











































































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)




































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)


















![QA - Best methods for getting large amount of test data into event consuming applications generated from an API application [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)

























.jpeg?#)


































































-11.11.2024-4-49-screenshot.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)






















_jvphoto_Alamy.jpg?#)




.png?#)


































































































![Apple Debuts Official Trailer for 'Murderbot' [Video]](https://www.iclarified.com/images/news/96972/96972/96972-640.jpg)
![Alleged Case for Rumored iPhone 17 Pro Surfaces Online [Image]](https://www.iclarified.com/images/news/96969/96969/96969-640.jpg)

![Apple Rushes Five Planes of iPhones to US Ahead of New Tariffs [Report]](https://www.iclarified.com/images/news/96967/96967/96967-640.jpg)



















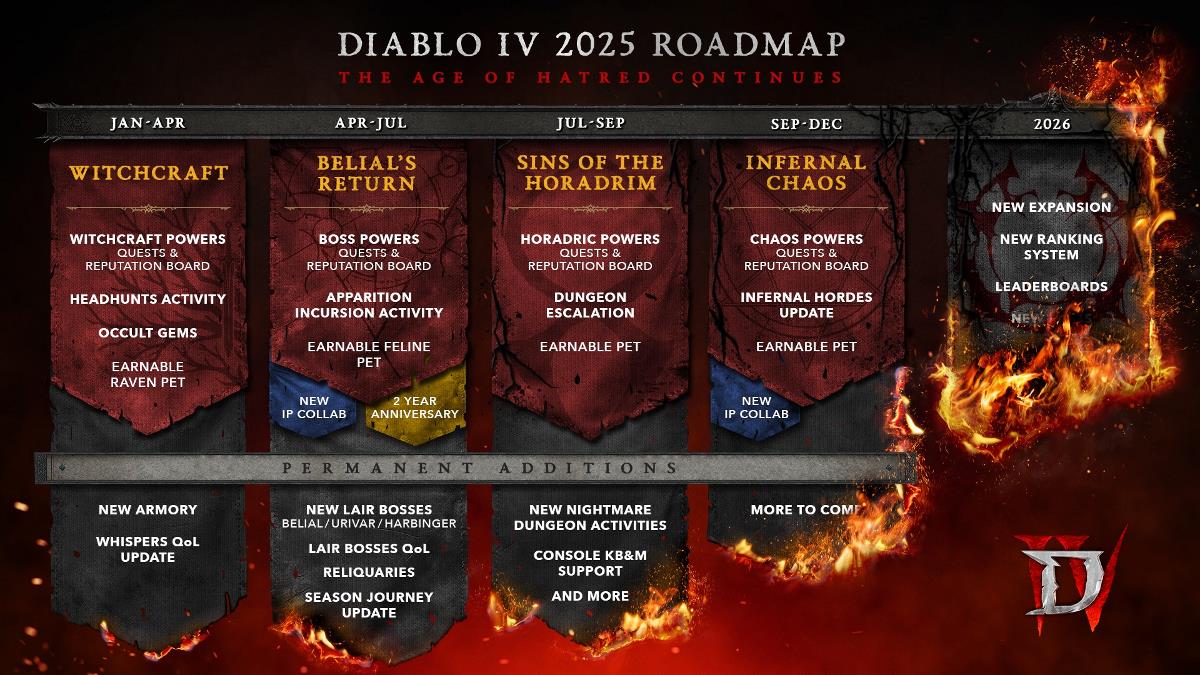
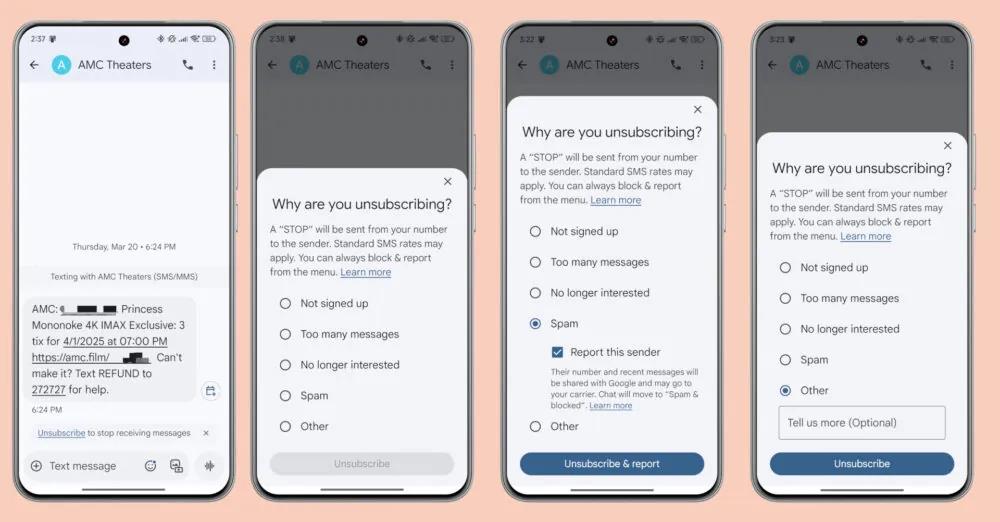

