![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)




































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)
















































































































(1).jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)






























_NicoElNino_Alamy.png?#)
.webp?#)
.webp?#)
































































































![New iOS 19 Leak Allegedly Reveals Updated Icons, Floating Tab Bar, More [Video]](https://www.iclarified.com/images/news/96958/96958/96958-640.jpg)

![Apple to Source More iPhones From India to Offset China Tariff Costs [Report]](https://www.iclarified.com/images/news/96954/96954/96954-640.jpg)
![Blackmagic Design Unveils DaVinci Resolve 20 With Over 100 New Features and AI Tools [Video]](https://www.iclarified.com/images/news/96951/96951/96951-640.jpg)
























































































































Building an ELT Pipeline with Python and SQL Server: A Netflix Dataset Walkthrough
Hi! In today’s article, we’ll walk through a small ELT project, revisiting each step of the process and diving deep into the details. So, hop on and let’s get started! Extract As always, our first step is to extract or find the data we want to work with. For this project, we’ll be using the Netflix Movies and TV Shows dataset, which you can find on Kaggle. Here’s the link: Netflix Movies and TV Shows Load Now, we move on to the load step, where we import the dataset into a database. For this example, I’m using Microsoft SQL Server running on Windows 11 via SQL Server Management Studio 20. All scripts and code are being executed from Ubuntu 24.04 using WSL. Although everything is running on the same computer, they’re different environments. To connect them, I set up communication through IP which meant opening the necessary ports in SQL Server to allow access from the Ubuntu WSL partition. Then, I created a Python script to load the CSV file (downloaded from Kaggle) into SQL Server. import pandas as pd import sqlalchemy as sal from secret import connection def main(): df = pd.read_csv('./data/netflix_titles.csv') engine = sal.create_engine(connection.get_connection()) conn = engine.connect() df.to_sql('netflix_raw', con=conn, index=False, if_exists='replace') if __name__ == '__main__': main() The connection logic is separated into another Python file where I manage the database credentials and connection string. Once the script is executed, we can check the table created by Python. Here's the schema: CREATE TABLE [dbo].[netflix_raw]( [show_id] [varchar](max) NULL, [type] [varchar](max) NULL, [title] [varchar](max) NULL, [director] [varchar](max) NULL, [cast] [varchar](max) NULL, [country] [varchar](max) NULL, [date_added] [varchar](max) NULL, [release_year] [bigint] NULL, [rating] [varchar](max) NULL, [duration] [varchar](max) NULL, [listed_in] [varchar](max) NULL, [description] [varchar](max) NULL ) As we can see, the initial schema is decent, but we’re allocating more space than necessary in each column by using max lengths. To optimize, we can use a Jupyter Notebook to inspect the actual maximum lengths in each column and adjust accordingly. For example: max (df.show_id.str.len()) After checking all columns, we get a more appropriate schema. For instance: release_year changes from BIGINT to INT since we’re only dealing with year values. title changes from VARCHAR to NVARCHAR this allows us to store foreign-language titles properly. At this point, we can also check for duplicates in the show_id column, since we plan to use it as our PRIMARY KEY. We confirm there are no duplicates, so we can safely assign it as such. Here's the new Schema: [show_id] [varchar](10) NULL, [type] [varchar](10) NULL, [title] [nvarchar](200) NULL, [director] [varchar](250) NULL, [cast] [varchar](1000) NULL, [country] [varchar](150) NULL, [date_added] [varchar](20) NULL, [release_year] [int] NULL, [rating] [varchar](10) NULL, [duration] [varchar](10) NULL, [listed_in] [varchar](100) NULL, [description] [varchar](500) NULL After that, we: Drop the table. Recreate it with the updated schema. Update our Python script to change the if_exists parameter to 'append'. def main(): df = pd.read_csv('./data/netflix_titles.csv') engine = sal.create_engine(connection.get_connection()) conn = engine.connect() df.to_sql('netflix_raw', con=conn, index=False, if_exists='append') if __name__ == '__main__': main() Run the script again. Now we're ready for the next step in our journey. Transform Next comes the transformation step in our ELT pipeline. We start by checking for duplicate records, using the title column. In doing so, we identify a few show_id 's that share the same title. These are the show_id 's: s2639 s8775 s7102 s4915 s5319 s5752 s6706 s304 s5034 s5096 s160 s7346 s8023 s1271 On closer inspection, we notice: Some are TV shows and movies with the same name. Others are remakes or reboots with different casts. A couple are identical entries, with the only difference being the date_added. This is the final show_id with issues: s6706 s304 And s160 s7346 For these cases, we keep the latest version assuming the older entry was removed and later re-added to the platform. We exclude the older versions and re-query the dataset. from dbo.netflix_raw where show_id not in ('s160', 's304'); Next, we analyze columns like listed_in, director, country, and cast. These contain comma-separated lists, which are fine for production storage but not great for analysis. To make them more useful for analytics, we split them into separate tables, creating one row per entry (e.g., one director per row, tied to the corresponding show_id). This is done using SQL queries like: select show_

