLMs and evaluating if LLMs can catch their own lies. Introducing the LLM Council: A Collaborative, Research-Informed Approach To address these multifaceted challenges, we propose The LLM Council – a conceptual multi-agent system. This idea draws inspiration from research into Multi-Agent Systems and Ensemble Learning for Large Language Models, where multiple specialized AI agents collaborate to achieve a common goal, offering more robust and reliable outcomes than a single monolithic model. The aim is to create layers of scrutiny and specialized expertise for LLM-generated content. How The LLM Council Could Work: Drawing on Research Insights The LLM Council would ideally consist of several specialized LLM agents, each leveraging findings from distinct research areas: The Bias Auditor Agent: Function: Scrutinizes outputs for biases related to gender, race, age, and other characteristics. Research Basis: Leverages techniques discussed in detecting and mitigating bias in LLMs through methods like knowledge graph-augmented training and understanding bias inheritance in downstream tasks. The Reality Checker Agent (Anti-Hallucination Unit): Function: Cross-references claims against verified knowledge bases, checks for internal consistency, and flags potential hallucinations. Research Basis: Implements strategies from research on reducing hallucinations, potentially using techniques like fact-checking processes and approaches to mitigate hallucinations via dual processes of fast and slow thinking or smoothed knowledge distillation. The Ethics & Safety Guardian Agent: Function: Acts as a dynamic content filter against toxic, unethical, or harmful content. Research Basis: Employs safety-aware fine-tuning, implements LLM guardrails, and utilizes filtering techniques like HAP filtering against harmful content, as explored in research on responsible LLMs and safety standards. The Misinformation Detective Agent: Function: Evaluates the authenticity of information, identifies patterns typical of fake news, and assesses source reliability. Research Basis: Based on advancements in automated fact-checking with Large Language Models and studies on LLM-generated fake news. The Oversight Coordinator & Ensemble Agent: Function: Manages the workflow between agents, aggregates their findings, and potentially employs ensemble methods to synthesize the most reliable and safe output. It could facilitate a debate-feedback mechanism among agents. Research Basis: Draws from ensemble learning for LLMs and the architectural principles of multi-agent collaboration and trustworthy multi-LLM networks. Grounded in a Research Ecosystem The "LLM Council" concept is a way to operationalize the diverse safety and governance strategies found within the broader AI research landscape. It acknowledges that no single solution is likely sufficient. Instead, it points towards a future where: Open Source LLMs (like LLaMa variants) and Proprietary LLMs (such as GPT series or Claude models) could potentially contribute specialized agents to such a council, leveraging the unique streng
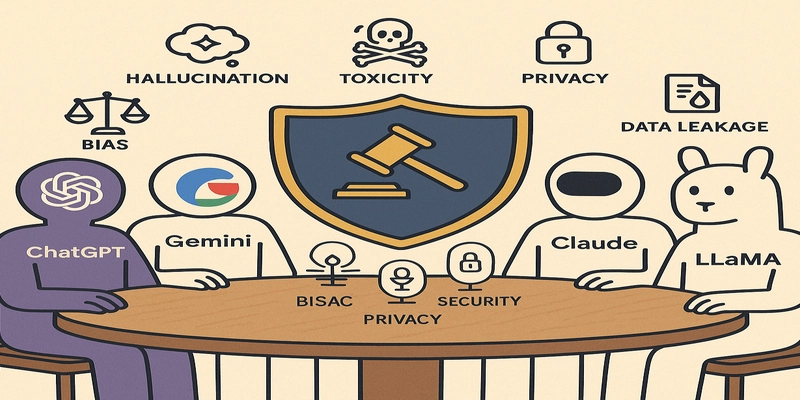
Large Language Models (LLMs) are revolutionizing countless fields with their advanced capabilities. However, their widespread adoption brings to the forefront significant challenges related to safety, ethics, and reliability. This post outlines a conceptual framework, The LLM Council, designed to address these concerns. This framework is not derived from a single research paper but rather integrates and builds upon various research directions highlighted in studies concerning LLM bias, hallucination, toxicity, multi-agent systems, and AI governance—themes well-represented in current AI safety and ethics research.
The Core Challenges LLMs Face
The journey with LLMs is marked by several well-documented hurdles:
- Bias Propagation: LLMs are trained on vast datasets, and they can unfortunately learn and perpetuate societal biases present in this data. This is a key concern explored in research on understanding and mitigating bias in LLMs and bias inheritance.
