







































































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)















































































































































































































































































































































































![Apple Watch to Get visionOS Inspired Refresh, Apple Intelligence Support [Rumor]](https://www.iclarified.com/images/news/96976/96976/96976-640.jpg)
![New Apple Watch Ad Features Real Emergency SOS Rescue [Video]](https://www.iclarified.com/images/news/96973/96973/96973-640.jpg)
![Apple Debuts Official Trailer for 'Murderbot' [Video]](https://www.iclarified.com/images/news/96972/96972/96972-640.jpg)
![Alleged Case for Rumored iPhone 17 Pro Surfaces Online [Image]](https://www.iclarified.com/images/news/96969/96969/96969-640.jpg)



















































































































OSD700: Stage 4
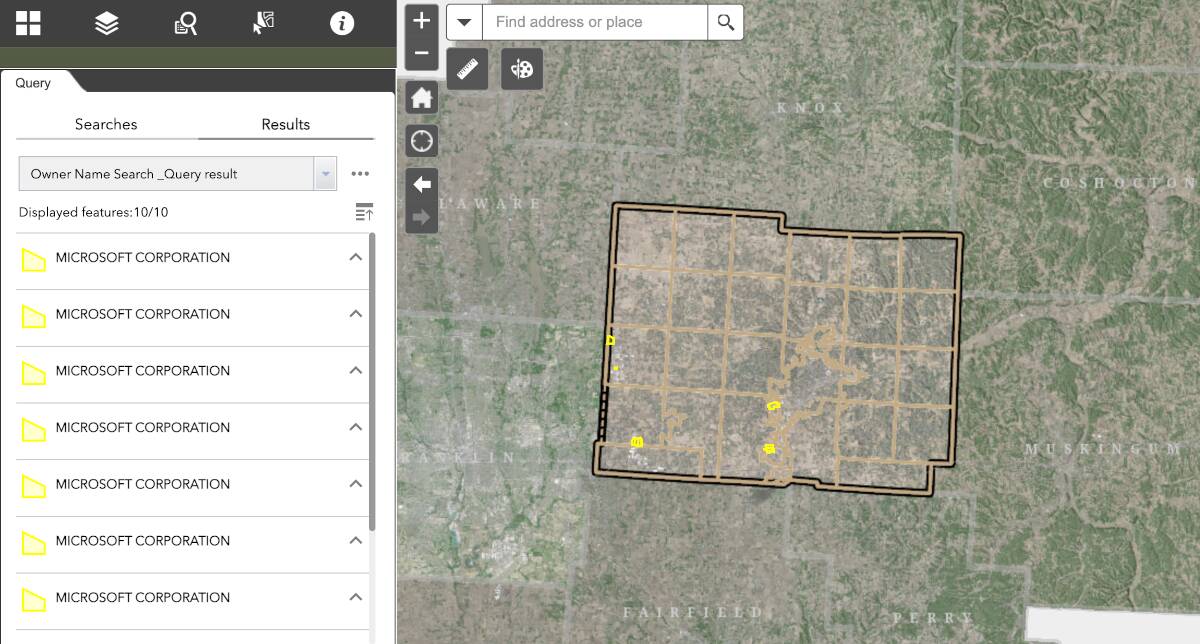
Introduction In last week's lecture, the professor helped me pick the work to do for the rest of this term. My main goal was to minimize front-end development and gain experience in back-end or middle-end. However, it doesn't mean that I won't work on UI/UX, it means that I will work in killer feature development. Therefore, we came up with an idea to develop a RAG on DuckDB. What's RAG? "Retrieval-Augmented Generation (RAG) is a hybrid AI framework that enhances language model outputs by combining the model's inherent knowledge with information retrieved from external sources. When a query is received, RAG first searches through connected databases, documents, or knowledge bases to find relevant information, then feeds this retrieved context alongside the original query into the language model. This approach addresses several limitations of standalone language models by providing access to up-to-date information beyond the model's training cutoff, reducing hallucinations by grounding responses in verified sources, enabling attribution to specific documents, and allowing for domain specialization without extensive model fine-tuning. RAG has become fundamental in enterprise AI applications, search engines, and customer support systems where factual accuracy and current information are essential." - Claude AI The rag will help ChatCraft search through the text files and give an answer based on the user's prompt. There is a filed issue that describes everything: Prototype RAG on DuckDB and File Attachments #803 humphd posted on Jan 27, 2025 ChatCraft has been expanded to include File Attachments and DuckDB, which supports querying files. The two features have been connected, so you can attach files, run SQL queries on them, get back results, download them, etc. Now that we have this foundation, I think we have most of what we need for building a RAG solution, when file attachments are too large to put into the chat context. I think the process would work like this: user attaches some files with text we can extract (PDF, source code, Word Doc, etc) somehow (UI? automatically based on file size) we decide when use these file attachments for RAG vs. embedding directly in the chat messages we take the set of RAG-attachment-files and "index" them in DuckDB. Maybe we use full-text search or maybe we use vector search (see part 1, part 2) when the user asks a question, we use their prompt to create a query, get back results from the indexed docs, and include relevant text context along with the original prompt The initial version of this can be crude, without proper UI, optimal indexing, etc. We need to play a bit to get this right. Likely, the best way to begin this work is to prototype it outside of ChatCraft using DuckDB and text files locally. View on GitHub What Have I Done? I started working toward prototype implementation. It took me a while to research how everything works, and the first small steps were taken, but I consider my local prototype a super raw version. Using langchain, openai and duckdb, I am working on the local version of this new feature before I start web implementation and eventually, implementing it in ChatCraft! It will take some time, but I am really motivated to finish it, and present. Conclusion This is a small blog post since I spent a week on research and a small part of the implementation. However, next week, I will write a huge blog post on how to implement RAG on the Duckdb prototype locally. Will see y'all!
