

















































































































































































![[The AI Show Episode 148]: Microsoft’s Quiet AI Layoffs, US Copyright Office’s Bombshell AI Guidance, 2025 State of Marketing AI Report, and OpenAI Codex](https://www.marketingaiinstitute.com/hubfs/ep%20148%20cover%20%281%29.png)


![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)

























































































































![Laid off but not afraid with X-senior Microsoft Dev MacKevin Fey [Podcast #173]](https://cdn.hashnode.com/res/hashnode/image/upload/v1747965474270/ae29dc33-4231-47b2-afd1-689b3785fb79.png?#)

































































































![Borderlands 4 Boss Says 'A Real Fan' Will Pay $80 For Games [Update]](https://i.kinja-img.com/image/upload/c_fill,h_675,pg_1,q_80,w_1200/086e4654c281e40d12b833591d2c6fdc.jpg)










































_Olekcii_Mach_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)





























































































![Nomad levels up its best-selling charger with new 100W slim adapter [Hands-on]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/05/100w-FI.jpg.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)



![Google just showed off Android Auto’s upcoming light theme [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/05/android-auto-light-theme-documentation-2.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)











![Apple Accelerates Smart Glasses for 2026, Cancels Watch With Camera [Report]](https://www.iclarified.com/images/news/97408/97408/97408-640.jpg)
![Jony Ive and OpenAI Working on AI Device With No Screen [Kuo]](https://www.iclarified.com/images/news/97401/97401/97401-640.jpg)

![Anthropic Unveils Claude 4 Models That Could Power Apple Xcode AI Assistant [Video]](https://www.iclarified.com/images/news/97407/97407/97407-640.jpg)


























































