![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)








































































































































































.jpg?#)





































































-Mafia-The-Old-Country---The-Initiation-Trailer-00-00-54.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)
-Nintendo-Switch-2---Reveal-Trailer-00-01-52.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)

























_Aleksey_Funtap_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_Sergey_Tarasov_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)












































































































![Apple Shares Official Trailer for 'Stick' Starring Owen Wilson [Video]](https://www.iclarified.com/images/news/97264/97264/97264-640.jpg)


![Beats Studio Pro Wireless Headphones Now Just $169.95 - Save 51%! [Deal]](https://www.iclarified.com/images/news/97258/97258/97258-640.jpg)



























































































Understanding Flyte's Dynamic Workflows: How They Power Scalable ML Pipelines
In this post, I’ll explain how Flyte’s Dynamic Workflows work and what they mean for your ML pipelines. Flyte Workflows define a pipeline as a Directed Acyclic Graph (DAG). This abstraction allows the representation of complex processes with branches, but without loops. Consequently, each new execution of the DAG must start from the beginning or from an intermediate point, which can impact compute efficiency—more on that in future posts. Flyte’s workflow lifecycle has two main phases: compile time and run time. During compile time, Flyte serializes the code, packages it, and uploads it to blob storage, making it accessible to the control plane. This process is called registration. The focus here is on speed and efficiency, primarily by performing type checking without executing the code. Instead of evaluating function inputs, Flyte simply records an “intent to execute.” In most languages, using async/await returns a coroutine, whereas Flyte returns a Promise object. Flyte uses promises as a temporary mechanism to prevent function evaluation during compile time. Since the Promise is asynchronous, it must be awaited at runtime to be resolved and executed. This approach enables async evaluation but differs from native Python mechanisms, though that may change in future Flyte versions. Tasks vs workflows At compile time, workflows are evaluated, but Tasks are only lazily evaluated because we don’t need to perform computations at that point. How so? Well, workflows are used to structure tasks, NOT to perform computations, so they can be safely materialized at registration time. Tasks, on the other hand, DO perform computations, so to enable fast iterations over the DAG, they need to be lazily evaluated at compile time and evaluated ONLY at run time. Dynamic workflows They sit in the middle of a Task and a Workflow. They build the structure of tasks (DAG) as a workflow would do, but they are only evaluated at runtime, just like Tasks. They perform the computation and build the DAG both at runtime. Their return object is a Promise, so outputs cannot be accessed directly, but one can write a task that consumes them. Let's use an example to understand this better: from flytekit import task, workflow, dynamic, ImageSpec import pandas as pd from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score custom_image = ImageSpec( packages=["pandas", "scikit-learn", "pyarrow",], registry="localhost:30000" ) @task(container_image=custom_image) def preprocess_data() -> list[pd.DataFrame]: # Simulate data loading and preprocessing data = [{'feature1': [1, 2, 3, 4], 'feature2': [5, 6, 7, 8], 'label': [0, 1, 0, 1]}] dfs = [pd.DataFrame(data_dict) for data_dict in data] return dfs @task(container_image=custom_image) def train_model(data: pd.DataFrame, hyperparameter: float) -> float: # Split data into features and labels X = data[['feature1', 'feature2']] y = data['label'] # Train a simple logistic regression model model = LogisticRegression(C=hyperparameter) model.fit(X, y) # Predict and calculate accuracy predictions = model.predict(X) accuracy = accuracy_score(y, predictions) return accuracy @dynamic(container_image=custom_image) def dynamic_workflow(hyperparameters: list[float]) -> list[float]: # Preprocess data data = preprocess_data() # Use a for loop to train models with different hyperparameters accuracies = [] for hyperparameter in hyperparameters: for df in data: accuracy = train_model(data=df, hyperparameter=hyperparameter) accuracies.append(accuracy) return accuracies @workflow def ml_pipeline(hyperparameters: list[float]) -> list[float]: return dynamic_workflow(hyperparameters=hyperparameters) In a nutshell, what this workflow does is to take two arbitrary and unknown string inputs and return the number of common characters between the two. When we run it on a Flyte cluster, we can see that it involves both concurrent and parallel execution, all within the same context (same execution ID). In that regard, it behaves like a workflow, but the fact that inputs are only materialized at runtime makes it look like a task. It’s also interesting to confirm that the DAG doesn’t build until the tasks have run: Fun facts: @dynamic works locally because flytekit treats it as a regular task. When a dynamic task is executed, it generates the entire DAG as output. You will find it as the futures.pbfile, meaning the workflow is yet to be executed When to use Dynamic Workflows? If inputs are only lazily evaluated at registration time, that gives me more flexibility to define them dynamically at runtime Working with inputs that are unknown from the beginning or are designed to change in response to other system metrics. Hyperparameter optimization is a good example

