









































































































































































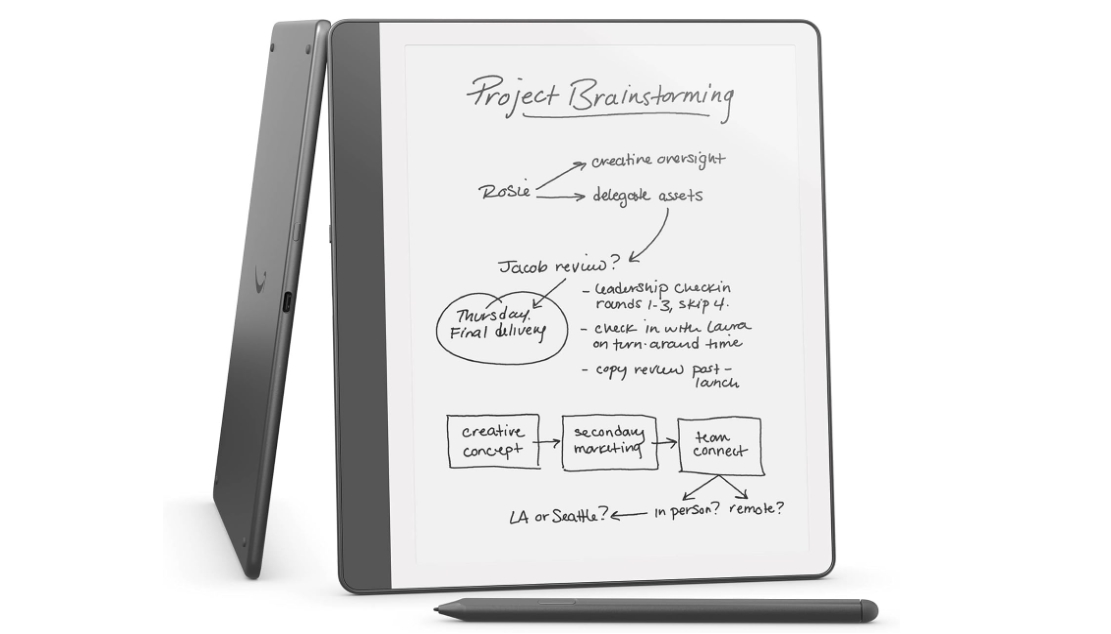
![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)














































































































































































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)
























































.jpg?#)































_Alexey_Kotelnikov_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_Brian_Jackson_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)

_Steven_Jones_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


 Stolen 884,000 Credit Card Details on 13 Million Clicks from Users Worldwide.webp?#)




















































































![Roku clarifies how ‘Pause Ads’ work amid issues with some HDR content [U]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/05/roku-pause-ad-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)
![Look at this Chrome Dino figure and its adorable tiny boombox [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/05/chrome-dino-youtube-boombox-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)










![Apple Seeds visionOS 2.5 RC to Developers [Download]](https://www.iclarified.com/images/news/97240/97240/97240-640.jpg)
![Apple Seeds tvOS 18.5 RC to Developers [Download]](https://www.iclarified.com/images/news/97243/97243/97243-640.jpg)

![Apple Releases macOS Sequoia 15.5 RC to Developers [Download]](https://www.iclarified.com/images/news/97245/97245/97245-640.jpg)





























































