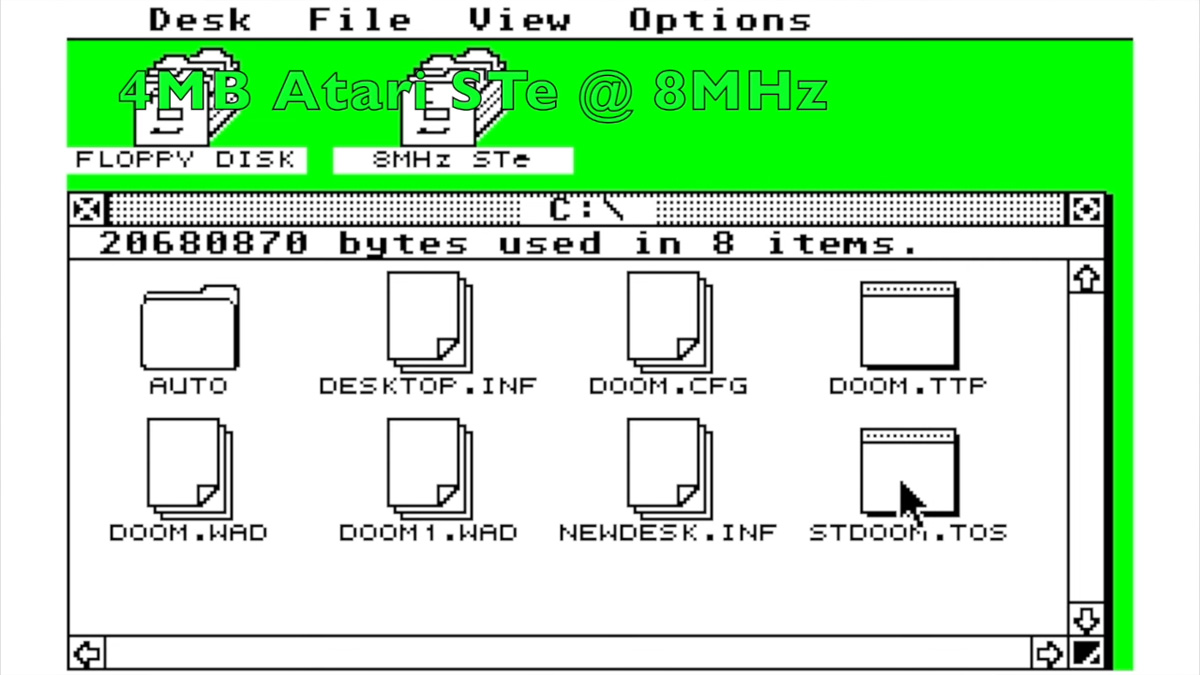
How I Learned Generative AI in Two Weeks (and You Can Too): Part 3 - Prompts & Models
Introduction It's been a few months since the last iteration in this series, but new year, more LLMWare Fast Start to RAG examples! In the previous articles, we covered creating libraries and transforming this information into embeddings. Now that we have done the heavy lifting, so to speak, we are ready to begin writing prompts and getting responses. This will be the focus of today's article. Extra resources A few notes before we start! In case you missed them, I will link the previous articles in this series. This example will build upon example 1 and example 2 and will assume prior understanding of these topics. For visual learners, here is a video that works through example 3. Feel free to watch the video before following the steps in this article. Also, here is a Python Notebook that breaks down this example's code alongside the output. Notebook for example 3: prompts and models The code Now, we are ready to take a look at the example's code! This LLMWare Faststart example can be run in the same way as the previous ones, but instructions can be found in our README file if needed. Example 3 is directly copy-paste ready! Code for example 3: prompts and models Part 1 - What are prompts? While working through this example, I read a MIT Sloan Teaching & Learning Technologies article titled "Effective Prompts for AI: The Essentials". The entire article is definitely worth a read, but I wanted to share a quote that summarizes what prompts are in the AI world. To read the whole article, check out this link. Prompts are your input into the AI system to obtain specific results. In other words, prompts are conversation starters: what and how you tell something to the AI for it to respond in a way that generates useful responses for you ... It’s like having a conversation with another person, only in this case the conversation is text-based, and your interlocutor is AI. In other words, the prompt you provide determines how the AI responds. To create the most effective prompts, use specific wording and consider providing context, including in the form of additional text paragraphs. Part 2 - Which model should I use? The model catalog is a list of all the models LLMWare has registered. Like a dictionary, each model in the catalog is automatically linked with configuration data and implementation classes for easy use. The goal of this catalog is exactly this: ease of use. When provided with only the model's name, if it is present in the catalog, it should be able to run without any other information. The following lines of code provide lists of models included in the catalog. More information about the capabilities and performances of these models is included as comments in the Python code file. # all generative models llm_models = ModelCatalog().list_generative_models() # if you only want to see the local models llm_local_models = ModelCatalog().list_generative_local_models() # to see only the open source models llm_open_source_models = ModelCatalog().list_open_source_models() The following line of code selections a model by index. To choose a different model, simply replace the index value. model_name = gguf_generative_models[0] Alternatively, we can choose a specific model by name. For those interested in exploring RAG through OpenAI, all of the LLMWare examples are ready to use. In this particular example, uncomment the following lines and insert the necessary information. # model_name = "gpt-4" # os.environ["USER_MANAGED_OPENAI_API_KEY"] = "" However, these examples also encourage the use of open-source, models. These are locally deployed models that produce top-notch quality right on your laptop. The developments in regards to open-source over the past few years cannot be overstated. The future of AI is here in these small, specialized models optimized for a specific purpose. For example, the LLMWare Bling 1B is a small, fast model fine-tuned to RAG that runs on your local machine. To learn more about LLMWare's Bling and Dragon models, consider visiting their Hugging Face page! Part 3 - Main example script Now, we can head to the main example script, fast_start_prompting. We will follow four general steps: Pull sample questions Load the model Prompt the model Get results The sample questions (each with query, answer, and context) are found at the top of the Python file. They cover a variety of fields with a little extra emphasis on business, financial, and legal applications. However, it is always encouraged to change these questions or add to them to better suit your interests and needs! All of the questions will be pulled in through the test_list. To use the model, we create a prompt object. Prompts are what we do to a model: we use them when we have a question in context and want to pass it to the model to receive a response. This line of code loads the model: prompte

