




































































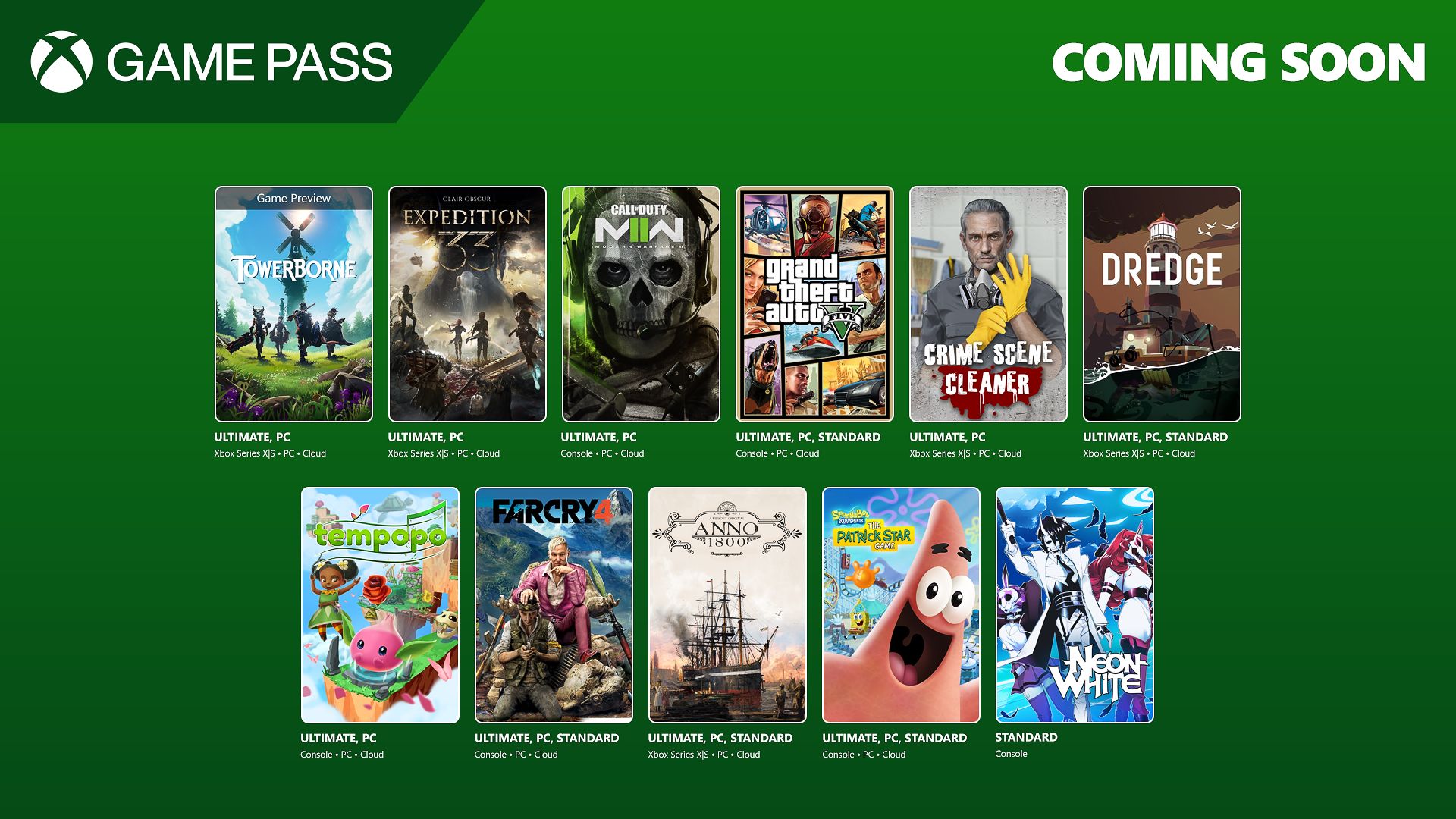
![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)















































































































































































































































































































































.png?#)


.jpeg?#)






.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)


















































































































![Leaker vaguely comments on under-screen camera in iPhone Fold [U]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/04/iPhone-Fold-will-have-Face-ID-embedded-in-the-display-%E2%80%93-leaker.webp?resize=1200%2C628&quality=82&strip=all&ssl=1)