LLM 훈련/추론 시 총 메모리 크기는?
국내 기업들을 방문해서 AI 인프라 관련 분들을 만나면, 가장 많이 물어보는 질문들 중 하나가 LLM 추론 시 메모리 크기는 얼마나 되는 것인 가이다. 아무래도내부에 가진 서버를 그대로 사용할 것인가? 아니면 신규로 서버를 구매할 것인가?에 대해 LLM을 동작 시킬 때 총 메모리 용량이 얼마나 되는 지 궁금해서 일 것이다. 예를 들어, meta-llama/Meta-Llama-3-8B-Instruct에서 훈련(Training) 또는 추론(Inference)할 때, Tensor Type으로 BF16 이면 메모리 크기는 얼마이며, 몇 장의 GPU를 사용해야 하는가에 대해 묻는다면, 어떻게 답변을 해야 하는지 알아 볼 것이다 1. Meta-Llama-3-8B-Instruct에서 훈련 시 메모리 크기 및 GPU 장수는? 메모리 사용량 개략적 계산 = (모델 파라미터 * 2) + 파라미터의 2 - 3배 BF16(bfloat16)은 FP16과 마찬가지로 16비트 정밀도를 사용하므로, 기본적으로 모델 파라미터*자체가 차지하는 메모리는 FP16 대비 큰 차이가 없음. AdamW 와 같은 옵티마이저 상태나 그래디언트, 중간 활성화 (activations) 등으로 인해 실제 요구되는 메모리는 2~3배 가량 될 수 있음. 계산식: (16 * 2) + (16GB * 2 or 16GB * 3) = 32GB + (32 or 48 )GB = 64 or 80 GB BF16 타입으로 풀 파인튜닝(Full fine-tuning)시 단일 GPU으로는 최소 40GB 이상, 안정적인 배치 크기 확보를 위해서는 A100/H100 80GB급이 1장이 권장 80GB H100 1장으로 분산 학습을 활용해도 충분히 학습이 가능함. 2. Meta-Llama-3-8B-Instruct에서 추론 시 메모리 크기 및 GPU 장수는? 메모리 사용량 모델 파라미터 매개변수(Parameter) 수: 약 80억(8B) BF16(2바이트)로 저장 시: 8 Billion × 2 Bytes≈16 GB 추가 메모리(오버헤드) 추론 시 활성화(Activation)와 캐시(cache) 등이 필요하지만, 학습보다는 훨씬 적은 양의 메모리를 사용함. 프롬프트 길이(문맥 길이), 배치 크기에 따라 달라지나, 일반적으로 수GB 정도의 여유가 필요함. 보통 안전하게 20GB 전후의 GPU 메모리가 권장. AdamW 와 같은 옵티마이저 상태나 그래디언트, 중간 활성화 (activations) 등으로 인해 실제 요구되는 메모리는 2~3배 가량 될 수 있음. 단일 GPU에서 BF16 추론을 원활하게 수행하려면, 대략 20GB 이상의 VRAM을 갖춘 GPU가 필요함. 예: 24GB급(예: RTX 3090, RTX 4090, A6000) 이상이면 단일 GPU로 충분히 가능 만약 16GB급 GPU에서 시도한다면, 컨텍스트 길이나 동시 추론(batch) 크기를 작게 조정하거나, 8비트/4비트 양자화(quantization) 같은 기법을 추가로 활용해야 할 수 있음. 권장 GPU 수 1장으로도 충분히 추론이 가능하지만, 여러 배치 요청이나 긴 시퀀스, 다양한 파이프라인 처리를 동시에 해야 한다면, 여러 장의 GPU를 사용하는 멀티 GPU 환경(예: 데이터 병렬)을 구성할 수 있음. 결론 보통은 8B급 모델에서는 성능(처리 속도)을 높이기 위해서 여러 장을 쓰기보다는 단일 고용량 GPU(예: 24GB+) 한 장을 사용하는 경우가 많음. 3. 필요 구성 요소 BF16 지원 GPU 모델 파라미터 Ampere 아키텍처(A100, RTX 3090, RTX 4090 등) 또는 Hopper(H100), Ada Lovelace(RTX 6000 Ada) 계열 이상 권장 구형 GPU(V100, T4 등)는 BF16 지원이 제한적이거나 성능이 떨어질 수 있음 추론 프레임워크 및 라이브러리 PyTorch(최신 버전), Transformers(Hugging Face) 모델 로딩 시 torch.bfloat16 또는 auto_dtype="bf16" 형태로 설정하여 BF16 추론 활성화 소프트웨어/환경 설정 CUDA와 PyTorch 버전이 해당 GPU와 호환되어야 함 BF16 연산을 지원하도록 프레임워크 및 드라이버 세팅 필요 가능하다면 Docker 또는 Conda 환경을 통해 의존성 버전 고정 및 재현성 확보 모델 파일 meta-llama/Meta-Llama-3-8B-Instruct 모델 가중치(Weights) 모델 아키텍처를 불러오고 BF16 모드로 변환할 수 있는 스크립트(Transformers 예시 등) 4. 정리 메모리: BF16 상태에서 모델 자체가 약 16GB, 추가 오버헤드 감안 시 20GB 이상 권장 GPU 수: 단일 24GB급 GPU 1장으로도 추론이 가능함 필요 요소: BF16 연산이 가능한 Ampere급 이상 GPU PyTorch, Transformers 등 BF16 지원 라이브러리 CUDA/드라이버 호환 환경 meta-llama/Meta-Llama-3-8B-Instruct 모델 가중치 및 로딩 스크립트