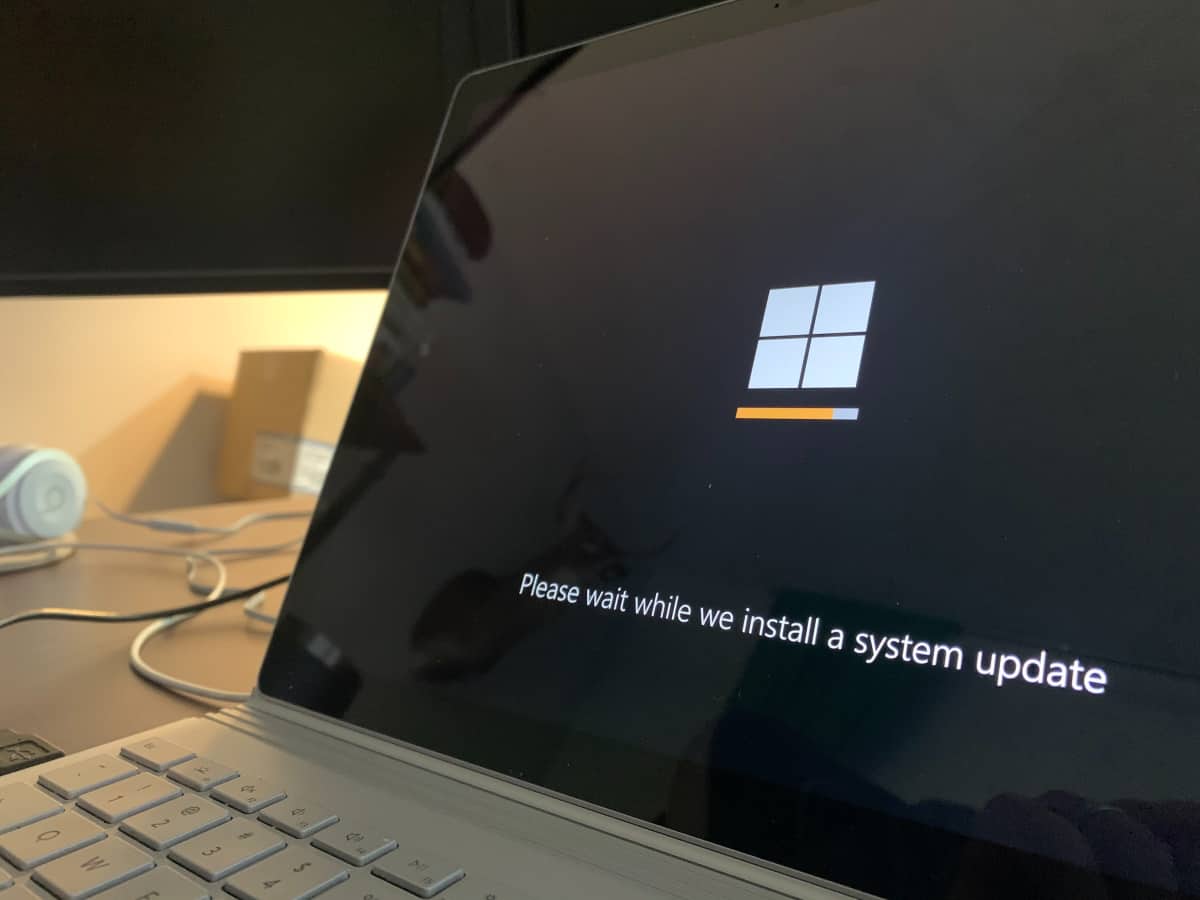





































































































Web Scraping with Puppeteer and Python: A Developer’s Guide
Web scraping modern, JavaScript-heavy websites often requires tools that can interact with dynamic content like a real user. Puppeteer, a Node.js library by Google, is a powerhouse for browser automation—but what if you want to use Python instead of JavaScript? In this guide, we’ll bridge the gap by exploring Pyppeteer, an unofficial Python port of Puppeteer, and show how Python developers can leverage its capabilities for robust web scraping. Why Puppeteer (and Pyppeteer)? Puppeteer is renowned for: Controlling headless Chrome/Chromium browsers. Handling JavaScript rendering, clicks, form submissions, and screenshots. Debugging and performance analysis. Pyppeteer brings these features to Python, offering a familiar API for developers who prefer Python over JavaScript. While not officially maintained, it’s still widely used for tasks like: Scraping Single-Page Applications (SPAs). Automating logins and interactions. Generating PDFs or screenshots. Getting Started with Pyppeteer 1. Install Pyppeteer pip install pyppeteer 2. Launch a Browser import asyncio from pyppeteer import launch async def main(): browser = await launch(headless=False) # Set headless=True for background page = await browser.newPage() await page.goto('https://example.com') print(await page.title()) await browser.close() asyncio.get_event_loop().run_until_complete(main()) Note: Pyppeteer automatically downloads Chromium on first run. Basic Web Scraping Workflow Let’s scrape product data from a demo e-commerce site. Step 1: Extract Dynamic Content async def scrape_products(): browser = await launch(headless=True) page = await browser.newPage() await page.goto('https://webscraper.io/test-sites/e-commerce/allinone') # Wait for product elements to load await page.waitForSelector('.thumbnail') # Extract titles and prices products = await page.querySelectorAll('.thumbnail') for product in products: title = await product.querySelectorEval('.title', 'el => el.textContent') price = await product.querySelectorEval('.price', 'el => el.textContent') print(f"{title.strip()}: {price.strip()}") await