







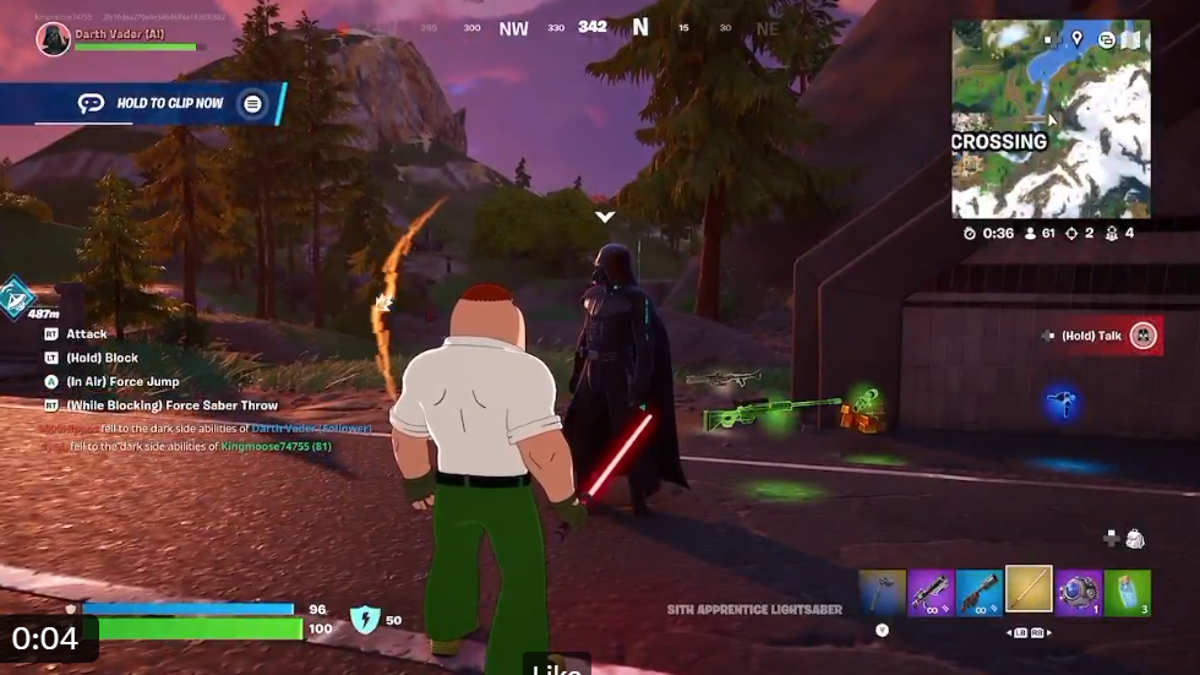
![Epic Games: Fortnite is offline for Apple devices worldwide after app store rejection [updated]](https://helios-i.mashable.com/imagery/articles/00T6DmFkLaAeJiMZlCJ7eUs/hero-image.fill.size_1200x675.v1747407583.jpg)

































































































































































![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)
















































































































































































































































.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)































































































-xl-(1)-xl-xl.jpg)










![How to upgrade the M4 Mac mini SSD and save hundreds [Video]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/05/M4-Mac-mini-SSD-Upgrade-Tutorial-2TB.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)
![‘Apple in China’ book argues that the iPhone could be killed overnight [Updated]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/05/Apple-in-China-review.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)




![What’s new in Android’s May 2025 Google System Updates [U: 5/16]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)












![iPhone 17 Air Could Get a Boost From TDK's New Silicon Battery Tech [Report]](https://www.iclarified.com/images/news/97344/97344/97344-640.jpg)
![Vision Pro Owners Say They Regret $3,500 Purchase [WSJ]](https://www.iclarified.com/images/news/97347/97347/97347-640.jpg)
![Apple Showcases 'Magnifier on Mac' and 'Music Haptics' Accessibility Features [Video]](https://www.iclarified.com/images/news/97343/97343/97343-640.jpg)
![Sony WH-1000XM6 Unveiled With Smarter Noise Canceling and Studio-Tuned Sound [Video]](https://www.iclarified.com/images/news/97341/97341/97341-640.jpg)







