Introduction
In last week's lecture, the professor helped me pick the work to do for the rest of this term. My main goal was to minimize front-end development and gain experience in back-end or middle-end. However, it doesn't mean that I won't work on UI/UX, it means that I will work in killer feature development.
Therefore, we came up with an idea to develop a RAG on DuckDB.
What's RAG?
"Retrieval-Augmented Generation (RAG) is a hybrid AI framework that enhances language model outputs by combining the model's inherent knowledge with information retrieved from external sources. When a query is received, RAG first searches through connected databases, documents, or knowledge bases to find relevant information, then feeds this retrieved context alongside the original query into the language model. This approach addresses several limitations of standalone language models by providing access to up-to-date information beyond the model's training cutoff, reducing hallucinations by grounding responses in verified sources, enabling attribution to specific documents, and allowing for domain specialization without extensive model fine-tuning. RAG has become fundamental in enterprise AI applications, search engines, and customer support systems where factual accuracy and current information are essential." - Claude AI
The rag will help ChatCraft search through the text files and give an answer based on the user's prompt. There is a filed issue that describes everything:
 Prototype RAG on DuckDB and File Attachments
#803
Prototype RAG on DuckDB and File Attachments
#803
ChatCraft has been expanded to include File Attachments and DuckDB, which supports querying files. The two features have been connected, so you can attach files, run SQL queries on them, get back results, download them, etc.
Now that we have this foundation, I think we have most of what we need for building a RAG solution, when file attachments are too large to put into the chat context.
I think the process would work like this:
- user attaches some files with text we can extract (PDF, source code, Word Doc, etc)
- somehow (UI? automatically based on file size) we decide when use these file attachments for RAG vs. embedding directly in the chat messages
- we take the set of RAG-attachment-files and "index" them in DuckDB. Maybe we use full-text search or maybe we use vector search (see part 1, part 2)
- when the user asks a question, we use their prompt to create a query, get back results from the indexed docs, and include relevant text context along with the original prompt
The initial version of this can be crude, without proper UI, optimal indexing, etc. We need to play a bit to get this right.
Likely, the best way to begin this work is to prototype it outside of ChatCraft using DuckDB and text files locally.
What Have I Done?
I started working toward prototype implementation. It took me a while to research how everything works, and the first small steps were taken, but I consider my local prototype a super raw version.
Using langchain, openai and duckdb, I am working on the local version of this new feature before I start web implementation and eventually, implementing it in ChatCraft! It will take some time, but I am really motivated to finish it, and present.
Conclusion
This is a small blog post since I spent a week on research and a small part of the implementation. However, next week, I will write a huge blog post on how to implement RAG on the Duckdb prototype locally. Will see y'all!