In this post, I’ll explain how Flyte’s Dynamic Workflows work and what they mean for your ML pipelines.
Flyte Workflows define a pipeline as a Directed Acyclic Graph (DAG). This abstraction allows the representation of complex processes with branches, but without loops. Consequently, each new execution of the DAG must start from the beginning or from an intermediate point, which can impact compute efficiency—more on that in future posts.
Flyte’s workflow lifecycle has two main phases: compile time and run time.
During compile time, Flyte serializes the code, packages it, and uploads it to blob storage, making it accessible to the control plane. This process is called registration. The focus here is on speed and efficiency, primarily by performing type checking without executing the code. Instead of evaluating function inputs, Flyte simply records an “intent to execute.”
In most languages, using async/await returns a coroutine, whereas Flyte returns a Promise object. Flyte uses promises as a temporary mechanism to prevent function evaluation during compile time.
Since the Promise is asynchronous, it must be awaited at runtime to be resolved and executed. This approach enables async evaluation but differs from native Python mechanisms, though that may change in future Flyte versions.
Tasks vs workflows
At compile time, workflows are evaluated, but Tasks are only lazily evaluated because we don’t need to perform computations at that point.
How so? Well, workflows are used to structure tasks, NOT to perform computations, so they can be safely materialized at registration time.
Tasks, on the other hand, DO perform computations, so to enable fast iterations over the DAG, they need to be lazily evaluated at compile time and evaluated ONLY at run time.
Dynamic workflows
They sit in the middle of a Task and a Workflow. They build the structure of tasks (DAG) as a workflow would do, but they are only evaluated at runtime, just like Tasks. They perform the computation and build the DAG both at runtime. Their return object is a Promise, so outputs cannot be accessed directly, but one can write a task that consumes them.
Let's use an example to understand this better:
from flytekit import task, workflow, dynamic, ImageSpec
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
custom_image = ImageSpec(
packages=["pandas",
"scikit-learn",
"pyarrow",],
registry="localhost:30000"
)
@task(container_image=custom_image)
def preprocess_data() -> list[pd.DataFrame]:
# Simulate data loading and preprocessing
data = [{'feature1': [1, 2, 3, 4], 'feature2': [5, 6, 7, 8], 'label': [0, 1, 0, 1]}]
dfs = [pd.DataFrame(data_dict) for data_dict in data]
return dfs
@task(container_image=custom_image)
def train_model(data: pd.DataFrame, hyperparameter: float) -> float:
# Split data into features and labels
X = data[['feature1', 'feature2']]
y = data['label']
# Train a simple logistic regression model
model = LogisticRegression(C=hyperparameter)
model.fit(X, y)
# Predict and calculate accuracy
predictions = model.predict(X)
accuracy = accuracy_score(y, predictions)
return accuracy
@dynamic(container_image=custom_image)
def dynamic_workflow(hyperparameters: list[float]) -> list[float]:
# Preprocess data
data = preprocess_data()
# Use a for loop to train models with different hyperparameters
accuracies = []
for hyperparameter in hyperparameters:
for df in data:
accuracy = train_model(data=df, hyperparameter=hyperparameter)
accuracies.append(accuracy)
return accuracies
@workflow
def ml_pipeline(hyperparameters: list[float]) -> list[float]:
return dynamic_workflow(hyperparameters=hyperparameters)
In a nutshell, what this workflow does is to take two arbitrary and unknown string inputs and return the number of common characters between the two.
When we run it on a Flyte cluster, we can see that it involves both concurrent and parallel execution, all within the same context (same execution ID). In that regard, it behaves like a workflow, but the fact that inputs are only materialized at runtime makes it look like a task.
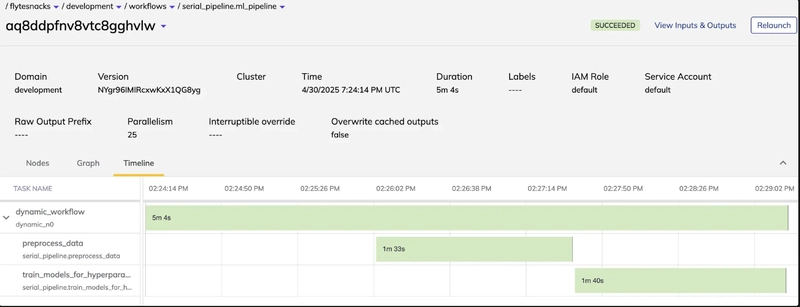
It’s also interesting to confirm that the DAG doesn’t build until the tasks have run:

Fun facts:
- @dynamic works locally because flytekit treats it as a regular task.
- When a dynamic task is executed, it generates the entire DAG as output. You will find it as the
futures.pbfile, meaning the workflow is yet to be executed
When to use Dynamic Workflows?
- If inputs are only lazily evaluated at registration time, that gives me more flexibility to define them dynamically at runtime
- Working with inputs that are unknown from the beginning or are designed to change in response to other system metrics. Hyperparameter optimization is a good example
Combining dynamism and parallelism
If you read my previous post, you may have had a similar reaction to mine with the example I used in this post: why use a for loop when I can use MapTask?
Let's look at the following example that transforms our ML pipeline with a combination of dynamic workflows and MapTasks:
from flytekit import task, workflow, dynamic, map_task, ImageSpec
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
custom_image = ImageSpec(
packages=["pandas",
"scikit-learn",
"pyarrow",],
registry="localhost:30000"
)
@task(container_image=custom_image)
def preprocess_data() -> list[pd.DataFrame]:
# Simulate data loading and preprocessing
data = [{'feature1': [1, 2, 3, 4], 'feature2': [5, 6, 7, 8], 'label': [0, 1, 0, 1]}]
dfs = [pd.DataFrame(data_dict) for data_dict in data]
return dfs
@task(container_image=custom_image)
def train_model(data: pd.DataFrame, hyperparameter: float) -> float:
# Split data into features and labels
X = data[['feature1', 'feature2']]
y = data['label']
# Train a simple logistic regression model
model = LogisticRegression(C=hyperparameter)
model.fit(X, y)
# Predict and calculate accuracy
predictions = model.predict(X)
accuracy = accuracy_score(y, predictions)
return accuracy
@dynamic(container_image=custom_image)
def dynamic_workflow(hyperparameters: list[float]) -> list[float]:
# Preprocess data
data = preprocess_data()
# Use map_task to train models in parallel with different hyperparameters
accuracies = map_task(train_model)(data=data, hyperparameter=hyperparameters)
return accuracies
@workflow
def ml_pipeline(hyperparameters: list[float]) -> list[float]:
return dynamic_workflow(hyperparameters=hyperparameters)
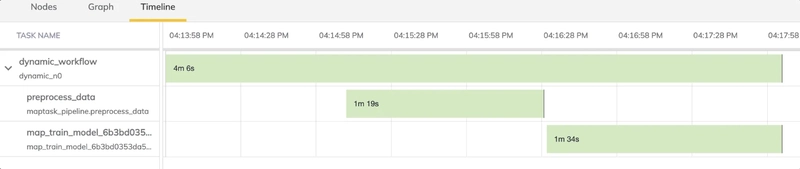
You can run this example in the local Flyte sandbox cluster
The result is a 20% faster execution, thanks to the power of parallel processing:
Conclusion
Modern use cases like LLMs, where the user defines the input at runtime via prompting, demands the level of dynamism Flyte can offer with Dynamic Workflows. This post shared some insights on how they work and how to combine them with parallelism to achieve both flexible and efficient computation.
Learn more about Flyte Dynamic Workflows in the docs
Questions? -> join the Flyte Slack community !