browser.close() asyncio.get_event_loop().run_until_complete(scrape_products()) Step 2: Handle Pagination Click buttons or scroll to load more content: # Click a "Next" button await page.click('button:contains("Next")') # Scroll to trigger lazy loading await page.evaluate('window.scrollTo(0, document.body.scrollHeight)') await page.waitForTimeout(2000) # Wait for content to load Advanced Techniques 1. Automate Logins async def login(): browser = await launch(headless=False) page = await browser.newPage() await page.goto('https://example.com/login') # Fill credentials await page.type('#username', 'your_email@test.com') await page.type('#password', 'secure_password') # Submit form await page.click('#submit-button') await page.waitForNavigation() # Verify login success await page.waitForSelector('.dashboard') print("Logged in successfully!") await browser.close() 2. Intercept Network Requests Capture API responses or block resources (e.g., images): async def intercept_requests(): browser = await launch() page = await browser.newPage() # Block images to speed up scraping await page.setRequestInterception(True) async def block_images(request): if request.resourceType in ['image', 'stylesheet']: await request.abort() else: await request.continue_() page.on('request', block_images) await page.goto('https://example.com') await browser.close() 3. Generate Screenshots/PDFs await page.screenshot({'path': 'screenshot.png', 'fullPage': True}) await page.pdf({'path': 'page.pdf', 'format': 'A4'}) Best Practices Avoid Detection: Use stealth plugins (e.g., pyppeteer-stealth). Rotate user agents: await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64)') Mimic human behavior with randomized delays. Error Handling: try: await page.goto('https://unstable-site.com') except Exception as e: print(f"Error: {e}") Proxy Support: browser = await launch(args=['--proxy-server=http://proxy-ip:port']) Pyppeteer vs. Alternatives Tool Language Best For Pyppeteer Python Simple Puppeteer-like workflows Playwright Python Modern cross-browser automation Selenium Python Legacy browser support When to Use Pyppeteer: You need Puppeteer-like features in Python. Lightweight projects where Playwright/Scrapy is overkill. Limitations: Unofficial port (updates may lag behind Puppeteer). Limited community support. Real-World Use C

