![[Free Webinar] Guide to Securing Your Entire Identity Lifecycle Against AI-Powered Threats](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjqbZf4bsDp6ei3fmQ8swm7GB5XoRrhZSFE7ZNhRLFO49KlmdgpIDCZWMSv7rydpEShIrNb9crnH5p6mFZbURzO5HC9I4RlzJazBBw5aHOTmI38sqiZIWPldRqut4bTgegipjOk5VgktVOwCKF_ncLeBX-pMTO_GMVMfbzZbf8eAj21V04y_NiOaSApGkM/s1600/webinar-play.jpg?#)








































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)


















































































































































































































































_XFkvNLu.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)


























_Tanapong_Sungkaew_via_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)








































































































![Apple Restructures Global Affairs and Apple Music Teams [Report]](https://www.iclarified.com/images/news/97162/97162/97162-640.jpg)
![New iPhone Factory Goes Live in India, Another Just Days Away [Report]](https://www.iclarified.com/images/news/97165/97165/97165-640.jpg)




























































































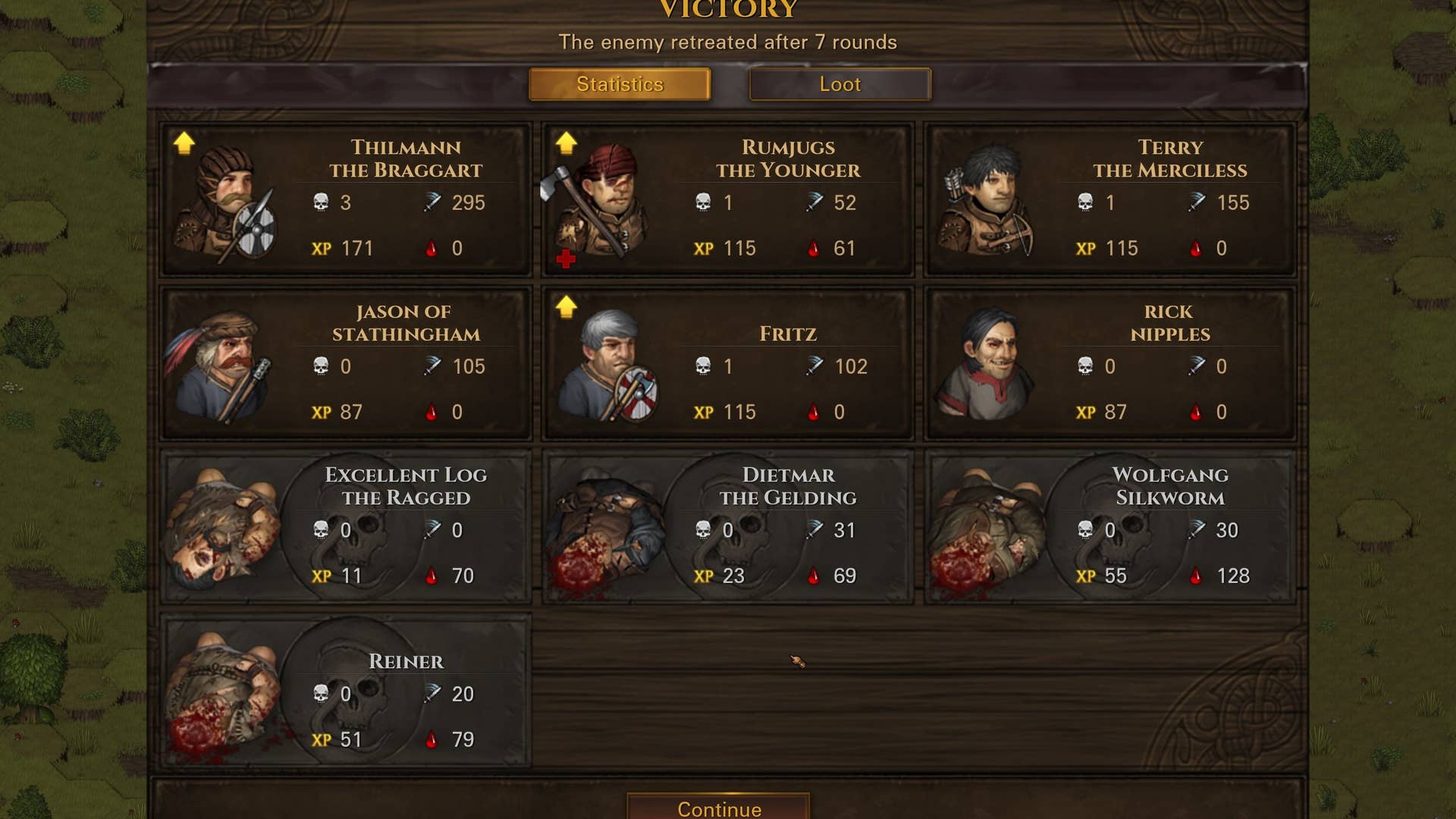
Scaling Search at finlight.me: From Postgres Full-Text to Real-Time OpenSearch
Scaling search isn't just about adding bigger servers — sometimes you need the right tools. When we first launched finlight.me, our real-time financial news API, Postgres full-text search was more than enough. It was fast, easy to set up, and fit perfectly into our simple early architecture. But as the number of articles grew and search demands became more complex, cracks started to appear. In this article, I'll share how we moved from Postgres to OpenSearch, the challenges we faced along the way, and why keeping Postgres as our source of truth turned out to be one of our best decisions. It all started with a simple full-text search setup inside Postgres that worked surprisingly well — until it didn’t. First Architecture: Postgres Full-Text Search In the early days, we used Postgres’ built-in full-text search to power article queries. Titles and content were combined into a single tsvector field, allowing us to search efficiently without worrying about casing, suffixes, or keyword order — limitations that basic %query% searches would have struggled with. Incoming search queries were also converted into vectors, and Postgres did a solid job of ranking and returning relevant results. For a while, this setup handled our needs with fast response times and minimal overhead. It was simple, integrated, and worked well alongside the rest of our ingestion and storage system. But as our article volume started to grow and user queries became more complex, we began to notice cracks forming beneath the surface. Pain Points with Scaling Postgres At first, Postgres full-text search handled our growing dataset reasonably well. But as article counts climbed into the hundreds of thousands, search performance started to noticeably degrade. The major issue wasn’t just the