Hi! In today’s article, we’ll walk through a small ELT project, revisiting each step of the process and diving deep into the details.
So, hop on and let’s get started!
Extract
As always, our first step is to extract or find the data we want to work with. For this project, we’ll be using the Netflix Movies and TV Shows dataset, which you can find on Kaggle.
Here’s the link: Netflix Movies and TV Shows
Load
Now, we move on to the load step, where we import the dataset into a database. For this example, I’m using Microsoft SQL Server running on Windows 11 via SQL Server Management Studio 20. All scripts and code are being executed from Ubuntu 24.04 using WSL.
Although everything is running on the same computer, they’re different environments. To connect them, I set up communication through IP which meant opening the necessary ports in SQL Server to allow access from the Ubuntu WSL partition.
Then, I created a Python script to load the CSV file (downloaded from Kaggle) into SQL Server.
import pandas as pd
import sqlalchemy as sal
from secret import connection
def main():
df = pd.read_csv('./data/netflix_titles.csv')
engine = sal.create_engine(connection.get_connection())
conn = engine.connect()
df.to_sql('netflix_raw', con=conn, index=False, if_exists='replace')
if __name__ == '__main__':
main()
The connection logic is separated into another Python file where I manage the database credentials and connection string.
Once the script is executed, we can check the table created by Python. Here's the schema:
CREATE TABLE [dbo].[netflix_raw](
[show_id] [varchar](max) NULL,
[type] [varchar](max) NULL,
[title] [varchar](max) NULL,
[director] [varchar](max) NULL,
[cast] [varchar](max) NULL,
[country] [varchar](max) NULL,
[date_added] [varchar](max) NULL,
[release_year] [bigint] NULL,
[rating] [varchar](max) NULL,
[duration] [varchar](max) NULL,
[listed_in] [varchar](max) NULL,
[description] [varchar](max) NULL
)
As we can see, the initial schema is decent, but we’re allocating more space than necessary in each column by using max lengths. To optimize, we can use a Jupyter Notebook to inspect the actual maximum lengths in each column and adjust accordingly.
For example:
max (df.show_id.str.len())
After checking all columns, we get a more appropriate schema. For instance:
release_yearchanges fromBIGINTtoINTsince we’re only dealing with year values.titlechanges fromVARCHARtoNVARCHARthis allows us to store foreign-language titles properly.
At this point, we can also check for duplicates in the show_id column, since we plan to use it as our PRIMARY KEY. We confirm there are no duplicates, so we can safely assign it as such.
Here's the new Schema:

[show_id] [varchar](10) NULL,
[type] [varchar](10) NULL,
[title] [nvarchar](200) NULL,
[director] [varchar](250) NULL,
[cast] [varchar](1000) NULL,
[country] [varchar](150) NULL,
[date_added] [varchar](20) NULL,
[release_year] [int] NULL,
[rating] [varchar](10) NULL,
[duration] [varchar](10) NULL,
[listed_in] [varchar](100) NULL,
[description] [varchar](500) NULL
After that, we:
Drop the table.
Recreate it with the updated schema.
Update our Python script to change the
if_existsparameter to'append'.
def main():
df = pd.read_csv('./data/netflix_titles.csv')
engine = sal.create_engine(connection.get_connection())
conn = engine.connect()
df.to_sql('netflix_raw', con=conn, index=False, if_exists='append')
if __name__ == '__main__':
main()
- Run the script again.
Now we're ready for the next step in our journey.
Transform
Next comes the transformation step in our ELT pipeline.
We start by checking for duplicate records, using the title column. In doing so, we identify a few show_id 's that share the same title.
These are the show_id 's:
s2639
s8775
s7102
s4915
s5319
s5752
s6706
s304
s5034
s5096
s160
s7346
s8023
s1271
On closer inspection, we notice:
Some are TV shows and movies with the same name.
Others are remakes or reboots with different casts.
A couple are identical entries, with the only difference being the
date_added.
This is the final show_id with issues:
s6706
s304
And
s160
s7346
For these cases, we keep the latest version assuming the older entry was removed and later re-added to the platform.
We exclude the older versions and re-query the dataset.
from dbo.netflix_raw
where show_id not in ('s160', 's304');
Next, we analyze columns like listed_in, director, country, and cast. These contain comma-separated lists, which are fine for production storage but not great for analysis.
To make them more useful for analytics, we split them into separate tables, creating one row per entry (e.g., one director per row, tied to the corresponding show_id).
This is done using SQL queries like:
select show_id,
trim(value) as genres
into netflix_genres
from dbo.netflix_raw
cross apply string_split(listed_in, ',')
where show_id not in ('s160', 's304');
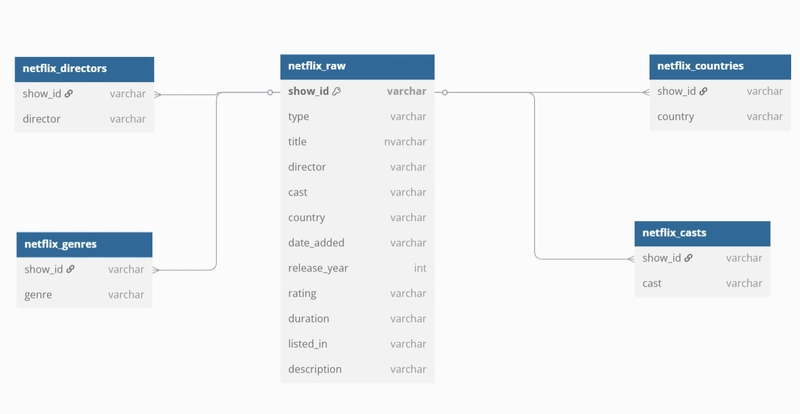
Once done, we’ll have clean relational tables for directors, genres, countries, and casts.
Here's an image of how our Schema is with these changes:
Handling Missing Values
We then check for null values. For example, the country column has several missing entries. There are multiple ways to handle this, depending on:
The time you have.
The source and reliability of the data.
Whether you understand why the data is missing (this is crucial in production).
For this example, let’s try an approximation: if a director has another movie with a known country, we’ll use that to fill in the missing country values.
insert into netflix_countries
select show_id, m.country
from netflix_raw nr
inner join (
select director, country
from dbo.netflix_countries nc
inner join netflix_directors nd on nc.show_id = nd.show_id
group by director, country) m on nr.director = m.director
where nr.country is null;
We also found 3 nulls in the duration column. Interestingly, for show_id 's s5542, s5795, and s5814, the duration value is incorrectly placed in the rating column likely a data formatting issue.
We also notice that the date_added column is stored as a VARCHAR, but we need it as a proper DATE type.
To fix all of this, we:
Create a new intermediate table.
Eliminate columns we already separated into other tables.
Transform
date_addedto a date type.Fix the duration issue.
Remove duplicated entries.
All of this is done with a SQL query like:
select show_id,
type,
title,
cast(date_added as date) as date_added,
release_year,
rating,
case when duration is null
then rating
else duration
end as duration,
description
into netflix_intermediate
from netflix_raw
where show_id not in ('s160', 's304');
With this, we now have a clean, optimized intermediate table, ready for insights and exploratory analysis.
This is the final Schema for now:
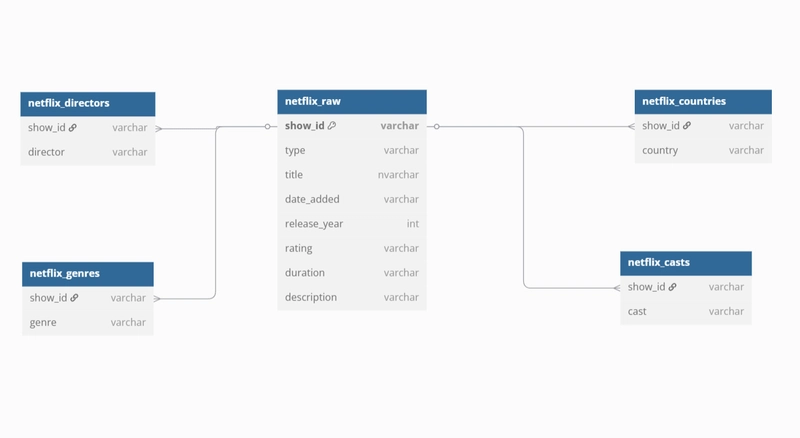
We can go even further, like filling remaining nulls, building dashboards, and running deeper analytics. I’ll cover those in future articles.
Want to try this yourself? Download the dataset and follow along on your own!
Final Thoughts
This was a comprehensive walk-through of an ELT process, from raw data to a clean database schema ready for analytics.
We extracted the data, loaded it into a database, transformed it for analytics, and prepped it for insight generation.
In upcoming posts, I’ll focus on data visualization, insight generation, and maybe even using BI tools to create dashboards from this dataset.
Thanks for reading — stay tuned!
Have questions about this process or want to share your own approach? Drop a comment or reach out. I love talking about data!
In the next part, I’ll show you how to create stunning visualizations and dashboards using this cleaned dataset.
Subscribe or follow me so you don’t miss it!