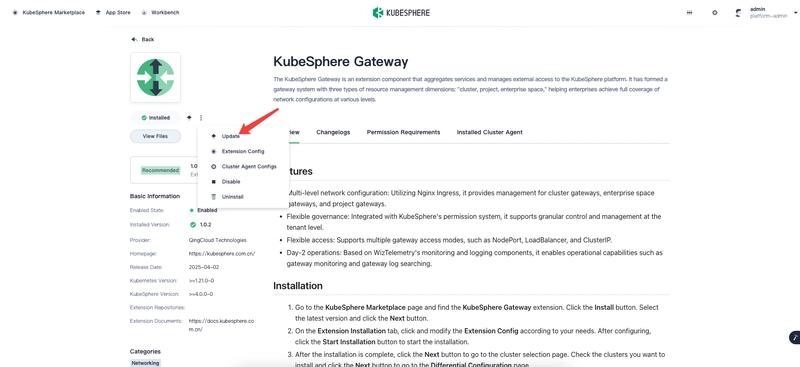








































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)










































































































































































.jpg?#)


































































































_NicoElNino_Alamy.png?width=1280&auto=webp&quality=80&disable=upscale#)






































































































![Apple Shares New Ad for iPhone 16: 'Trust Issues' [Video]](https://www.iclarified.com/images/news/97125/97125/97125-640.jpg)

![At Least Three iPhone 17 Models to Feature 12GB RAM [Kuo]](https://www.iclarified.com/images/news/97122/97122/97122-640.jpg)



























































































































Engineering a Sub‑Microsecond Queue for High‑Frequency Trading
It’s early morning in Mumbai’s trading hub—just as servers hum to life, a red alert flashes across the Latency Dashboard. Our two star-engineers, Chandan and Avinash, dash into the server room. Who will rescue us from a budding performance crisis? Meet the Duo Chandan: The quiet problem-solver. He’s a wizard with atomics, memory ordering, and low-level tricks. Avinash: The big-picture guy. Give him a mutex, and he’ll build an ironclad system with deadlock avoidance and priority inheritance in minutes. 1. The Morning Call A sudden spike in order-processing time sends panic through the desks. The CTO’s voice crackles over the intercom: “We need sub-microsecond response. No excuses.” Chandan and Avinash exchange a glance—this is more than a friendly competition. It’s about the survival of our trading engine. 2. Avinash’s Lock-Based Queue Avinash strides to his workstation like a general to the front lines. He leverages a classic mutex with priority inversion safeguards: const { Mutex } = require('async-mutex'); class LockedQueue { constructor() { this.queue = []; this.mutex = new Mutex(); } async enqueue(item) { const release = await this.mutex.acquire(); try { this.queue.push(item); } finally { release(); } } async dequeue() { const release = await this.mutex.acquire(); try { return this.queue.length ? this.queue.shift() : null; } finally { release(); } } } module.exports = LockedQueue; He glances back at the team. Avinash (grinning): “Watch and learn—deadlock-free, livelock-free, and with priority inheritance it handles the worst of thread storms.” Why it works: Deadlock avoidance via single lock, no nested locking. Priority inheritance prevents high-priority starvation. Why it chokes: Global bottleneck: one lock serializes all producers and consumers. Cache-line bouncing: lock/unlock ping-pongs the cache line, adding hundreds of nanoseconds under contention. Benchmark time. Sixteen threads charge. The fortress groans at 15 M ops/sec—solid, yet far from unbeatable. 