국내 기업들을 방문해서 AI 인프라 관련 분들을 만나면, 가장 많이 물어보는 질문들 중 하나가 LLM 추론 시 메모리 크기는 얼마나 되는 것인 가이다. 아무래도내부에 가진 서버를 그대로 사용할 것인가? 아니면 신규로 서버를 구매할 것인가?에 대해 LLM을 동작 시킬 때 총 메모리 용량이 얼마나 되는 지 궁금해서 일 것이다.
예를 들어, meta-llama/Meta-Llama-3-8B-Instruct에서 훈련(Training) 또는 추론(Inference)할 때, Tensor Type으로 BF16 이면 메모리 크기는 얼마이며, 몇 장의 GPU를 사용해야 하는가에 대해 묻는다면, 어떻게 답변을 해야 하는지 알아 볼 것이다
1. Meta-Llama-3-8B-Instruct에서 훈련 시 메모리 크기 및 GPU 장수는?
-
메모리 사용량 개략적 계산 = (모델 파라미터 * 2) + 파라미터의 2 - 3배
- BF16(bfloat16)은 FP16과 마찬가지로 16비트 정밀도를 사용하므로, 기본적으로 모델 파라미터*자체가 차지하는 메모리는 FP16 대비 큰 차이가 없음.
- AdamW 와 같은 옵티마이저 상태나 그래디언트, 중간 활성화 (activations) 등으로 인해 실제 요구되는 메모리는 2~3배 가량 될 수 있음.
- 계산식: (16 * 2) + (16GB * 2 or 16GB * 3) = 32GB + (32 or 48 )GB = 64 or 80 GB
- BF16 타입으로 풀 파인튜닝(Full fine-tuning)시
- 단일 GPU으로는 최소 40GB 이상, 안정적인 배치 크기 확보를 위해서는 A100/H100 80GB급이 1장이 권장
- 80GB H100 1장으로 분산 학습을 활용해도 충분히 학습이 가능함.
2. Meta-Llama-3-8B-Instruct에서 추론 시 메모리 크기 및 GPU 장수는?
-
메모리 사용량
- 모델 파라미터
- 매개변수(Parameter) 수: 약 80억(8B)
- BF16(2바이트)로 저장 시: 8 Billion × 2 Bytes≈16 GB
- 추가 메모리(오버헤드)
- 추론 시 활성화(Activation)와 캐시(cache) 등이 필요하지만, 학습보다는 훨씬 적은 양의 메모리를 사용함.
- 프롬프트 길이(문맥 길이), 배치 크기에 따라 달라지나, 일반적으로 수GB 정도의 여유가 필요함. 보통 안전하게 20GB 전후의 GPU 메모리가 권장.
- AdamW 와 같은 옵티마이저 상태나 그래디언트, 중간 활성화 (activations) 등으로 인해 실제 요구되는 메모리는 2~3배 가량 될 수 있음.
- 단일 GPU에서 BF16 추론을 원활하게 수행하려면, 대략 20GB 이상의 VRAM을 갖춘 GPU가 필요함.
- 예: 24GB급(예: RTX 3090, RTX 4090, A6000) 이상이면 단일 GPU로 충분히 가능
- 만약 16GB급 GPU에서 시도한다면,
- 컨텍스트 길이나 동시 추론(batch) 크기를 작게 조정하거나,
- 8비트/4비트 양자화(quantization) 같은 기법을 추가로 활용해야 할 수 있음.
-
권장 GPU 수
- 1장으로도 충분히 추론이 가능하지만,
- 여러 배치 요청이나 긴 시퀀스, 다양한 파이프라인 처리를 동시에 해야 한다면, 여러 장의 GPU를 사용하는 멀티 GPU 환경(예: 데이터 병렬)을 구성할 수 있음.
-
결론
- 보통은 8B급 모델에서는 성능(처리 속도)을 높이기 위해서 여러 장을 쓰기보다는 단일 고용량 GPU(예: 24GB+) 한 장을 사용하는 경우가 많음.
3. 필요 구성 요소
-
BF16 지원 GPU
- 모델 파라미터
- Ampere 아키텍처(A100, RTX 3090, RTX 4090 등) 또는 Hopper(H100), Ada Lovelace(RTX 6000 Ada) 계열 이상 권장
- 구형 GPU(V100, T4 등)는 BF16 지원이 제한적이거나 성능이 떨어질 수 있음
-
추론 프레임워크 및 라이브러리
- PyTorch(최신 버전), Transformers(Hugging Face)
- 모델 로딩 시 torch.bfloat16 또는 auto_dtype="bf16" 형태로 설정하여 BF16 추론 활성화
-
소프트웨어/환경 설정
- CUDA와 PyTorch 버전이 해당 GPU와 호환되어야 함
- BF16 연산을 지원하도록 프레임워크 및 드라이버 세팅 필요
- 가능하다면 Docker 또는 Conda 환경을 통해 의존성 버전 고정 및 재현성 확보
-
모델 파일
- meta-llama/Meta-Llama-3-8B-Instruct 모델 가중치(Weights)
- 모델 아키텍처를 불러오고 BF16 모드로 변환할 수 있는 스크립트(Transformers 예시 등)
4. 정리
- 메모리: BF16 상태에서 모델 자체가 약 16GB, 추가 오버헤드 감안 시 20GB 이상 권장
- GPU 수: 단일 24GB급 GPU 1장으로도 추론이 가능함
-
필요 요소:
- BF16 연산이 가능한 Ampere급 이상 GPU
- PyTorch, Transformers 등 BF16 지원 라이브러리
- CUDA/드라이버 호환 환경
- meta-llama/Meta-Llama-3-8B-Instruct 모델 가중치 및 로딩 스크립트