![Apple Stops Signing iPadOS 17.7.7 After Reports of App Login Issues [Updated]](https://images.macrumors.com/t/DoYicdwGvOHw-VKkuNvoxYs3pfo=/1920x/article-new/2023/06/ipados-17.jpg)

























Smart In-Store Clothing Assistant – From Style Query to Shelf Location
Ever walked into a clothing store and wished a smart system could just tell you what to wear based on your style, the occasion, and where to find it in the store? That was the idea that sparked this project. I wanted to explore how such a kiosk system might work — not only recommending clothing based on user queries but also guiding the customer to the shelf where it’s located. This document outlines the thought process and approach I followed while building this project. It covers the initial vision, the key problems I aimed to solve, the technologies I chose, and how I systematically broke the system down into modular components for development. It also includes the architectural decisions, design iterations, and how each part fits into the final integrated solution. It is an exploration project! how things work So, there are two sub-systems: Smart Clothing Recommendations - understands user queries and retrieves appropriate clothing suggestions, based on on-store availability. Navigating to that shelf where the selected item can be found. (This is to exlpore how local navigation or pathfinding can be done, instead of calling any third-party API, like creating map for store layout and marking the shelfs.) For the first part, i.e. Getting items searching based on customer’s requirements/query, i don’t want the user to search for a specific product to show up – that's just searching! I want the software to understand, what kind of occasion? What kind of clothes he/she wants to wear, Customer: simple and casual for evening birthday party Something like that. This isn't a product name — it’s an intent. So, our system needs to understand the meaning and match it to relevant items. - looking for Semantic Similarity. But normal string search is not something that will help us, we need to find matching results based on description of cloths i.e itself is text data. So, we are looking for something that understands and searches for context or matching closest description that describes the type which suites the customer’s query. So, here we are looking to search the intent or context not actual word-word matching (string matching), i.e we need to capture the meaning of text data and match accordingly. We want software to understand what customer is trying to say by capturing the meaning of query and then search for similar items using item’s description. Good! So, computers don’t understand text data, i.e. to make it understand text data, we need to convert text data into numerical vectors using Text Embedding Model (that's what Natural Language Processing is). What are Text Embeddings? Text embeddings are numerical representations of text that capture semantic meaning. Instead of looking at just keywords, embeddings understand context — so two phrases that mean the same thing will have similar embeddings, even if the words differ. (Here, Gemini's Text Embedding Model via API call is used) So, first generating a description of clothing items based on their style, influence, material. This can be done by either another Deep Learning model that understands the cloth images and generates based on fashion (use any pre-trained model or create your own) or just human input, that is not my concern as of now, any of the ways will work. So, i got my description of each items defining style influence, material, fashion sense, occasion and ethnicity. This description is created by LLM (Large Language Model), by prompting the required description pattern. LLM here used is Gemini, as it offers free API service. { "product_name": "Urban Cotton Hoodie", "price": 1899, "essential_attributes": "cotton, relaxed fit, pullover hoodie", "style_influence": "streetwear, Gen Z, casual", "intended_use": "daily wear, college, winter layering", "imageUrl":"/img/urban_hoodie.png", "description": "Relaxed fit cotton pullover hoodie with streetwear Gen Z casual style for daily wear college winter layering. Suitable for all genders.", "shelfNumber":1 }, Choosing Database Now we must store these items and descriptions as vector data, so we need to use Vector Database. I have picked ChromaDB for my vector DB. It allows attaching metadata (e.g., product name, price, image URL) with each embedding (built-in), making post-search filtering straightforward. ChromaDB offers two types of storage – In-Memory – the database is volatile and runs in-memory while the instance is active. Persistent Storage – you can create and store your database in permanent storage and use it anywhere in other projects as well – non-Volatile So, the flow is like, store descriptions of items in vector format, and keep other details such as name of product, price, size information and anything else in metadata. Creating Vector embedding of descriptions Storing product_Names, price, img_url, any other details in metadata A