3. Chandan’s Lock‑Free Masterpiece Chandan retreats to a quiet corner, headphones on, lights dimmed. He crafts a lock-free, multi‑producer/multi‑consumer ring buffer with memory fences and ABA protection: const BUFFER_SIZE = 1024; class LockFreeQueue { constructor() { this.buffer = new Array(BUFFER_SIZE).fill(null); this.head = new SharedArrayBuffer(4); this.tail = new SharedArrayBuffer(4); this.headView = new Uint32Array(this.head); this.tailView = new Uint32Array(this.tail); } enqueue(item) { while (true) { const tail = Atomics.load(this.tailView, 0); const head = Atomics.load(this.headView, 0); if ((tail + 1) % BUFFER_SIZE === head) continue; // full const nextTail = (tail + 1) % BUFFER_SIZE; if (Atomics.compareExchange(this.tailView, 0, tail, nextTail) === tail) { this.buffer[tail] = item; Atomics.store(this.bufferTicket, tail, tail | 1); // mark valid Atomics.fence(); return; } } } dequeue() { while (true) { const head = Atomics.load(this.headView, 0); const tail = Atomics.load(this.tailView, 0); if (head === tail) return null; // empty const nextHead = (head + 1) % BUFFER_SIZE; if (Atomics.compareExchange(this.headView, 0, head, nextHead) === head) { const item = this.buffer[head]; this.buffer[head] = null; Atomics.fence(); return item; } } } } module.exports = LockFreeQueue; Advanced moves: ABA defense: embed version bits in the index or use tagged pointers. False-sharing shield: pad head/tail counters into separate cache lines. Memory reclamation: add hazard pointers or an epoch-based garbage collector to safely reclaim nodes in unbounded variants. Chandan smirks: Chandan (softly): “No lock can outmuscle a well-ordered set of atomics.” 4. Side‑by‑Side Benchmarks Threads Locked (Avinash) Lock‑Free (Chandan) 1 10 M ops/sec 9 M ops/sec 4 20 M 35 M 8 22 M 60 M 16 15 M 80 M Chandan’s design shines under heavy load—over 5× improvement at 16 threads. In the world of high-frequency trading, every cache line and fence counts. 5. The Rivalry Intensifies Avinash’s rebuttal: “I can add a read‑write lock for batched consumers or a lock striping scheme to split contention across multiple shards.” Chandan’s counter: “Sure—just don’t forget to handle memory ordering across shards, or you’ll reintroduce subtle races.” They push and pull, debating wait‑freedom vs. lock-freedom, exploring bounded vs. unbounded and throughput vs. tail latency. The hall echoes with talk of cache prefetch, NUMA-aware allocation, and vectorized operations. 6. Takeaways Locks are simple, safe, and come with clear correctness models (mutual exclusion, deadlock fr