![[Fixed] Gemini app is failing to generate Audio Overviews](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/03/Gemini-Audio-Overview-cover.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













![Apple Seeds tvOS 18.5 Beta 2 to Developers [Download]](https://www.iclarified.com/images/news/97011/97011/97011-640.jpg)
![Apple Releases macOS Sequoia 15.5 Beta 2 to Developers [Download]](https://www.iclarified.com/images/news/97014/97014/97014-640.jpg)





















































































































Ultimate Guide to Supercharging LLM JSON Outputs with Precision Schema Descriptions
You're harnessing the power of OpenAI's Large Language Models (LLMs) to generate structured JSON data. Whether through the robust function calling mechanism or the newer, guarantee-focused Structured Outputs API (strict: true), you've defined your schemas – types, properties, enums, required fields. Yet, sometimes the output, while syntactically valid, isn't quite semantically right. The model picks the wrong enum, misunderstands a field's nuance, or populates a value that technically fits the type but misses the mark contextually. What's often the missing link? The humble description field within your JSON schema. Too many developers treat descriptions as mere afterthoughts – documentation for humans. But for an LLM interacting with your schema, descriptions are potent instructions. They are a fundamental part of the implicit prompt the model receives, guiding its interpretation and shaping its output far more than you might realize. Neglecting them, or writing them poorly, is like giving a brilliant assistant vague instructions and hoping for the best. This guide is your deep dive into mastering the Description Directive. We will explore why descriptions are non-negotiable for high-fidelity JSON output, drawing comprehensively from OpenAI documentation, developer deep dives, community forums, and real-world experiences. Prepare for actionable principles, detailed examples grounded in documented issues, and the strategies needed to elevate your LLM's structured data generation from merely functional to flawlessly accurate. Beyond Syntax: Why Descriptions Are the Semantic Compass for LLMs When an LLM encounters your JSON schema, it doesn't just see field names and data types (string, integer, boolean). The API intelligently processes the description fields you provide for the overall function/tool and for each individual parameter property. Here’s why this matters profoundly: Context is King: A field named location could mean anything. A description "The city and state, or city and country, where the event takes place (e.g., 'San Francisco, CA' or 'Paris, France')." provides crucial context the model needs to extract or infer the correct information from the user's query. Sources emphasize using clear names and descriptions (Function Calling - Inference.net Documentation). Implicit Prompting Power: Descriptions function as direct, embedded instructions for the model regarding that specific field. The model effectively "reads" these when deciding what value to generate. Analysis suggests the model might internally see these as commented declarations, like // The unique identifier for the customer account preceding the field definition (Best practice for describing function enum choices - API - OpenAI Developer Community), making them a powerful influence on its choices. Not leveraging them is a significant missed opportunity (Function Calling parameter types - Prompting - OpenAI Developer Community). Resolving Ambiguity: Does date mean YYYY-MM-DD or a natural language date? Does units refer to metric or imperial? Descriptions eliminate guesswork. "The specific date in YYYY-MM-DD format." leaves no room for error. This prevents the model from making potentially incorrect assumptions based on its training data. Guiding Value Selection (Especially Enums & Formats): This is where descriptions truly shine. Enums: Simply providing enum: ["A", "B", "C"] is insufficient if the model doesn't understand the semantic meaning. A description explaining what each enum value represents is critical for mapping user requests (e.g., "make it urgent") to the correct schema value (e.g., "URGENT"). Community experience shows models struggling with non-obvious enums (like "foozle", "bartingus") without descriptive guidance (Best practice for describing function enum choices - API - OpenAI Developer Community). Formats: While format: "date-time" or format: "email" provide hints, models (especially older ones or without strict mode) might still deviate. A description like "User's email address (must contain '@' and a domain)." reinforces the expected pattern. Similarly, if expecting "YYYY-MM-DD", the model might output "March 3, 2025"; adding the format to the description reduces this risk ([Source 1/2 discussion on format issues]). The Spirit vs. The Letter (Even with strict: true): The Structured Outputs feature (strict: true) is a game-changer, guaranteeing the output JSON adheres syntactically to your schema (correct types, required fields present, valid enum values chosen) (Introducing Structured Outputs in the API | OpenAI). It enforces the letter of the schema. However, it doesn't guarantee the content is logically correct or matches the user's intent. That's where descriptions come in – they guide the model towards the spirit of the schema, ensuring the syntactically valid output is also semantically meaningful and accurate ([Source 1/2 discussion on strict mode value]). Structured Outputs make