Web scraping modern, JavaScript-heavy websites often requires tools that can interact with dynamic content like a real user. Puppeteer, a Node.js library by Google, is a powerhouse for browser automation—but what if you want to use Python instead of JavaScript? In this guide, we’ll bridge the gap by exploring Pyppeteer, an unofficial Python port of Puppeteer, and show how Python developers can leverage its capabilities for robust web scraping.
Why Puppeteer (and Pyppeteer)?
Puppeteer is renowned for:
- Controlling headless Chrome/Chromium browsers.
- Handling JavaScript rendering, clicks, form submissions, and screenshots.
- Debugging and performance analysis.
Pyppeteer brings these features to Python, offering a familiar API for developers who prefer Python over JavaScript. While not officially maintained, it’s still widely used for tasks like:
- Scraping Single-Page Applications (SPAs).
- Automating logins and interactions.
- Generating PDFs or screenshots.
Getting Started with Pyppeteer
1. Install Pyppeteer
pip install pyppeteer
2. Launch a Browser
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False) # Set headless=True for background
page = await browser.newPage()
await page.goto('https://example.com')
print(await page.title())
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
Note: Pyppeteer automatically downloads Chromium on first run.
Basic Web Scraping Workflow
Let’s scrape product data from a demo e-commerce site.
Step 1: Extract Dynamic Content
async def scrape_products():
browser = await launch(headless=True)
page = await browser.newPage()
await page.goto('https://webscraper.io/test-sites/e-commerce/allinone')
# Wait for product elements to load
await page.waitForSelector('.thumbnail')
# Extract titles and prices
products = await page.querySelectorAll('.thumbnail')
for product in products:
title = await product.querySelectorEval('.title', 'el => el.textContent')
price = await product.querySelectorEval('.price', 'el => el.textContent')
print(f"{title.strip()}: {price.strip()}")
await browser.close()
asyncio.get_event_loop().run_until_complete(scrape_products())
Step 2: Handle Pagination
Click buttons or scroll to load more content:
# Click a "Next" button
await page.click('button:contains("Next")')
# Scroll to trigger lazy loading
await page.evaluate('window.scrollTo(0, document.body.scrollHeight)')
await page.waitForTimeout(2000) # Wait for content to load
Advanced Techniques
1. Automate Logins
async def login():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://example.com/login')
# Fill credentials
await page.type('#username', 'your_email@test.com')
await page.type('#password', 'secure_password')
# Submit form
await page.click('#submit-button')
await page.waitForNavigation()
# Verify login success
await page.waitForSelector('.dashboard')
print("Logged in successfully!")
await browser.close()
2. Intercept Network Requests
Capture API responses or block resources (e.g., images):
async def intercept_requests():
browser = await launch()
page = await browser.newPage()
# Block images to speed up scraping
await page.setRequestInterception(True)
async def block_images(request):
if request.resourceType in ['image', 'stylesheet']:
await request.abort()
else:
await request.continue_()
page.on('request', block_images)
await page.goto('https://example.com')
await browser.close()
3. Generate Screenshots/PDFs
await page.screenshot({'path': 'screenshot.png', 'fullPage': True})
await page.pdf({'path': 'page.pdf', 'format': 'A4'})
Best Practices
-
Avoid Detection:
- Use stealth plugins (e.g.,
pyppeteer-stealth). - Rotate user agents:
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64)') - Use stealth plugins (e.g.,
- Mimic human behavior with randomized delays.
- Error Handling:
try:
await page.goto('https://unstable-site.com')
except Exception as e:
print(f"Error: {e}")
- Proxy Support:
browser = await launch(args=['--proxy-server=http://proxy-ip:port'])
Pyppeteer vs. Alternatives
| Tool | Language | Best For |
|---|---|---|
| Pyppeteer | Python | Simple Puppeteer-like workflows |
| Playwright | Python | Modern cross-browser automation |
| Selenium | Python | Legacy browser support |
When to Use Pyppeteer:
- You need Puppeteer-like features in Python.
- Lightweight projects where Playwright/Scrapy is overkill.
Limitations:
- Unofficial port (updates may lag behind Puppeteer).
- Limited community support.
Real-World Use Cases
- E-commerce Monitoring: Track prices on React/Angular sites.
- Social Media Automation: Scrape public posts from platforms like Instagram.
- Data Extraction from Dashboards: Pull data from authenticated analytics tools.
- Automated Testing: Validate UI workflows during development.
Conclusion
Pyppeteer brings Puppeteer’s powerful browser automation capabilities to Python, making it a solid choice for scraping JavaScript-heavy sites. While it lacks the robustness of Playwright or Selenium, its simplicity and Puppeteer-like API make it ideal for Python developers tackling dynamic content.
Next Steps:
- Explore Pyppeteer’s documentation.
- Integrate proxies for large-scale scraping.
- Combine with
asynciofor concurrent scraping tasks.
Pro Tip: Always check a website’s robots.txt and terms of service before scraping. When in doubt, use official APIs!
Happy scraping!