Ever walked into a clothing store and wished a smart system could just tell you what to wear based on your style, the occasion, and where to find it in the store? That was the idea that sparked this project. I wanted to explore how such a kiosk system might work — not only recommending clothing based on user queries but also guiding the customer to the shelf where it’s located.
This document outlines the thought process and approach I followed while building this project. It covers the initial vision, the key problems I aimed to solve, the technologies I chose, and how I systematically broke the system down into modular components for development. It also includes the architectural decisions, design iterations, and how each part fits into the final integrated solution. It is an exploration project! how things work
So, there are two sub-systems:
- Smart Clothing Recommendations - understands user queries and retrieves appropriate clothing suggestions, based on on-store availability.
- Navigating to that shelf where the selected item can be found. (This is to exlpore how local navigation or pathfinding can be done, instead of calling any third-party API, like creating map for store layout and marking the shelfs.)
For the first part, i.e. Getting items searching based on customer’s requirements/query, i don’t want the user to search for a specific product to show up – that's just searching!
I want the software to understand, what kind of occasion? What kind of clothes he/she wants to wear,
Customer: simple and casual for evening birthday party
Something like that.
This isn't a product name — it’s an intent. So, our system needs to understand the meaning and match it to relevant items. - looking for Semantic Similarity.
But normal string search is not something that will help us, we need to find matching results based on description of cloths i.e itself is text data. So, we are looking for something that understands and searches for context or matching closest description that describes the type which suites the customer’s query.
So, here we are looking to search the intent or context not actual word-word matching (string matching), i.e we need to capture the meaning of text data and match accordingly.
We want software to understand what customer is trying to say by capturing the meaning of query and then search for similar items using item’s description. Good!
So, computers don’t understand text data, i.e. to make it understand text data, we need to convert text data into numerical vectors using Text Embedding Model (that's what Natural Language Processing is).
What are Text Embeddings?
Text embeddings are numerical representations of text that capture semantic meaning. Instead of looking at just keywords, embeddings understand context — so two phrases that mean the same thing will have similar embeddings, even if the words differ.
(Here, Gemini's Text Embedding Model via API call is used)
So, first generating a description of clothing items based on their style, influence, material. This can be done by either another Deep Learning model that understands the cloth images and generates based on fashion (use any pre-trained model or create your own) or just human input, that is not my concern as of now, any of the ways will work.
So, i got my description of each items defining style influence, material, fashion sense, occasion and ethnicity. This description is created by LLM (Large Language Model), by prompting the required description pattern. LLM here used is Gemini, as it offers free API service.
{
"product_name": "Urban Cotton Hoodie",
"price": 1899,
"essential_attributes": "cotton, relaxed fit, pullover hoodie",
"style_influence": "streetwear, Gen Z, casual",
"intended_use": "daily wear, college, winter layering",
"imageUrl":"/img/urban_hoodie.png",
"description": "Relaxed fit cotton pullover hoodie with streetwear Gen Z casual style for daily wear college winter layering. Suitable for all genders.",
"shelfNumber":1
},
Choosing Database
Now we must store these items and descriptions as vector data, so we need to use Vector Database.
I have picked ChromaDB for my vector DB. It allows attaching metadata (e.g., product name, price, image URL) with each embedding (built-in), making post-search filtering straightforward.
ChromaDB offers two types of storage –
- In-Memory – the database is volatile and runs in-memory while the instance is active.
- Persistent Storage – you can create and store your database in permanent storage and use it anywhere in other projects as well – non-Volatile
So, the flow is like, store descriptions of items in vector format, and keep other details such as name of product, price, size information and anything else in metadata.
- Creating Vector embedding of descriptions
- Storing product_Names, price, img_url, any other details in metadata
- Apply vector search to descriptions
- Return matching results
Vector Database Searching
How does vector search works? Basically, it uses cosine-similarity to match how close or similar are two words/phrases. Using cosine similarity, the vector of the query is compared with all item vectors.
The closest matches are retrieved.
Why Cosine Similarity?
Cosine similarity measures the angle between two vectors (ignoring magnitude), making it ideal for understanding how "close" two meanings are, regardless of length.
It’s what RAG (Retrieval Augmented Generation) means. You provide a document (text) and want your model to retrieve answer to use it as knowledge base and runs inherence based on that. Matching and getting information from provided document. Well one thing more to it happens that the information retrieved is exact phrase which may not appropriate answer, so it is then feeded to LLM model with a prompt specified to return an answer. Now for that also, our software must know the meaning of words, that’s why use LLM models, they are pre-trained to get the meaning of words and phrases and efficient in finding context and intent of sentences. Else you can train your own LLM model, but that requires a very large database and expertise to bring LLM performance to matching level and that will eventually bottleneck your development process.
So, similarity search will fetch matching results, good. Now we just need to pass whatever the query customer asks for, to our ChromaDB to give similar results!
Why Just Embedding the Query Isn't Enough
In vector-based semantic search systems, the effectiveness of retrieval heavily depends on the semantic alignment between the user query and the stored item descriptions. Since product descriptions are crafted using a consistent prompt structure, tone, and vocabulary (via an LLM like Gemini), user queries — which can be casual, unstructured, or incomplete — often fail to match the same contextual space.
This mismatch leads to suboptimal similarity scores during vector comparison.
Adding Query Transformation Layer
To address this, we introduce a Query Transformation Layer that sits between the user’s input and the embedding process. Here, an LLM interprets the raw query, extracts the core intent, identifies key contextual attributes (e.g., style, occasion, fit), and reconstructs the query in a form that mirrors the tone, grammar, and structural prompt pattern of the original item descriptions. It will also handle spellings errors and remove emojis/punctuation. This reduces unnecessary LLM calls and speeds up response time.
def refine_query_for_search(user_input):
refined_query_prompt = (
f"Convert the following customer request into a short, search phrase "
f"suitable for retrieving men's fashion products from a vector database. "
f"Keep it under 10 words and do not include explanations.\n\n"
f"User Request: '{user_input}'\n"
f"Search Phrase:"
)
response = client.models.generate_content(
model="gemini-2.0-flash",
contents=refined_query_prompt,
)
refined_query = response.text
return refined_query
This transformation ensures the query is not only semantically rich but also structurally compatible — increasing the chances of high-fidelity matches during vector similarity search.
As a result, the system retrieves items that are not just loosely related but contextually and semantically aligned with what the user is truly looking for.
Sample results from searching in ChromaDB