It’s early morning in Mumbai’s trading hub—just as servers hum to life, a red alert flashes across the Latency Dashboard. Our two star-engineers, Chandan and Avinash, dash into the server room. Who will rescue us from a budding performance crisis?
Meet the Duo
- Chandan: The quiet problem-solver. He’s a wizard with atomics, memory ordering, and low-level tricks.
- Avinash: The big-picture guy. Give him a mutex, and he’ll build an ironclad system with deadlock avoidance and priority inheritance in minutes.
1. The Morning Call
A sudden spike in order-processing time sends panic through the desks. The CTO’s voice crackles over the intercom:
“We need sub-microsecond response. No excuses.”
Chandan and Avinash exchange a glance—this is more than a friendly competition. It’s about the survival of our trading engine.
2. Avinash’s Lock-Based Queue
Avinash strides to his workstation like a general to the front lines. He leverages a classic mutex with priority inversion safeguards:
const { Mutex } = require('async-mutex');
class LockedQueue {
constructor() {
this.queue = [];
this.mutex = new Mutex();
}
async enqueue(item) {
const release = await this.mutex.acquire();
try {
this.queue.push(item);
} finally {
release();
}
}
async dequeue() {
const release = await this.mutex.acquire();
try {
return this.queue.length ? this.queue.shift() : null;
} finally {
release();
}
}
}
module.exports = LockedQueue;
He glances back at the team.
Avinash (grinning): “Watch and learn—deadlock-free, livelock-free, and with priority inheritance it handles the worst of thread storms.”
Why it works:
- Deadlock avoidance via single lock, no nested locking.
- Priority inheritance prevents high-priority starvation.
Why it chokes:
- Global bottleneck: one lock serializes all producers and consumers.
- Cache-line bouncing: lock/unlock ping-pongs the cache line, adding hundreds of nanoseconds under contention.
Benchmark time. Sixteen threads charge. The fortress groans at 15 M ops/sec—solid, yet far from unbeatable.
3. Chandan’s Lock‑Free Masterpiece
Chandan retreats to a quiet corner, headphones on, lights dimmed. He crafts a lock-free, multi‑producer/multi‑consumer ring buffer with memory fences and ABA protection:
const BUFFER_SIZE = 1024;
class LockFreeQueue {
constructor() {
this.buffer = new Array(BUFFER_SIZE).fill(null);
this.head = new SharedArrayBuffer(4);
this.tail = new SharedArrayBuffer(4);
this.headView = new Uint32Array(this.head);
this.tailView = new Uint32Array(this.tail);
}
enqueue(item) {
while (true) {
const tail = Atomics.load(this.tailView, 0);
const head = Atomics.load(this.headView, 0);
if ((tail + 1) % BUFFER_SIZE === head) continue; // full
const nextTail = (tail + 1) % BUFFER_SIZE;
if (Atomics.compareExchange(this.tailView, 0, tail, nextTail) === tail) {
this.buffer[tail] = item;
Atomics.store(this.bufferTicket, tail, tail | 1); // mark valid
Atomics.fence();
return;
}
}
}
dequeue() {
while (true) {
const head = Atomics.load(this.headView, 0);
const tail = Atomics.load(this.tailView, 0);
if (head === tail) return null; // empty
const nextHead = (head + 1) % BUFFER_SIZE;
if (Atomics.compareExchange(this.headView, 0, head, nextHead) === head) {
const item = this.buffer[head];
this.buffer[head] = null;
Atomics.fence();
return item;
}
}
}
}
module.exports = LockFreeQueue;
Advanced moves:
- ABA defense: embed version bits in the index or use tagged pointers.
- False-sharing shield: pad head/tail counters into separate cache lines.
- Memory reclamation: add hazard pointers or an epoch-based garbage collector to safely reclaim nodes in unbounded variants.
Chandan smirks:
Chandan (softly): “No lock can outmuscle a well-ordered set of atomics.”
4. Side‑by‑Side Benchmarks
| Threads | Locked (Avinash) | Lock‑Free (Chandan) |
|---|---|---|
| 1 | 10 M ops/sec | 9 M ops/sec |
| 4 | 20 M | 35 M |
| 8 | 22 M | 60 M |
| 16 | 15 M | 80 M |
Chandan’s design shines under heavy load—over 5× improvement at 16 threads. In the world of high-frequency trading, every cache line and fence counts.
5. The Rivalry Intensifies
- Avinash’s rebuttal: “I can add a read‑write lock for batched consumers or a lock striping scheme to split contention across multiple shards.”
- Chandan’s counter: “Sure—just don’t forget to handle memory ordering across shards, or you’ll reintroduce subtle races.”
They push and pull, debating wait‑freedom vs. lock-freedom, exploring bounded vs. unbounded and throughput vs. tail latency. The hall echoes with talk of cache prefetch, NUMA-aware allocation, and vectorized operations.
6. Takeaways
- Locks are simple, safe, and come with clear correctness models (mutual exclusion, deadlock freedom).
- Lock‑free shines when nanoseconds matter—carefully crafted atomics, memory fences, and hazard pointers can vault performance.
- Always prototype and profile on your target hardware—false sharing, cache thrashing, and branch mispredictions lurk in every corner.
Avinash claps Chandan on the back:
Avinash: “Your atomic wizardry is impressive—next time I’ll bring my own reclaim scheme. Now let’s merge our forces: lock‑free shards with adaptive locking fallbacks.”