You're harnessing the power of OpenAI's Large Language Models (LLMs) to generate structured JSON data. Whether through the robust function calling mechanism or the newer, guarantee-focused Structured Outputs API (strict: true), you've defined your schemas – types, properties, enums, required fields. Yet, sometimes the output, while syntactically valid, isn't quite semantically right. The model picks the wrong enum, misunderstands a field's nuance, or populates a value that technically fits the type but misses the mark contextually.
What's often the missing link? The humble description field within your JSON schema.
Too many developers treat descriptions as mere afterthoughts – documentation for humans. But for an LLM interacting with your schema, descriptions are potent instructions. They are a fundamental part of the implicit prompt the model receives, guiding its interpretation and shaping its output far more than you might realize. Neglecting them, or writing them poorly, is like giving a brilliant assistant vague instructions and hoping for the best.
This guide is your deep dive into mastering the Description Directive. We will explore why descriptions are non-negotiable for high-fidelity JSON output, drawing comprehensively from OpenAI documentation, developer deep dives, community forums, and real-world experiences. Prepare for actionable principles, detailed examples grounded in documented issues, and the strategies needed to elevate your LLM's structured data generation from merely functional to flawlessly accurate.
Beyond Syntax: Why Descriptions Are the Semantic Compass for LLMs
When an LLM encounters your JSON schema, it doesn't just see field names and data types (string, integer, boolean). The API intelligently processes the description fields you provide for the overall function/tool and for each individual parameter property. Here’s why this matters profoundly:
- Context is King: A field named
locationcould mean anything. A description"The city and state, or city and country, where the event takes place (e.g., 'San Francisco, CA' or 'Paris, France')."provides crucial context the model needs to extract or infer the correct information from the user's query. Sources emphasize using clear names and descriptions (Function Calling - Inference.net Documentation). - Implicit Prompting Power: Descriptions function as direct, embedded instructions for the model regarding that specific field. The model effectively "reads" these when deciding what value to generate. Analysis suggests the model might internally see these as commented declarations, like
// The unique identifier for the customer accountpreceding the field definition (Best practice for describing function enum choices - API - OpenAI Developer Community), making them a powerful influence on its choices. Not leveraging them is a significant missed opportunity (Function Calling parameter types - Prompting - OpenAI Developer Community). - Resolving Ambiguity: Does
datemeanYYYY-MM-DDor a natural language date? Doesunitsrefer to metric or imperial? Descriptions eliminate guesswork."The specific date in YYYY-MM-DD format."leaves no room for error. This prevents the model from making potentially incorrect assumptions based on its training data. - Guiding Value Selection (Especially Enums & Formats): This is where descriptions truly shine.
- Enums: Simply providing
enum: ["A", "B", "C"]is insufficient if the model doesn't understand the semantic meaning. A description explaining what each enum value represents is critical for mapping user requests (e.g., "make it urgent") to the correct schema value (e.g.,"URGENT"). Community experience shows models struggling with non-obvious enums (like"foozle","bartingus") without descriptive guidance (Best practice for describing function enum choices - API - OpenAI Developer Community). - Formats: While
format: "date-time"orformat: "email"provide hints, models (especially older ones or without strict mode) might still deviate. A description like"User's email address (must contain '@' and a domain)."reinforces the expected pattern. Similarly, if expecting"YYYY-MM-DD", the model might output"March 3, 2025"; adding the format to the description reduces this risk ([Source 1/2 discussion on format issues]).
- Enums: Simply providing
- The Spirit vs. The Letter (Even with
strict: true): The Structured Outputs feature (strict: true) is a game-changer, guaranteeing the output JSON adheres syntactically to your schema (correct types, required fields present, valid enum values chosen) (Introducing Structured Outputs in the API | OpenAI). It enforces the letter of the schema. However, it doesn't guarantee the content is logically correct or matches the user's intent. That's where descriptions come in – they guide the model towards the spirit of the schema, ensuring the syntactically valid output is also semantically meaningful and accurate ([Source 1/2 discussion on strict mode value]). Structured Outputs makes descriptions more important, not less, because the model will follow the schema, so the schema (including descriptions) must accurately capture your needs.