The metadata can be used to extract product_name, price and other details.
Now, our flow looks like this,

This completes one part of it.
Yes, we will be getting a list of items, and we can then extract required fields to display that on either webpage or any other way. We will discuss that later.
Navigation and PathFinding
Now that we got the results, lets focus on navigation component or pathfinding to that shelf where the item can be found.
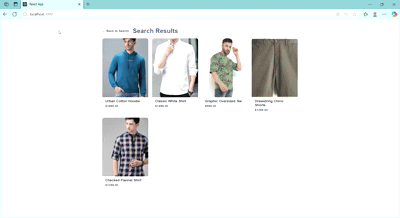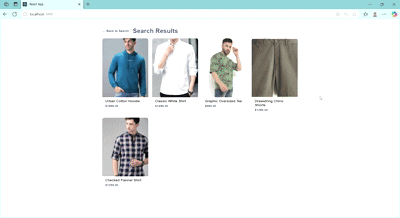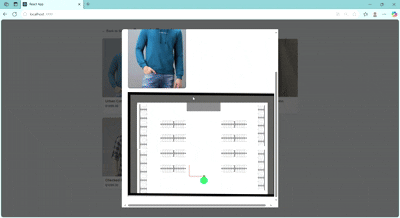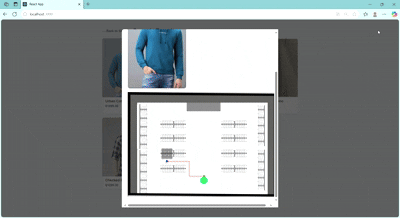
So, for the navigation i am not looking for real-time tracking, we just tell customer which shelf and where to look for, just to give an idea but in a certain manner.
No real-time location tracking, that means we don’t need any GPS tracking. Will use simple pathfinding algorithms to find shortest path between two stationary points – that's the initial idea.
I could’ve used pre-designed images of store layout mapped with each shelf path from kiosk, but that will be like hardcoded and if in any case, the store decides to change the location of kiosk – that could be because of any reason. Then we need to re-create all images. - not a good thing.
So implementing a path finding algorithm is viable, we can give inputs as two points so that even if store layout is changed, path finding won’t be affected. Yes, the store layout changes will require us to re-create a new map and a new grid/matrix and re-map the shelfs and walls. But we avoided a hassle of managing hardcoded mapping of path in images. - better than before (improved)
Now to track paths, i am using grid paths (basically a matrix of NxN size and will apply PathFinding algorithms to find path from (x1,y1) to (x2,y2). This NxN size grid will cover all the store layout and will contain information such as walkable area and walls/shelfs as 0s and 1s respectively.
Since there are not so much different types of obstacles, simple 1s for non-walkable areas and 0s for walkable areas will do fine.
Creating Map and Grid
Now, we must create a 2D layout of store and generate a grid of NxN over it. Then using coordinates, will specify 1s and 0s ( this is exhausting if map is way too large, we can use other Deep Learning Model or create one that takes input as image and generates a grid size of NxN and performs image segmentation based on identifying obstacles and marking walkable and non-walkable coordinates (considering a group of pixels as one cell, depending on grid size and each cell size))