Introduction
It's been a few months since the last iteration in this series, but new year, more LLMWare Fast Start to RAG examples! In the previous articles, we covered creating libraries and transforming this information into embeddings. Now that we have done the heavy lifting, so to speak, we are ready to begin writing prompts and getting responses. This will be the focus of today's article.
Extra resources
A few notes before we start! In case you missed them, I will link the previous articles in this series. This example will build upon example 1 and example 2 and will assume prior understanding of these topics.
For visual learners, here is a video that works through example 3. Feel free to watch the video before following the steps in this article. Also, here is a Python Notebook that breaks down this example's code alongside the output.
Notebook for example 3: prompts and models
The code
Now, we are ready to take a look at the example's code! This LLMWare Faststart example can be run in the same way as the previous ones, but instructions can be found in our README file if needed. Example 3 is directly copy-paste ready!
Code for example 3: prompts and models
Part 1 - What are prompts?
While working through this example, I read a MIT Sloan Teaching & Learning Technologies article titled "Effective Prompts for AI: The Essentials". The entire article is definitely worth a read, but I wanted to share a quote that summarizes what prompts are in the AI world. To read the whole article, check out this link.
Prompts are your input into the AI system to obtain specific results. In other words, prompts are conversation starters: what and how you tell something to the AI for it to respond in a way that generates useful responses for you ... It’s like having a conversation with another person, only in this case the conversation is text-based, and your interlocutor is AI.
In other words, the prompt you provide determines how the AI responds. To create the most effective prompts, use specific wording and consider providing context, including in the form of additional text paragraphs.
Part 2 - Which model should I use?
The model catalog is a list of all the models LLMWare has registered. Like a dictionary, each model in the catalog is automatically linked with configuration data and implementation classes for easy use. The goal of this catalog is exactly this: ease of use. When provided with only the model's name, if it is present in the catalog, it should be able to run without any other information.
The following lines of code provide lists of models included in the catalog. More information about the capabilities and performances of these models is included as comments in the Python code file.
# all generative models
llm_models = ModelCatalog().list_generative_models()
# if you only want to see the local models
llm_local_models = ModelCatalog().list_generative_local_models()
# to see only the open source models
llm_open_source_models = ModelCatalog().list_open_source_models()
The following line of code selections a model by index. To choose a different model, simply replace the index value.
model_name = gguf_generative_models[0]
Alternatively, we can choose a specific model by name. For those interested in exploring RAG through OpenAI, all of the LLMWare examples are ready to use. In this particular example, uncomment the following lines and insert the necessary information.
# model_name = "gpt-4"
# os.environ["USER_MANAGED_OPENAI_API_KEY"] = ""
However, these examples also encourage the use of open-source, models. These are locally deployed models that produce top-notch quality right on your laptop. The developments in regards to open-source over the past few years cannot be overstated. The future of AI is here in these small, specialized models optimized for a specific purpose.
For example, the LLMWare Bling 1B is a small, fast model fine-tuned to RAG that runs on your local machine.
To learn more about LLMWare's Bling and Dragon models, consider visiting their Hugging Face page!
Part 3 - Main example script
Now, we can head to the main example script, fast_start_prompting. We will follow four general steps:
- Pull sample questions
- Load the model
- Prompt the model
- Get results
The sample questions (each with query, answer, and context) are found at the top of the Python file. They cover a variety of fields with a little extra emphasis on business, financial, and legal applications. However, it is always encouraged to change these questions or add to them to better suit your interests and needs! All of the questions will be pulled in through the test_list.
To use the model, we create a prompt object. Prompts are what we do to a model: we use them when we have a question in context and want to pass it to the model to receive a response. This line of code loads the model:
prompter = Prompt().load_model(model_name)
The first time we load the model, it needs to "move" from the LLMWare Hugging Face repository to your local system, which can take a few minutes. However, once that is complete, all the work the model does will happen locally on your computer!
Now, we loop through our list of questions. The key method .prompt_main in the prompt class causes inference on the model. The mandatory parameter for this method is the query. Optionally, context, prompt_name, and temperature can also be passed in.
output = prompter.prompt_main(entries["query"],
context=entries["context"],
prompt_name="default_with_context",
temperature=0.30)
The context is a passage of information we want the model to read before answering the question. This allows us to explain what we want the model to consider in its answer, and it will answer based on the passage.
The prompt catalog supports a range of prompt names. The code uses default_with_context, which tells the model to read the provided context and answer the question.
Adjusting the temperature will change the results of the query. In general, a lower temperature will yield more factual responses directly relating to the context. Higher temperatures are more appropriate when we require a more creative response from the model. For RAG based applications, we set the temperature comparatively low to yield the the most consistency and quality.
The output is a dictionary with two keys: llm_response and usage.

Part 4 - Running the model
Once you run the code, you will see the queries being iterated through and printed out. Each of these print-outs has an LLM Response and a Gold Answer. The LLM Response is the model's response while the Gold Answer is an "answer key" we created that the model does not see. This allows us to quickly compare the two answers and check for the model's accuracy.
The LLM Usage line provides additional information about how the model formulated its response. In particular, you can see the "processing_time" for each query, which showcases the model's speed. Of course, the computer you run the models on will also cause speed to vary - the amount of RAM available is especially impactful for efficiency.
1. Query: What is the total amount of the invoice?
LLM Response: 22,500.00
Gold Answer: $22,500.00
LLM Usage: {'input': 209, 'output': 9, 'total': 218, 'metric': 'tokens', 'processing_time': 2.0669240951538086}
The above output is a sample response. The LLM correctly responded to the query since its response matches the gold answer.
We have successfully received answers to our questions! Congrats on reaching the end of this example. Here is a link to the full working code!
Part 5 - Further exploration
To experiment more with this example, consider changing out the model_name for other models! How does the LLMWare Bling model compare to the LLMWare Dragon model or OpenAI? Will these models generate the same response when provided the same queries and context? Once you try out these questions, let us know what you think!
I hope you enjoyed this example about prompts and models! The next example will be about RAG text query, stay tuned for the article.
Happy coding!

To see more ...
Please join our LLMWare community on discord to learn more about RAG / LLMs and share your thoughts! https://discord.gg/5mx42AGbHm



