











































































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)




































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)


















![QA - Best methods for getting large amount of test data into event consuming applications generated from an API application [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)

























.jpeg?#)


































































-11.11.2024-4-49-screenshot.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)






















_jvphoto_Alamy.jpg?#)




.png?#)


































































































![Apple Debuts Official Trailer for 'Murderbot' [Video]](https://www.iclarified.com/images/news/96972/96972/96972-640.jpg)
![Alleged Case for Rumored iPhone 17 Pro Surfaces Online [Image]](https://www.iclarified.com/images/news/96969/96969/96969-640.jpg)

![Apple Rushes Five Planes of iPhones to US Ahead of New Tariffs [Report]](https://www.iclarified.com/images/news/96967/96967/96967-640.jpg)



















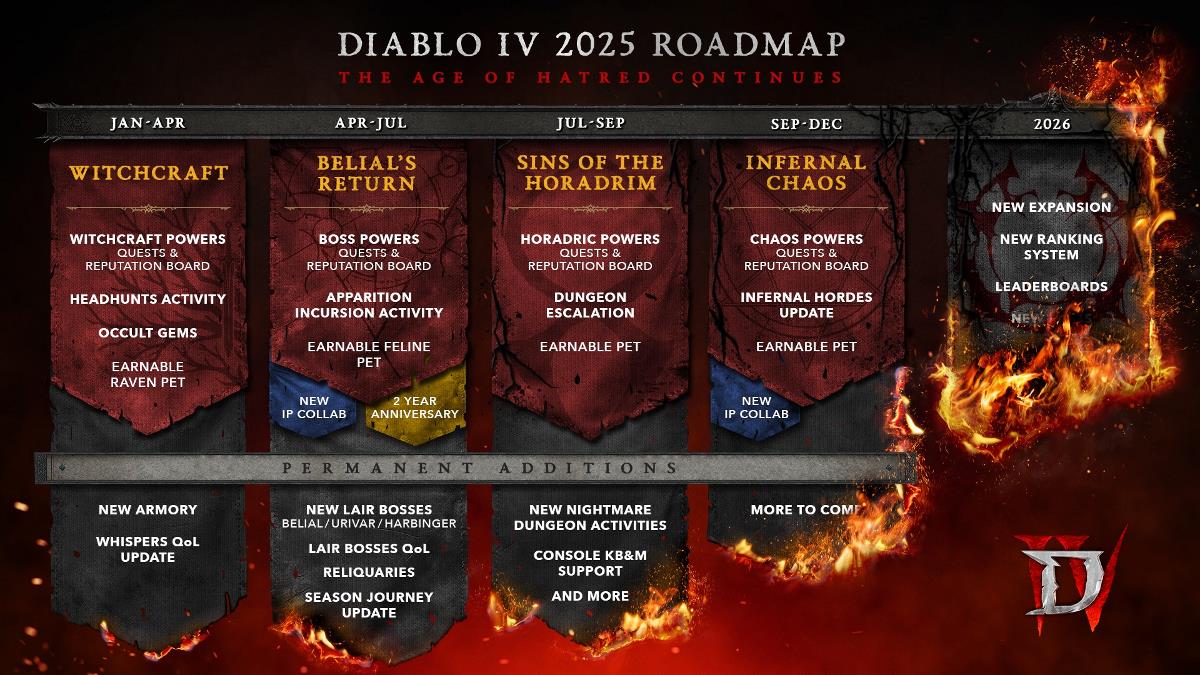






































































































Which Model Does it Better in a Knowledge-Based Evaluation?
In the rapidly evolving landscape of AI, Claude, GPT, and Gemini stand out as leading Large Language Models (LLMs). Each model brings unique strengths to the table, but how do they stack up against each other in terms of performance? Image from SearchEngine Journal First thing's first, we'll only dive into their performance in the MMLU (Massive Multitask Language Understanding) benchmark. It is used to test general knowledge and reasoning across 57 subjects. So, does your favorite model reason that well? IF we take a look at the figure above, those scores represent the models' ability to answer questions correctly across a wide range of topics, with higher scores indicating better performance. Top Performers: GPT-4o leads with a score of 88.7%, showcasing its exceptional general knowledge and reasoning capabilities. Claude-3-Opus closely follows with 86.8%, demonstrating its strong performance in complex tasks. GPT-4 achieves 86.5%, slightly trailing behind Claude-3-Opus but still excelling in most scenarios. GPT-4o's top score of 88.7% reflects its dominance in general knowledge tasks, making it ideal for academic or research-oriented applications. However, while it excels in accuracy, they require significant computational resources. The performance comparison reveals a clear hierarchy among the models. GPT-4o and Claude-3-Opus lead the pack, with GPT-4 close behind. Gemini offers a versatile middle ground, while the Claude-3 series provides options tailored to different needs. Ultimately, the choice of model depends on the specific requirements of your project—whether you prioritize accuracy, efficiency, or versatility. References: https://www.searchenginejournal.com/chatgpt-vs-gemini-vs-claude/483690/ https://wielded.com/blog/gpt-4o-benchmark-detailed-comparison-with-claude-and-gemini
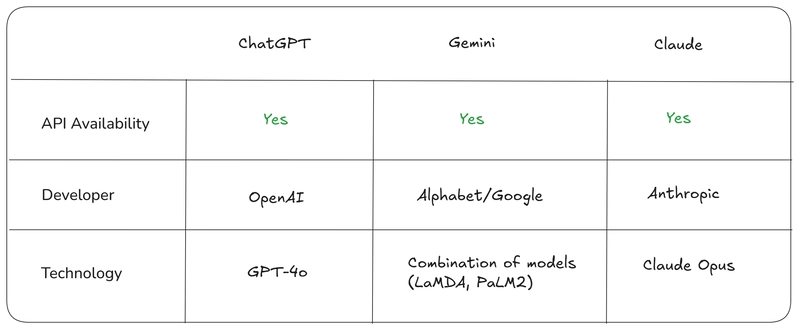
In the rapidly evolving landscape of AI, Claude, GPT, and Gemini stand out as leading Large Language Models (LLMs). Each model brings unique strengths to the table, but how do they stack up against each other in terms of performance?
Image from SearchEngine Journal
First thing's first, we'll only dive into their performance in the MMLU (Massive Multitask Language Understanding) benchmark. It is used to test general knowledge and reasoning across 57 subjects.
So, does your favorite model reason that well?

IF we take a look at the figure above, those scores represent the models' ability to answer questions correctly across a wide range of topics, with higher scores indicating better performance.
Top Performers:
- GPT-4o leads with a score of 88.7%, showcasing its exceptional general knowledge and reasoning capabilities.
- Claude-3-Opus closely follows with 86.8%, demonstrating its strong performance in complex tasks.
- GPT-4 achieves 86.5%, slightly trailing behind Claude-3-Opus but still excelling in most scenarios.
GPT-4o's top score of 88.7% reflects its dominance in general knowledge tasks, making it ideal for academic or research-oriented applications. However, while it excels in accuracy, they require significant computational resources.
The performance comparison reveals a clear hierarchy among the models. GPT-4o and Claude-3-Opus lead the pack, with GPT-4 close behind. Gemini offers a versatile middle ground, while the Claude-3 series provides options tailored to different needs. Ultimately, the choice of model depends on the specific requirements of your project—whether you prioritize accuracy, efficiency, or versatility.
References:
https://www.searchenginejournal.com/chatgpt-vs-gemini-vs-claude/483690/
https://wielded.com/blog/gpt-4o-benchmark-detailed-comparison-with-claude-and-gemini