full-text search itself — it was how users combined free-text queries with additional filters like publish date ranges, specific sources, or metadata fields. Postgres was strong at indexing individual fields, and its GIN index accelerated full-text search. However, we quickly ran into a hard limitation: Postgres doesn’t allow combining a GIN index with a regular B-Tree index in a composite index. This meant we couldn’t optimize both kinds of queries at the same time, forcing the database to either pick a suboptimal plan or fall back to sequential scans — both of which became painfully slow as the dataset grew. Index Management Nightmare: Optional Parameters and Growing Complexity The flexibility of our API — allowing users to combine any subset of filters like publish date, source, free-text search and more — introduced another layer of scaling challenges. Since every search parameter was optional, we faced a combinatorial explosion of possible query patterns. To maintain acceptable performance, we had to create different indexes to support the most common combinations of parameters. Each time we added a new searchable field, it required designing new indexes, analyzing query plans with EXPLAIN ANALYZE, and validating performance manually. This constant index tuning became tedious and unsustainable. Worse, despite all the effort, the core limitation remained: we still couldn’t efficiently optimize full-text search combined with metadata filters in a single query. Pagination Collapse and User-Visible Slowness As article volumes continued to grow, another performance bottleneck surfaced: pagination. Our API exposed a page parameter that mapped directly to SQL OFFSET behavior behind the scenes. While this worked fine at low offsets, performance deteriorated rapidly as users requested deeper pages. Ironically, the very feature that should have made searches faster — returning just a small slice of results — ended up making things slower. Each paginated request forced Postgres to scan, count, and skip thousands of rows before it could even start returning results, recalculating large parts of the query plan every time. Queries that once took under a second ballooned to tens of seconds. At that point, it was no longer just an infrastructure problem — it became a user experience failure. We realized that even a well-tuned Postgres setup wouldn't be enough to support fast, flexible search at the scale we were growing toward. Why We Chose OpenSearch It was clear that we needed a system built specifically for search — something optimized for free-text queries, filtering, and fast pagination at scale. Having worked with Elasticsearch during previous freelance projects, we were already familiar with the strengths of dedicated search engines: inverted indexes, efficient scoring algorithms, and powerful query flexibility. We decided to adopt OpenSearch, the community-driven fork of Elasticsearch, both for its strong technical capabilities and its more favorable licensing model. At the same time, we made an important architectural decision: to separate the write path from the read path. Postgres would remain ou

Scaling search isn't just about adding bigger servers — sometimes you need the right tools.