- LLM Hallucinations: These models can generate information that is plausible-sounding but incorrect or nonsensical, often stated with high confidence. Research is actively exploring types, causes, and solutions for LLM hallucinations, including methods like smoothed knowledge distillation and Retrieval Augmented Generation (RAG), though RAG itself can have hallucination issues.
- Toxic and Harmful Content: Without robust safeguards, LLMs risk generating offensive, inappropriate, or harmful outputs. This necessitates research into evaluating toxicity and combating toxic language, including implementing LLM guardrails and safety-aware fine-tuning.
- Misinformation and Factuality: The ease with which LLMs generate text raises concerns about the spread of LLM-generated fake news. This has spurred research into automated fact-checking using LLMs and evaluating if LLMs can catch their own lies.
Introducing the LLM Council: A Collaborative, Research-Informed Approach
To address these multifaceted challenges, we propose The LLM Council – a conceptual multi-agent system. This idea draws inspiration from research into Multi-Agent Systems and Ensemble Learning for Large Language Models, where multiple specialized AI agents collaborate to achieve a common goal, offering more robust and reliable outcomes than a single monolithic model. The aim is to create layers of scrutiny and specialized expertise for LLM-generated content.
How The LLM Council Could Work: Drawing on Research Insights
The LLM Council would ideally consist of several specialized LLM agents, each leveraging findings from distinct research areas:
-
The Bias Auditor Agent:
- Function: Scrutinizes outputs for biases related to gender, race, age, and other characteristics.
- Research Basis: Leverages techniques discussed in detecting and mitigating bias in LLMs through methods like knowledge graph-augmented training and understanding bias inheritance in downstream tasks.
-
The Reality Checker Agent (Anti-Hallucination Unit):
- Function: Cross-references claims against verified knowledge bases, checks for internal consistency, and flags potential hallucinations.
- Research Basis: Implements strategies from research on reducing hallucinations, potentially using techniques like fact-checking processes and approaches to mitigate hallucinations via dual processes of fast and slow thinking or smoothed knowledge distillation.
-
The Ethics & Safety Guardian Agent:
- Function: Acts as a dynamic content filter against toxic, unethical, or harmful content.
- Research Basis: Employs safety-aware fine-tuning, implements LLM guardrails, and utilizes filtering techniques like HAP filtering against harmful content, as explored in research on responsible LLMs and safety standards.
-
The Misinformation Detective Agent:
- Function: Evaluates the authenticity of information, identifies patterns typical of fake news, and assesses source reliability.
- Research Basis: Based on advancements in automated fact-checking with Large Language Models and studies on LLM-generated fake news.
-
The Oversight Coordinator & Ensemble Agent:
- Function: Manages the workflow between agents, aggregates their findings, and potentially employs ensemble methods to synthesize the most reliable and safe output. It could facilitate a debate-feedback mechanism among agents.
- Research Basis: Draws from ensemble learning for LLMs and the architectural principles of multi-agent collaboration and trustworthy multi-LLM networks.
Grounded in a Research Ecosystem
The "LLM Council" concept is a way to operationalize the diverse safety and governance strategies found within the broader AI research landscape. It acknowledges that no single solution is likely sufficient. Instead, it points towards a future where:
- Open Source LLMs (like LLaMa variants) and Proprietary LLMs (such as GPT series or Claude models) could potentially contribute specialized agents to such a council, leveraging the unique strengths of each.
- Continuous evaluation and monitoring are essential, as highlighted in research on generative AI metrics.
- AI governance frameworks and responsible AI practices provide the overarching principles guiding the council's design and operation.
Benefits of an LLM Council Framework
- Layered Defense: Multiple checkpoints enhance the likelihood of catching errors, biases, or harmful content.
- Specialized Expertise: Each agent focuses on a specific problem, allowing for deeper and more nuanced analysis.
- Increased Trustworthiness: By systematically addressing known LLM weaknesses, outputs become more reliable.
- Adaptive Governance: The framework can be updated as new research emerges and new challenges are identified.
Conclusion: Towards More Responsible AI
The LLM Council is a conceptual model for a future where LLM safety and governance are not afterthoughts but integral parts of their architecture. It synthesizes numerous ongoing research efforts aimed at creating AI that is not only powerful but also principled, fair, and safe. While technical implementation presents challenges, the underlying principles – collaboration, specialization, and layered security – offer a promising path towards realizing the full potential of LLMs responsibly. This aligns with the broader call for AI safety cases and technical AI guardrails in the development and deployment of artificial intelligence.