We can tweak rows and columns to match the store layout.
Below is a workaround to mark walkable areas and shelfs

Here, the shelf are numbered are like this

As every shelf can be considered as just coordinates, so whenever we want to highlight a shelf, we can just look for its coordinates (x,y)
shelf_data = {
1 : [[15,9],[17,11]],
2 : [[7,25],[9,28]],
3 : [[11,25],[12,28]],
4 : [[7,25],[9,28]],
5 : [[8,9],[9,11]],
6 : [[8,12],[9,15]],
7 : [[18,3],[19,4]],
8 : [[15,12],[17,15]],
}
PathFinding
Here, we are looking to get the shortest path to a shelf, as we don’t want to display a possible path that loops inefficiently around other shelves. So, the Breadth-First Search (BFS) algorithm is implemented to find the shortest path between two points on a unweighted grid. Since the cost of every move is uniform (i.e., moving from one cell to a neighboring cell has the same cost), BFS is an optimal and suitable choice.
Initially, the BFS was implemented by storing the path taken so far along with every grid node visited. This means that for every point explored, the full list of steps from the starting point to that node was stored and carried in memory.
Issues with Vanilla BFS
Although it worked correctly, it was not memory-efficient. As BFS explores more and more paths, each step forward duplicates the current path list and adds one more coordinate. This led to:
- High memory usage, especially on large grids.
- Redundant storage of overlapping path segments.
- Slower performance due to list copying at each BFS iteration.

Optimization with Parent-Tracking
To overcome these limitations, we optimized the BFS by implementing a parent-tracking approach.
Instead of carrying the entire path for each node, we now store the parent (previous node) for every visited cell in a 2D array (grid). Once the destination is reached, we reconstruct the path by walking backward from the destination to the start using the stored parent pointers, and then reverse the result to get the correct order.
It -
- Reduces memory usage significantly.
- Improves BFS performance by avoiding repeated list copying.


Example:
0 0 1
0 1 0
0 0 0
where Starting point = (0,0) and ending point = (2,2)
Path from BFS
(0,0) → (1,0) → (2,0) → (2,1) → (2,2)
Reconstructing Path
Parent_tracker will look like this -
parentTracker[{1,0}] = {0,0};
parentTracker[{2,0}] = {1,0};
parentTracker[{2,1}] = {2,0};
parentTracker[{2,2}] = {2,1};