When we first launched finlight.me, our real-time financial news API, Postgres full-text search was more than enough. It was fast, easy to set up, and fit perfectly into our simple early architecture. But as the number of articles grew and search demands became more complex, cracks started to appear. In this article, I'll share how we moved from Postgres to OpenSearch, the challenges we faced along the way, and why keeping Postgres as our source of truth turned out to be one of our best decisions.
It all started with a simple full-text search setup inside Postgres that worked surprisingly well — until it didn’t.
First Architecture: Postgres Full-Text Search
In the early days, we used Postgres’ built-in full-text search to power article queries. Titles and content were combined into a single tsvector field, allowing us to search efficiently without worrying about casing, suffixes, or keyword order — limitations that basic %query% searches would have struggled with. Incoming search queries were also converted into vectors, and Postgres did a solid job of ranking and returning relevant results. For a while, this setup handled our needs with fast response times and minimal overhead. It was simple, integrated, and worked well alongside the rest of our ingestion and storage system.
But as our article volume started to grow and user queries became more complex, we began to notice cracks forming beneath the surface.
Pain Points with Scaling Postgres
At first, Postgres full-text search handled our growing dataset reasonably well. But as article counts climbed into the hundreds of thousands, search performance started to noticeably degrade. The major issue wasn’t just the full-text search itself — it was how users combined free-text queries with additional filters like publish date ranges, specific sources, or metadata fields. Postgres was strong at indexing individual fields, and its GIN index accelerated full-text search. However, we quickly ran into a hard limitation: Postgres doesn’t allow combining a GIN index with a regular B-Tree index in a composite index. This meant we couldn’t optimize both kinds of queries at the same time, forcing the database to either pick a suboptimal plan or fall back to sequential scans — both of which became painfully slow as the dataset grew.
Index Management Nightmare: Optional Parameters and Growing Complexity
The flexibility of our API — allowing users to combine any subset of filters like publish date, source, free-text search and more — introduced another layer of scaling challenges. Since every search parameter was optional, we faced a combinatorial explosion of possible query patterns. To maintain acceptable performance, we had to create different indexes to support the most common combinations of parameters. Each time we added a new searchable field, it required designing new indexes, analyzing query plans with EXPLAIN ANALYZE, and validating performance manually. This constant index tuning became tedious and unsustainable. Worse, despite all the effort, the core limitation remained: we still couldn’t efficiently optimize full-text search combined with metadata filters in a single query.
Pagination Collapse and User-Visible Slowness
As article volumes continued to grow, another performance bottleneck surfaced: pagination. Our API exposed a page parameter that mapped directly to SQL OFFSET behavior behind the scenes. While this worked fine at low offsets, performance deteriorated rapidly as users requested deeper pages. Ironically, the very feature that should have made searches faster — returning just a small slice of results — ended up making things slower. Each paginated request forced Postgres to scan, count, and skip thousands of rows before it could even start returning results, recalculating large parts of the query plan every time. Queries that once took under a second ballooned to tens of seconds. At that point, it was no longer just an infrastructure problem — it became a user experience failure. We realized that even a well-tuned Postgres setup wouldn't be enough to support fast, flexible search at the scale we were growing toward.