Writing poor descriptions forces the LLM into a guessing game based only on field names and its vast, but sometimes imprecise, general knowledge. This increases the probability of semantic errors, contextually wrong values, or frustratingly unhelpful null outputs where specific information was expected.
The Description Directive: 8 Pillars of Precision Guidance
Let's transform this understanding into actionable techniques. These principles, synthesized from documentation and real-world developer experience, will help you craft descriptions that maximize LLM accuracy:
Pillar 1: Eradicate Ambiguity - Be Explicit and Specific
Vagueness is the enemy. Clearly articulate what the field represents and any relevant constraints or context.
- Insufficient:
"value": { "type": "number", "description": "The value" } - Precise:
"temperature_celsius": { "type": "number", "description": "The target temperature setting in degrees Celsius. Must be between 15.0 and 30.0." }(Note: While numeric bounds might not always be strictly enforced pre-strict mode, mentioning them guides the model).
Pillar 2: Illuminate Intent - Explain the 'Why'
Why does this field exist? What role does it play? Explaining the purpose helps the model make smarter choices, especially for less obvious or optional parameters.
- Insufficient:
"optional_notes": { "type": "string", "description": "Notes if any" } - Informative:
"user_provided_context": { "type": "string", "description": "Optional field for the user to provide any additional context or specific instructions that might influence the task outcome. Leave empty if user provides no extra details." }
Pillar 3: Mandate Formats – Leave No Room for Interpretation
Never assume the model knows your preferred format. State it unequivocally in the description, even if using the format keyword.
- Insufficient:
"event_date": { "type": "string", "format": "date", "description": "Date of the event" } - Mandatory:
"event_date": { "type": "string", "format": "date", "description": "The exact date of the event in YYYY-MM-DD format (e.g., 2024-10-28)." } - Mandatory:
"start_timestamp": { "type": "string", "format": "date-time", "description": "The precise start date and time in ISO 8601 format, including timezone offset (e.g., '2024-11-15T09:30:00+01:00')." }
Pillar 4: Show, Don't Just Tell – Embed Examples
Concrete examples within the description text are incredibly effective. The model sees these directly and uses them as anchors.
- Insufficient:
"country_code": { "type": "string", "description": "ISO country code." } - Illustrative:
"country_code": { "type": "string", "description": "The 2-letter ISO 3166-1 alpha-2 country code (e.g., 'US', 'GB', 'FR')." } - Illustrative:
"css_selector": { "type": "string", "description": "A CSS selector to target a specific HTML element (e.g., '#main-content p.important')." }- Self-Correction: While JSON Schema Draft 2020-12 supports an
exampleskeyword (an array), community findings and practical experience suggest embedding examples directly in thedescriptionstring is more reliably processed by current OpenAI models ([Source 1/2 discussion on examples]).
- Self-Correction: While JSON Schema Draft 2020-12 supports an
Pillar 5: Decode Enums – Provide the Semantic Key
This is paramount. For enum fields, the description must explain what each allowed value means in the context of the task. This allows the model to map natural language requests to the correct, constrained value.
- Problematic (based on community reports): A schema with
enum: ["foozle", "bartingus", "quibble"]and a vague description like"Select the operation type."failed when the user asked for the "blue thingy," because the model couldn't link "blue thingy" to the correct abstract enum value ([Source 1/2 enum discussion]). -
The Solution: Embed definitions directly in the field's description.
-
Poor Enum:
"status_code": { "type": "string", "description": "Status indicator.", "enum": ["A1", "B2", "C3"] } -
Excellent Enum:
"task_status": { "type": "string", "description": "Current status of the background task. Must be one of: 'PENDING' (Task is queued but not started), 'RUNNING' (Task is actively processing), 'COMPLETED' (Task finished successfully), 'FAILED' (Task encountered an error).", "enum": ["PENDING", "RUNNING", "COMPLETED", "FAILED"] }
This detailed mapping is crucial for the model to choose correctly based on context ("Is the job done yet?" ->
COMPLETED, "Did the process break?" ->FAILED). -
Pillar 6: Amplify Constraints – Reinforce required and More
While required is a structural keyword, and strict: true enforces it, adding a textual cue like "Required." at the start of a description can serve as an extra prompt reinforcement, especially if you previously observed issues with the model omitting it ([Source 1/2 discussion on required fields]). You can also reinforce other implicit constraints.
- Standard:
"query": { "type": "string", "description": "The user's search query." }(assumingqueryis inrequiredarray) - Reinforced:
"query": { "type": "string", "description": "**Required.** The user's natural language search query. Must not be empty." }
Pillar 7: Strike the Balance – Concise Clarity
Be informative but avoid unnecessary verbosity or overly technical jargon (unless the model is expected to understand it from wider context). Aim for the sweet spot of enough detail for clarity without overwhelming the model.
Pillar 8: Speak the AI's Language – Write as Instruction
Frame descriptions as guidance for an intelligent agent performing a task. Use imperative mood where appropriate ("Specify the format...", "Choose one of..."). Think: "What does the AI need to know at this point to fill this specific field correctly?"
Integrating Descriptions with Your Workflow (e.g., Pydantic)
Many developers use libraries like Pydantic (Python) or Zod (TypeScript) to define data models and generate JSON schemas automatically. This is a great practice for ensuring schema correctness ([Source 1/2 Pydantic mention]).
Crucially, these libraries often generate the description field from your code comments or docstrings! This means:
- Your code documentation is your description prompt. Write clear, detailed docstrings for your model fields.
-
Example (Pydantic):
from pydantic import BaseModel, Field from typing import List, Optional class CreateMeetingParams(BaseModel): title: str = Field(..., description="The main title or subject of the meeting (e.g., 'Project Alpha Kickoff'). Must be provided.") participant_ids: List[str] = Field(..., description="**Required.** An array of unique user IDs (UUID format) for all attendees. Do not include the meeting creator.") start_time: str = Field(..., description="**Required.** The meeting start date and time in ISO 8601 format, including timezone (e.g., '2024-12-01T10:00:00-05:00').", format="date-time") duration_minutes: Optional[int] = Field(default=30, description="Optional. The duration of the meeting in minutes (e.g., 60 for 1 hour). Defaults to 30 minutes if not specified.") # ... other fieldsWhen you call
CreateMeetingParams.model_json_schema(), these descriptions flow directly into the generated JSON schema. Caveat: Remember the Pydantic v1 issue with
$reffor nested models. Ensure your schema generation process (using Pydantic v2 or flattening) produces self-contained schemas, as expected by the OpenAI API ([Source 1/2 Pydantic caveat]). How nested descriptions are handled might depend on your flattening strategy.
Debugging with Descriptions: Your First Line of Defense
When your LLM produces syntactically valid JSON that's semantically wrong, your first debugging step should often be reviewing the schema descriptions:
- Is the description for the problematic field missing, vague, or misleading?
- Could an example clarify the expected format or content?
- For enums, is the mapping between user intent and schema value clearly explained?
- Did you recently change logic without updating the description?
Often, refining the description is the fastest way to fix the model's behavior. Consider the "explanation" field trick: one developer added an optional explanation field to the output schema with a description asking the model to explain its reasoning for the other fields' values. This acted as a form of chain-of-thought prompting via the schema, indirectly improving the accuracy of the primary fields and aiding debuggability ([Source 3 explanation field]). This showcases how descriptions can be used creatively.
Remember to test and iterate ([Source 1/2 test and iterate]). Modify a description, run test prompts, observe the output change. Treat description refinement as an integral part of your prompt engineering cycle.
Conclusion: Elevate Your Outputs with the Description Directive
In the landscape of LLM-driven structured data generation, JSON schema descriptions are far more than mere comments. They are the semantic compass, the implicit prompt, the instruction manual that guides the model beyond mere syntax to true understanding and accurate execution.
Even as features like Structured Outputs (strict: true) provide guarantees on format adherence, descriptions remain indispensable for ensuring the content within that format is correct, relevant, and aligned with your application's needs. They are the key to unlocking the full potential of reliable, high-fidelity JSON generation.
Stop treating descriptions as an afterthought. Embrace the Description Directive:
- Be explicit, specific, and clear.
- Explain intent and context.
- Mandate formats and provide examples.
- Decode enums with semantic keys.
- Reinforce constraints where needed.
- Integrate them into your code documentation workflow.
- Use them as your first line of debugging.
By meticulously crafting and testing your schema descriptions, you provide the precise guidance LLMs crave. The payoff? More reliable, accurate, and valuable JSON outputs, leading to smarter, more robust AI applications that perform exactly as intended. Make descriptions your secret weapon.