| Step | Current Node (curr) |
Parent Node (parentTracker[curr]) |
Path So Far |
|---|---|---|---|
| 1 | (2,2) | (2,1) | [(2,1)] |
| 2 | (2,1) | (2,0) | [(2,1), (2,0)] |
| 3 | (2,0) | (1,0) | [(2,1), (2,0), (1,0)] |
| 4 | (1,0) | (0,0) | [(2,1), (2,0), (1,0), (0,0)] |
After Reversing
(0,0) → (1,0) → (2,0) → (2,1)
Overall Code
vector GridPathFinder::get_shortestDistanceOpti(coordinates st, coordinates en) {
struct node {
int x, y;
};
vector path;
queue q;
vector distX = { 0,0,1,-1,1,-1 };
vector distY = { 1,-1,0,0,1,-1 };
unordered_map parentTracker;
q.push({ st.first, st.second });
visited[st.first][st.second] = true;
while (!q.empty()) {
node tempNode = q.front();
q.pop();
int x = tempNode.x;
int y = tempNode.y;
if (x == en.first && y == en.second) {
break; // found the shortest path
}
for (int i = 0; i < distX.size(); i++) {
int newX = x + distX[i];
int newY = y + distY[i];
if (isValid(newX, newY)) {
visited[newX][newY] = true;
parentTracker[{newX, newY}] = { x,y };
q.push({ newX,newY });
}
}
}
vector finalPath = {};
coordinates curr = en;
// re-constructing the path using ParentTracker
while(curr!=st) {
// running loop for number of elements in tracker
coordinates temp = parentTracker[curr];
finalPath.push_back(temp);
curr = temp;
}
reverse(finalPath.begin(), finalPath.end());
// resetting visited for next pathFinding
this->GridPathFinder::visited = vector>(grid.size(), vector(grid[0].size(), false));
return finalPath;
}
Overall Back-end Design
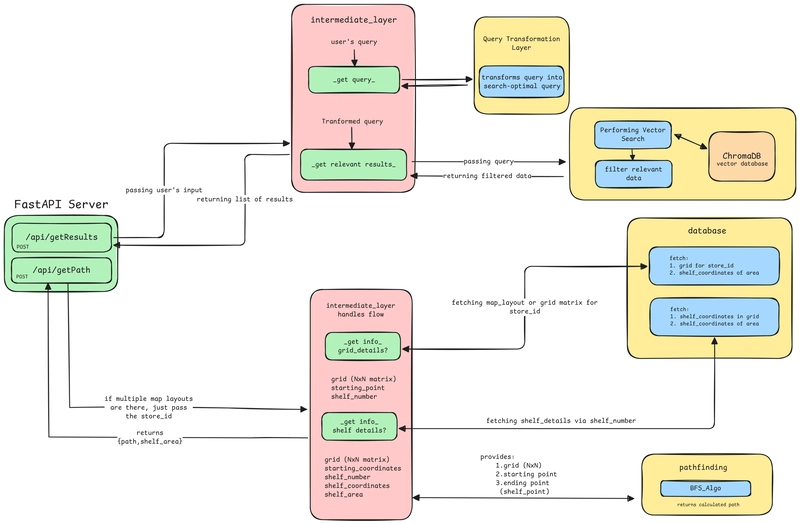
Working
Query - > "modern but simple for college"

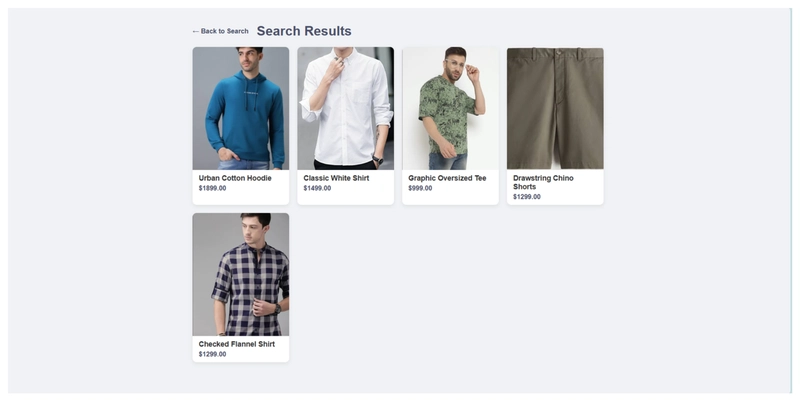
i did not focus much on front-end design..... just got it working to get core logic to work...