Why We Chose OpenSearch
It was clear that we needed a system built specifically for search — something optimized for free-text queries, filtering, and fast pagination at scale. Having worked with Elasticsearch during previous freelance projects, we were already familiar with the strengths of dedicated search engines: inverted indexes, efficient scoring algorithms, and powerful query flexibility. We decided to adopt OpenSearch, the community-driven fork of Elasticsearch, both for its strong technical capabilities and its more favorable licensing model.
At the same time, we made an important architectural decision: to separate the write path from the read path. Postgres would remain our single source of truth for ingested and processed articles, ensuring data integrity and consistency. OpenSearch would serve as the read-optimized layer, delivering fast and flexible search without overloading our ingestion pipeline. This allowed us to use the best tool for each requirement — a reliable, relational, normalized database for storage and ingestion, and a high-performance search engine for querying — instead of trying to force one system to do everything.
Testing Phase: Starting Small and Learning Fast
Before fully committing to production, we rolled out OpenSearch in a minimal-resource testing setup: a single-node cluster with limited RAM, intended purely for evaluation and tuning. In this environment, we quickly encountered behaviors that hinted at the system's scaling needs. Over time, we noticed missing indexes and degraded search performance — symptoms likely caused by memory pressure and resource eviction events on the hosting side. Far from being a setback, these early tests validated an important lesson: while OpenSearch could deliver the performance we needed, it demanded production-grade resources to do so reliably. Testing lean allowed us to tune index mappings, validate query performance, and plan capacity based on real behavior. It also reinforced our architectural choice to keep Postgres as the source of truth, ensuring that even if the search layer needed recovery or rebuilding, the core data remained safe and consistent.
Scaling OpenSearch for Production
Armed with insights from our testing phase, we moved to a production-grade OpenSearch deployment with the resources needed to match our growth. We added multiple nodes to the cluster, allocated sufficient RAM, and tuned index mappings to optimize both write and query performance. With the new setup, search response times dropped dramatically — even complex queries with deep pagination returned results in milliseconds instead of seconds.
The overall data flow evolved as well: after articles pass through our real-time article processing pipeline — where they are collected, enriched, and analyzed — they are immediately fed into OpenSearch for fast retrieval. Postgres remains the single source of truth, storing all raw and processed data reliably, while OpenSearch acts as the read-optimized layer tuned for search performance.
We also introduced regular snapshotting of the OpenSearch indices, ensuring that even as the article base grew, we could recover quickly from failures or rebuild indexes without downtime. Treating OpenSearch as an advanced cache rather than the primary database gave us flexibility: we could evolve search schemas, rebuild indexes, or adjust mappings without putting core data integrity at risk. Over time, as traffic increased and our dataset expanded, the new architecture continued to perform reliably under load.
Today’s Architecture: Resilient, Real-Time Search
Today, our system cleanly separates responsibilities between ingestion, storage, and retrieval. Postgres continues to act as the single source of truth, reliably storing all raw and processed article data in a normalized relational structure. Articles flow through our real-time article processing pipeline — where they are scraped, enriched, and analyzed — before being fed into OpenSearch for optimized search performance. OpenSearch handles all user-facing search queries, allowing us to deliver fast, flexible results even under high load. Regular snapshotting, thoughtful index management, and a multi-node deployment ensure that our search infrastructure remains resilient and scalable as our data set grows. By decoupling the write and read sides of the architecture and choosing the best tool for each need, we've built a system that is fast, reliable, and ready for continued growth.
Lessons Learned: Advice for Builders
- Start simple, but design with scale in mind. Postgres full-text search served us well early on — but flexibility in design made migration possible later without major pain.
- Separate read and write paths as early as practical. Trying to make a single database handle everything becomes exponentially harder as complexity grows.
- Use the right tool for the job. A relational database excels at storage and consistency; a search engine excels at flexible retrieval and ranking.
- Don’t underestimate optional query complexity. Supporting flexible API filters sounds simple until you have to index every possible combination.
- Test lean, scale smart. Early testing with minimal resources taught us what production-grade OpenSearch really needed — and avoided costly surprises.
- Keep a reliable source of truth. Having Postgres behind OpenSearch allowed us to rebuild, heal, and extend our search infrastructure without risking core data integrity.
If you're building scalable APIs or working with large search datasets, I'd love to hear how you're approaching similar challenges. Feel free to share your thoughts or experiences in the comments!